
האופרטורים של למידת מכונה (ML) שבהם אתם משתמשים במודל יכולים להשפיע על התהליך של המרת מודל TensorFlow לפורמט LiteRT. הכלי להמרת LiteRT תומך במספר מוגבל של פעולות TensorFlow שמשמשות במודלים נפוצים של הסקה, ולכן לא כל מודל ניתן להמרה ישירה. כלי ההמרה מאפשר לכם לכלול אופרטורים נוספים, אבל המרה של מודל בדרך הזו מחייבת גם לשנות את סביבת זמן הריצה של LiteRT שבה אתם משתמשים כדי להריץ את המודל. זה עלול להגביל את היכולת שלכם להשתמש באפשרויות פריסה רגילות של זמן ריצה, כמו Google Play Services.
הכלי LiteRT Converter נועד לנתח את מבנה המודל ולהחיל אופטימיזציות כדי להפוך אותו לתואם לאופרטורים הנתמכים ישירות. לדוגמה, בהתאם לאופרטורים של למידת המכונה במודל, יכול להיות שהכלי להמרה יעלים או ימזג את האופרטורים האלה כדי למפות אותם לאופרטורים המקבילים ב-LiteRT.
גם בפעולות נתמכות, לפעמים נדרשים דפוסי שימוש ספציפיים מסיבות שקשורות לביצועים. הדרך הכי טובה להבין איך לבנות מודל TensorFlow שאפשר להשתמש בו עם LiteRT היא לבחון בקפידה איך הפעולות מומרות ועוברות אופטימיזציה, ומהן המגבלות שמוטלות על התהליך הזה.
אופרטורים נתמכים
אופרטורים מובנים של LiteRT הם קבוצת משנה של האופרטורים שכלולים בספריית הליבה של TensorFlow. יכול להיות שהמודל של TensorFlow יכלול גם אופרטורים מותאמים אישית בצורה של אופרטורים מורכבים או אופרטורים חדשים שהוגדרו על ידכם. בתרשים שלמטה מוצגים הקשרים בין האופרטורים האלה.
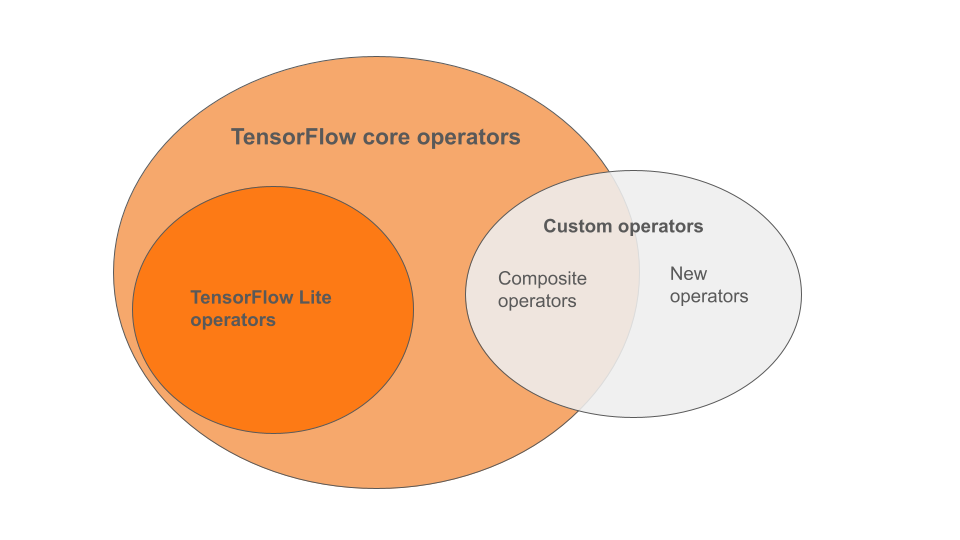
מתוך מגוון האופרטורים של מודלים של למידת מכונה, יש 3 סוגים של מודלים שנתמכים בתהליך ההמרה:
- מודלים עם אופרטור מובנה של LiteRT בלבד. (מומלץ)
- מודלים עם האופרטורים המובנים ובוחרים באופרטורים של TensorFlow core.
- מודלים עם אופרטורים מובנים, אופרטורים של TensorFlow core או אופרטורים מותאמים אישית.
אם המודל מכיל רק פעולות שנתמכות באופן מובנה ב-LiteRT, לא צריך דגלים נוספים כדי להמיר אותו. זו הדרך המומלצת, כי סוג המודל הזה יומר בצורה חלקה וקל יותר לבצע אופטימיזציה שלו ולהריץ אותו באמצעות זמן הריצה של LiteRT שמוגדר כברירת מחדל. יש גם אפשרויות פריסה נוספות למודל, כמו Google Play Services. כדי להתחיל, אפשר לעיין במדריך להמרת LiteRT. בדף LiteRT Ops מופיעה רשימה של אופרטורים מובנים.
אם אתם צריכים לכלול פעולות נבחרות של TensorFlow מהספרייה המרכזית, אתם צריכים לציין את זה בהמרה ולוודא שזמן הריצה כולל את הפעולות האלה. במאמר בחירת אופרטורים של TensorFlow מפורטים השלבים.
ככל האפשר, כדאי להימנע מהאפשרות האחרונה של הכללת אופרטורים מותאמים אישית במודל שהומר. אופרטורים בהתאמה אישית הם אופרטורים שנוצרו משילוב של כמה אופרטורים פרימיטיביים של TensorFlow Core או מהגדרה של אופרטור חדש לגמרי. כשממירים אופרטורים מותאמים אישית, הם יכולים להגדיל את הגודל של המודל הכולל כי הם יוצרים תלות מחוץ לספריית LiteRT המובנית. אם פעולות מותאמות אישית לא נוצרו במיוחד לפריסה בניידים או במכשירים, הן עלולות להניב ביצועים גרועים יותר כשפורסים אותן במכשירים עם מגבלות על המשאבים, בהשוואה לסביבת שרת. לבסוף, כמו במקרה של הכללת אופרטורים נבחרים של TensorFlow core, שימוש באופרטורים בהתאמה אישית מחייב שינוי של סביבת זמן הריצה של המודל, ולכן אי אפשר להשתמש בשירותי זמן ריצה רגילים כמו Google Play.
סוגים נתמכים
רוב הפעולות של LiteRT מטרגטות הסקה של נקודה צפה (float32) ושל כימות (uint8, int8), אבל הרבה פעולות עדיין לא מטרגטות סוגים אחרים כמו tf.float16 ומחרוזות.
בנוסף לשימוש בגרסאות שונות של הפעולות, ההבדל הנוסף בין מודלים של נקודה צפה לבין מודלים שעברו קוונטיזציה הוא אופן ההמרה שלהם. ההמרה לכמתים דורשת מידע על טווח דינמי לטנסורים. כדי לעשות את זה, צריך לבצע 'כמו-קוונטיזציה' במהלך אימון המודל, לקבל מידע על טווח באמצעות מערך נתוני כיול או לבצע הערכת טווח 'בזמן אמת'. פרטים נוספים זמינים במאמר בנושא quantization.
המרות פשוטות, קיפול והיתוך קבועים
מערכת LiteRT יכולה לעבד מספר פעולות של TensorFlow גם אם אין להן מקבילה ישירה. זה המצב בפעולות שאפשר פשוט להסיר מהגרף (tf.identity), להחליף בטנסורים (tf.placeholder) או למזג לפעולות מורכבות יותר (tf.nn.bias_add). לפעמים אפילו פעולות נתמכות מסוימות עשויות להיות מוסרות באמצעות אחד מהתהליכים האלה.
זו רשימה חלקית של פעולות TensorFlow שבדרך כלל מוסרות מהגרף:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
פעולות ניסיוניות
הפעולות הבאות של LiteRT קיימות, אבל לא מוכנות למודלים בהתאמה אישית:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF