
Các toán tử học máy (ML) mà bạn sử dụng trong mô hình có thể ảnh hưởng đến quy trình chuyển đổi mô hình TensorFlow sang định dạng LiteRT. Trình chuyển đổi LiteRT hỗ trợ một số ít các thao tác TensorFlow được dùng trong các mô hình suy luận thông thường. Điều này có nghĩa là không phải mô hình nào cũng có thể chuyển đổi trực tiếp. Công cụ chuyển đổi cho phép bạn thêm các toán tử khác, nhưng việc chuyển đổi mô hình theo cách này cũng yêu cầu bạn sửa đổi môi trường thời gian chạy LiteRT mà bạn dùng để thực thi mô hình. Điều này có thể hạn chế khả năng sử dụng các lựa chọn triển khai thời gian chạy tiêu chuẩn, chẳng hạn như Dịch vụ Google Play.
LiteRT Converter được thiết kế để phân tích cấu trúc mô hình và áp dụng các quy trình tối ưu hoá nhằm giúp mô hình tương thích với các toán tử được hỗ trợ trực tiếp. Ví dụ: tuỳ thuộc vào các toán tử ML trong mô hình của bạn, trình chuyển đổi có thể loại bỏ hoặc hợp nhất những toán tử đó để ánh xạ chúng đến các đối tượng tương ứng trong LiteRT.
Ngay cả đối với các thao tác được hỗ trợ, đôi khi bạn cần phải có các mẫu sử dụng cụ thể vì lý do hiệu suất. Cách tốt nhất để hiểu cách tạo một mô hình TensorFlow có thể dùng với LiteRT là xem xét kỹ cách các thao tác được chuyển đổi và tối ưu hoá, cùng với những hạn chế do quy trình này áp đặt.
Các toán tử được hỗ trợ
Các toán tử tích hợp của LiteRT là một tập hợp con của các toán tử thuộc thư viện lõi TensorFlow. Mô hình TensorFlow của bạn cũng có thể bao gồm các toán tử tuỳ chỉnh dưới dạng toán tử kết hợp hoặc toán tử mới do bạn xác định. Sơ đồ bên dưới cho thấy mối quan hệ giữa các toán tử này.
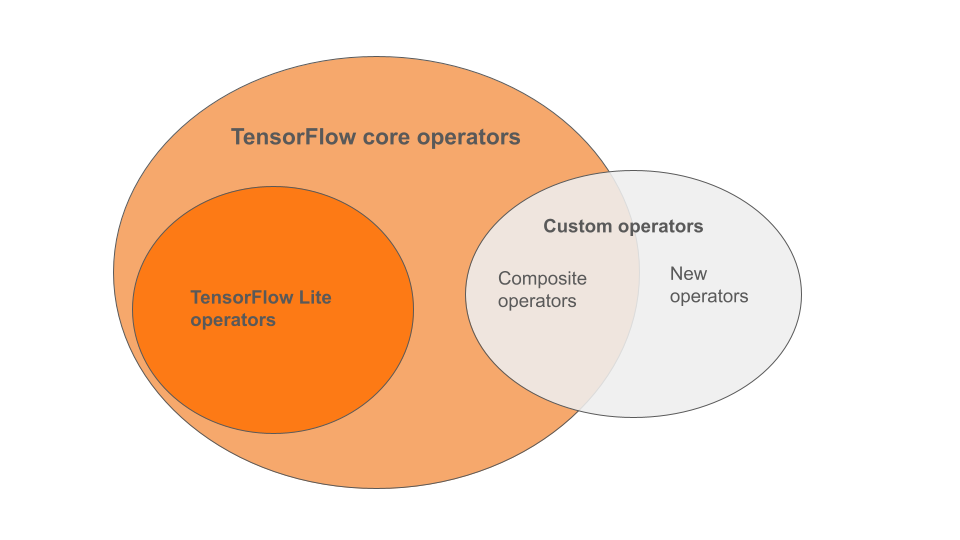
Trong phạm vi các toán tử mô hình học máy này, có 3 loại mô hình được quy trình chuyển đổi hỗ trợ:
- Các mô hình chỉ có toán tử tích hợp LiteRT. (Nên dùng)
- Các mô hình có toán tử tích hợp và chọn toán tử cốt lõi của TensorFlow.
- Các mô hình có toán tử tích hợp, toán tử cốt lõi TensorFlow và/hoặc toán tử tuỳ chỉnh.
Nếu mô hình của bạn chỉ chứa các thao tác được LiteRT hỗ trợ theo mặc định, thì bạn không cần thêm cờ nào để chuyển đổi mô hình đó. Đây là đường dẫn được đề xuất vì loại mô hình này sẽ chuyển đổi một cách mượt mà và dễ dàng tối ưu hoá cũng như chạy bằng thời gian chạy LiteRT mặc định. Bạn cũng có nhiều lựa chọn triển khai hơn cho mô hình của mình, chẳng hạn như Dịch vụ Google Play. Bạn có thể bắt đầu bằng hướng dẫn về bộ chuyển đổi LiteRT. Hãy xem trang LiteRT Ops để biết danh sách các toán tử tích hợp.
Nếu cần đưa các thao tác TensorFlow đã chọn vào thư viện chính, bạn phải chỉ định thao tác đó tại thời điểm chuyển đổi và đảm bảo thời gian chạy của bạn bao gồm các thao tác đó. Hãy xem chủ đề Chọn toán tử TensorFlow để biết các bước chi tiết.
Nếu có thể, hãy tránh lựa chọn cuối cùng là thêm các toán tử tuỳ chỉnh vào mô hình đã chuyển đổi. Toán tử tuỳ chỉnh là toán tử được tạo bằng cách kết hợp nhiều toán tử TensorFlow Core nguyên thuỷ hoặc xác định một toán tử hoàn toàn mới. Khi được chuyển đổi, các toán tử tuỳ chỉnh có thể làm tăng kích thước của mô hình tổng thể bằng cách phát sinh các phần phụ thuộc bên ngoài thư viện LiteRT tích hợp. Các thao tác tuỳ chỉnh, nếu không được tạo riêng cho việc triển khai thiết bị hoặc thiết bị di động, có thể dẫn đến hiệu suất kém hơn khi được triển khai cho các thiết bị bị hạn chế về tài nguyên so với môi trường máy chủ. Cuối cùng, giống như việc thêm các toán tử cốt lõi TensorFlow đã chọn, các toán tử tuỳ chỉnh yêu cầu bạn sửa đổi môi trường thời gian chạy mô hình, điều này hạn chế bạn tận dụng các dịch vụ thời gian chạy tiêu chuẩn như Dịch vụ Google Play.
Các kiểu được hỗ trợ
Hầu hết các hoạt động LiteRT đều nhắm đến cả suy luận dấu phẩy động (float32) và suy luận được lượng tử hoá (uint8, int8), nhưng nhiều hoạt động chưa nhắm đến các loại khác như tf.float16 và chuỗi.
Ngoài việc sử dụng các phiên bản khác nhau của hoạt động, điểm khác biệt khác giữa các mô hình dấu phẩy động và mô hình được lượng tử hoá là cách chúng được chuyển đổi. Quá trình chuyển đổi được lượng tử hoá yêu cầu thông tin dải động cho các tensor. Điều này đòi hỏi phải có "lượng tử hoá giả" trong quá trình huấn luyện mô hình, nhận thông tin về phạm vi thông qua một tập dữ liệu hiệu chuẩn hoặc thực hiện ước tính phạm vi "tức thì". Hãy xem phần lượng tử hoá để biết thêm thông tin chi tiết.
Chuyển đổi đơn giản, gấp và hợp nhất liên tục
LiteRT có thể xử lý một số thao tác TensorFlow ngay cả khi chúng không có thao tác tương đương trực tiếp. Đây là trường hợp đối với các thao tác có thể được xoá khỏi biểu đồ (tf.identity), thay thế bằng các tensor (tf.placeholder) hoặc hợp nhất thành các thao tác phức tạp hơn (tf.nn.bias_add). Thậm chí, đôi khi một số thao tác được hỗ trợ cũng có thể bị xoá thông qua một trong các quy trình này.
Sau đây là danh sách chưa đầy đủ các thao tác TensorFlow thường bị xoá khỏi biểu đồ:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
Hoạt động thử nghiệm
Các thao tác LiteRT sau đây hiện có nhưng chưa sẵn sàng cho các mô hình tuỳ chỉnh:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF