Nano Banana による画像生成
- Nano Banana 2 アプリを試す
- プロンプトから独自のものを構築することもできます。
-








-
Nano Banana 2 で生成 -
Nano Banana Pro で生成 プロンプト: 「ロンドンの最も象徴的なランドマークと建築要素を特徴とする、45 度の真上から見た等角投影のミニチュア 3D 漫画のシーンを明確に表現してください。リアルな PBR マテリアルと、優しくリアルな照明と影を使用して、柔らかく洗練されたテクスチャを使用します。現在の気象条件を都市環境に直接統合して、没入感のある雰囲気を作り出します。柔らかい単色の背景を使用した、すっきりとしたミニマルな構図にします。上部中央に、大きな太字で「ロンドン」というタイトルを配置し、その下に目立つ天気アイコン、日付(小さいテキスト)、気温(中くらいのテキスト)を配置します。すべてのテキストは、一貫した間隔で中央に配置する必要があります。建物の上部とわずかに重なることがあります。」検索グラウンディングの詳細を確認し、AI Studio で試す -
Nano Banana 2 で生成 -

Nano Banana Pro で生成 プロンプト: 「このロゴをバナナの香りの香水の高級広告に配置して。ロゴがボトルに完全に統合されています。」AI Studio で Nano Banana の高忠実度ディテールの保持を試す -
Nano Banana Pro で生成 -
Nano Banana Pro で生成 -
Nano Banana Pro で生成 プロンプト: 「かわいい犬を表すアイコン。背景は白です。アイコンをカラフルで触覚的な 3D スタイルにします。テキストなし。」AI Studio の Nano Banana でアイコン、ステッカー、アセットを作成する -
Nano Banana 2 で生成 プロンプト: 「完全にアイソメトリックな写真を作成して。ミニチュアではなく、たまたま完璧なアイソメトリックで撮影された写真です。美しいモダンな庭の写真です。大きな 2 の形をしたプールと「Nano Banana 2」という文字があります。」
Nano Banana は、Gemini のネイティブ画像生成機能の名称です。Gemini は、テキスト、画像、動画、またはその組み合わせを使用して、会話形式で画像を生成して処理できます。これにより、これまでにない高いコントロール精度で画像を作成、編集、反復的な改善ができます。
Nano Banana は、Gemini API で利用できる 3 つの異なるモデルを指します。
- Nano Banana 2: Gemini 3.1 Flash Image モデル(
gemini-3.1-flash-image)。このモデルは、Gemini 3 Pro Image の高効率な対応モデルとして機能し、速度と大量のデベロッパー ユースケース向けに最適化されています。 - Nano Banana Pro: Gemini 3 Pro Image モデル(
gemini-3-pro-image)。このモデルは、高度な推論(「思考」)を利用して複雑な指示に従い、高精細なテキストをレンダリングする、プロフェッショナルなアセット制作向けに設計されています。 - Nano Banana: Gemini 2.5 Flash Image モデル(
gemini-2.5-flash-image)。このモデルは速度と効率性を重視して設計されており、大量の低レイテンシ タスク向けに最適化されています。
生成されたすべての画像には SynthID の透かしが埋め込まれています。
画像生成(テキスト画像変換)
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
prompt = ("Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme")
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=[prompt],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("generated_image.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme";
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "gemini_generated_image.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class TextToImage {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image",
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("_01_generated_image.png"), blob.data().get());
}
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class TextToImage {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme" }
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("generated_image.png", imageBytes);
Console.WriteLine("Image saved as generated_image.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}]
}'
画像編集(テキストと画像による画像変換)
リマインダー: アップロードする画像に必要な権利をすべて所有していることをご確認ください。他者の権利を侵害するコンテンツ(他人を欺く、嫌がらせをする、または危害を加える動画や画像など)を生成しないでください。この生成 AI 機能の使用は、Google の使用禁止に関するポリシーの対象となります。
画像を指定し、テキスト プロンプトを使用して要素の追加、削除、変更、スタイルの変更、カラー グレーディングの調整を行います。
次の例は、base64 エンコードされた画像をアップロードする方法を示しています。複数の画像、大きなペイロード、サポートされている MIME タイプについては、画像理解のページをご覧ください。
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
prompt = (
"Create a picture of my cat eating a nano-banana in a "
"fancy restaurant under the Gemini constellation",
)
image = Image.open("/path/to/cat_image.png")
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=[prompt, image],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("generated_image.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "path/to/cat_image.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ text: "Create a picture of my cat eating a nano-banana in a" +
"fancy restaurant under the Gemini constellation" },
{
inlineData: {
mimeType: "image/png",
data: base64Image,
},
},
];
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
imagePath := "/path/to/cat_image.png"
imgData, _ := os.ReadFile(imagePath)
parts := []*genai.Part{
genai.NewPartFromText("Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation"),
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/png",
Data: imgData,
},
},
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image",
contents,
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "gemini_generated_image.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class TextAndImageToImage {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image",
Content.fromParts(
Part.fromText("""
Create a picture of my cat eating a nano-banana in
a fancy restaurant under the Gemini constellation
"""),
Part.fromBytes(
Files.readAllBytes(
Path.of("src/main/resources/cat.jpg")),
"image/jpeg")),
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("gemini_generated_image.png"), blob.data().get());
}
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class TextAndImageToImage {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation" },
new Part
{
FileData = new FileData { FileUri = "file:///path/to/cat_image.png" }
}
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("gemini_generated_image.png", imageBytes);
Console.WriteLine("Image saved as gemini_generated_image.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{\"text\": \"'Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation\"},
{
\"inline_data\": {
\"mime_type\":\"image/jpeg\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
}
]
}]
}"
マルチターンの画像編集
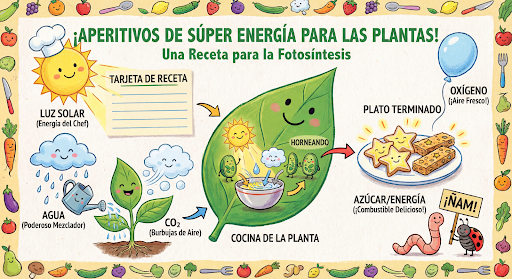
会話形式で画像の生成と編集を続けます。画像に対して反復処理を行うには、チャットまたはマルチターンの会話をおすすめします。次の例は、光合成に関するインフォグラフィックを生成するプロンプトを示しています。
Python
from google import genai
from google.genai import types
client = genai.Client()
chat = client.chats.create(
model="gemini-3.1-flash-image",
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
tools=[{"google_search": {}}]
)
)
message = "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader."
response = chat.send_message(message)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("photosynthesis.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const chat = ai.chats.create({
model: "gemini-3.1-flash-image",
config: {
responseModalities: ['TEXT', 'IMAGE'],
tools: [{googleSearch: {}}],
},
});
}
await main();
const message = "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader."
let response = await chat.sendMessage({message});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("photosynthesis.png", buffer);
console.log("Image saved as photosynthesis.png");
}
}
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
}
chat := model.StartChat()
message := "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader."
resp, err := chat.SendMessage(ctx, genai.Text(message))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("photosynthesis.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Chat;
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.RetrievalConfig;
import com.google.genai.types.Tool;
import com.google.genai.types.ToolConfig;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class MultiturnImageEditing {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.tools(Tool.builder()
.googleSearch(GoogleSearch.builder().build())
.build())
.build();
Chat chat = client.chats.create("gemini-3.1-flash-image", config);
GenerateContentResponse response = chat.sendMessage("""
Create a vibrant infographic that explains photosynthesis
as if it were a recipe for a plant's favorite food.
Show the "ingredients" (sunlight, water, CO2)
and the "finished dish" (sugar/energy).
The style should be like a page from a colorful
kids' cookbook, suitable for a 4th grader.
""");
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("photosynthesis.png"), blob.data().get());
}
}
}
// ...
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class MultiturnImageEditing {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader." }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "TEXT", "IMAGE" },
Tools = new List<Tool> { new Tool { GoogleSearch = new GoogleSearch() } }
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("photosynthesis.png", imageBytes);
Console.WriteLine("Image saved as photosynthesis.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"role": "user",
"parts": [
{"text": "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plants favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids cookbook, suitable for a 4th grader."}
]
}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'

同じチャットを使用して、グラフィックの言語をスペイン語に変更できます。
Python
message = "Update this infographic to be in Spanish. Do not change any other elements of the image."
aspect_ratio = "16:9" # "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
resolution = "2K" # "512", "1K", "2K", "4K"
response = chat.send_message(message,
config=types.GenerateContentConfig(
response_format={"image": {aspect_ratio: aspect_ratio, image_size: resolution}},
))
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("photosynthesis_spanish.png")
JavaScript
const message = 'Update this infographic to be in Spanish. Do not change any other elements of the image.';
const aspectRatio = '16:9';
const resolution = '2K';
let response = await chat.sendMessage({
message,
config: {
responseModalities: ['TEXT', 'IMAGE'],
responseFormat: {
image: {
aspectRatio: aspectRatio,
imageSize: resolution,
}
},
tools: [{googleSearch: {}}],
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("photosynthesis2.png", buffer);
console.log("Image saved as photosynthesis2.png");
}
}
Go
message = "Update this infographic to be in Spanish. Do not change any other elements of the image."
aspect_ratio = "16:9" // "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
resolution = "2K" // "512", "1K", "2K", "4K"
model.GenerationConfig.ImageConfig = &pb.ImageConfig{
AspectRatio: aspect_ratio,
ImageSize: resolution,
}
resp, err = chat.SendMessage(ctx, genai.Text(message))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("photosynthesis_spanish.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
Java
String aspectRatio = "16:9"; // "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
String resolution = "2K"; // "512", "1K", "2K", "4K"
config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio(aspectRatio)
.imageSize(resolution)
.build())
.build();
response = chat.sendMessage(
"Update this infographic to be in Spanish. " +
"Do not change any other elements of the image.",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("photosynthesis_spanish.png"), blob.data().get());
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class MultiturnImageEditingSpanish {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "Update this infographic to be in Spanish. Do not change any other elements of the image." }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "TEXT", "IMAGE" },
ImageConfig = new ImageConfig
{
AspectRatio = "16:9",
ImageSize = "2K"
}
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("photosynthesis_spanish.png", imageBytes);
Console.WriteLine("Image saved as photosynthesis_spanish.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [
{
"role": "user",
"parts": [{"text": "Create a vibrant infographic that explains photosynthesis..."}]
},
{
"role": "model",
"parts": [{"inline_data": {"mime_type": "image/png", "data": "<PREVIOUS_IMAGE_DATA>"}}]
},
{
"role": "user",
"parts": [{"text": "Update this infographic to be in Spanish. Do not change any other elements of the image."}]
}
],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"responseFormat": {
"image": {
"aspectRatio": "16:9",
"imageSize": "2K"
}
}
}
}'
Gemini 3 画像モデルの新機能
Gemini 3 は、最先端の画像生成および編集モデルを提供します。Gemini 3.1 Flash Image は速度と大量のユースケース向けに最適化されており、Gemini 3 Pro Image はプロフェッショナルなアセット制作向けに最適化されています。高度な推論を通じて最も困難なワークフローに取り組むように設計されており、複雑なマルチターンの作成と変更のタスクに優れています。
- 高解像度出力: 1K、2K、4K のビジュアルを生成する機能が組み込まれています。
- Gemini 3.1 Flash Image では、より小さい 512(0.5K)にも対応しています。
- 高度なテキスト レンダリング: インフォグラフィック、メニュー、図表、マーケティング アセット用に、読みやすくスタイリッシュなテキストを生成できます。
- Google 検索によるグラウンディング: モデルは、Google 検索をツールとして使用して、事実を確認し、リアルタイム データ(現在の天気図、株価チャート、最近のイベントなど)に基づいて画像生成できます。
- Gemini 3.1 Flash Image では、画像検索とウェブ検索に加えて、Google 検索によるグラウンディングが統合されています。
- 思考モード: モデルは「思考」プロセスを利用して、複雑なプロンプトを推論します。最終的な高品質の出力を生成する前に、構成を調整するための中間的な「思考画像」(バックエンドで表示されるが、課金されない)を生成します。
- 最大 14 枚の参照画像: 最大 14 枚の参照画像を組み合わせて最終的な画像を生成できるようになりました。
- 新しいアスペクト比: Gemini 3.1 Flash Image に 1:4、4:1、1:8、8:1 のアスペクト比が追加されました。
最大 14 枚の参照画像を使用する
Gemini 3 画像モデルでは、最大 14 個の参照画像を組み合わせることができます。これらの 14 枚の画像には、次のものを含めることができます。
| Gemini 3.1 Flash Image | Gemini 3 Pro Image |
|---|---|
| 最終画像に含める忠実度の高いオブジェクトの画像(最大 10 枚) | 最終画像に含める忠実度の高いオブジェクトの画像(最大 6 枚) |
| キャラクターの一貫性を維持するためのキャラクターの画像(最大 4 枚) | キャラクターの一貫性を維持するためのキャラクターの画像(最大 5 枚) |
| なし | スタイルの参照用として使用する画像(3 枚まで) |
Python
from google import genai
from google.genai import types
from PIL import Image
prompt = "An office group photo of these people, they are making funny faces."
aspect_ratio = "5:4" # "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
resolution = "2K" # "512", "1K", "2K", "4K"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=[
prompt,
Image.open('person1.png'),
Image.open('person2.png'),
Image.open('person3.png'),
Image.open('person4.png'),
Image.open('person5.png'),
],
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
response_format={"image": {aspect_ratio: aspect_ratio, image_size: resolution}},
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("office.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
'An office group photo of these people, they are making funny faces.';
const aspectRatio = '5:4';
const resolution = '2K';
const contents = [
{ text: prompt },
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile1,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile2,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile3,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile4,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile5,
},
}
];
const response = await ai.models.generateContent({
model: 'gemini-3.1-flash-image',
contents: contents,
config: {
responseModalities: ['TEXT', 'IMAGE'],
responseFormat: {
image: {
aspectRatio: aspectRatio,
imageSize: resolution,
}
},
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
ImageConfig: &pb.ImageConfig{
AspectRatio: "5:4",
ImageSize: "2K",
},
}
img1, err := os.ReadFile("person1.png")
if err != nil { log.Fatal(err) }
img2, err := os.ReadFile("person2.png")
if err != nil { log.Fatal(err) }
img3, err := os.ReadFile("person3.png")
if err != nil { log.Fatal(err) }
img4, err := os.ReadFile("person4.png")
if err != nil { log.Fatal(err) }
img5, err := os.ReadFile("person5.png")
if err != nil { log.Fatal(err) }
parts := []genai.Part{
genai.Text("An office group photo of these people, they are making funny faces."),
genai.ImageData{MIMEType: "image/png", Data: img1},
genai.ImageData{MIMEType: "image/png", Data: img2},
genai.ImageData{MIMEType: "image/png", Data: img3},
genai.ImageData{MIMEType: "image/png", Data: img4},
genai.ImageData{MIMEType: "image/png", Data: img5},
}
resp, err := model.GenerateContent(ctx, parts...)
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("office.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class GroupPhoto {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("5:4")
.imageSize("2K")
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image",
Content.fromParts(
Part.fromText("An office group photo of these people, they are making funny faces."),
Part.fromBytes(Files.readAllBytes(Path.of("person1.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person2.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person3.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person4.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person5.png")), "image/png")
), config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("office.png"), blob.data().get());
}
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class GroupPhoto {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "An office group photo of these people, they are making funny faces." },
new Part { FileData = new FileData { FileUri = "file:///person1.png" } },
new Part { FileData = new FileData { FileUri = "file:///person2.png" } },
new Part { FileData = new FileData { FileUri = "file:///person3.png" } },
new Part { FileData = new FileData { FileUri = "file:///person4.png" } },
new Part { FileData = new FileData { FileUri = "file:///person5.png" } }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "TEXT", "IMAGE" },
ImageConfig = new ImageConfig
{
AspectRatio = "5:4",
ImageSize = "2K"
}
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("office.png", imageBytes);
Console.WriteLine("Image saved as office.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{\"text\": \"An office group photo of these people, they are making funny faces.\"},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_1>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_2>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_3>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_4>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_5>\"}}
]
}],
\"generationConfig\": {
\"responseModalities\": [\"TEXT\", \"IMAGE\"],
\"responseFormat\": {
\"image\": {
\"aspectRatio\": \"5:4\",
\"imageSize\": \"2K\"
}
}
}
}"

Google 検索によるグラウンディング
Google 検索ツールを使用して、天気予報、株価チャート、最近の出来事などのリアルタイム情報に基づいて画像を生成します。
画像生成で Google 検索によるグラウンディングを使用する場合、画像ベースの検索結果は生成モデルに渡されず、レスポンスから除外されます(画像に対する Google 検索によるグラウンディングを参照)。
Python
from google import genai
prompt = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"
aspect_ratio = "16:9" # "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['Text', 'Image'],
response_format={"image": {aspect_ratio: aspect_ratio,}},
tools=[{"google_search": {}}]
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("weather.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt = 'Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day';
const aspectRatio = '16:9';
const resolution = '2K';
const response = await ai.models.generateContent({
model: 'gemini-3.1-flash-image',
contents: prompt,
config: {
responseModalities: ['TEXT', 'IMAGE'],
responseFormat: {
image: {
aspectRatio: aspectRatio,
imageSize: resolution,
}
},
tools: [{ googleSearch: {} }]
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.Tool;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class SearchGrounding {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.build())
.tools(Tool.builder()
.googleSearch(GoogleSearch.builder().build())
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image", """
Visualize the current weather forecast for the next 5 days
in San Francisco as a clean, modern weather chart.
Add a visual on what I should wear each day
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("weather.png"), blob.data().get());
}
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class SearchGrounding {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day" }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "TEXT", "IMAGE" },
ImageConfig = new ImageConfig
{
AspectRatio = "16:9"
},
Tools = new List<Tool> { new Tool { GoogleSearch = new GoogleSearch() } }
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("weather.png", imageBytes);
Console.WriteLine("Image saved as weather.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"}]}],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"responseFormat": {
"image": {"aspectRatio": "16:9"}
}
}
}'

レスポンスには、次の必須フィールドを含む groundingMetadata が含まれます。
searchEntryPoint: 必要な検索候補をレンダリングする HTML と CSS が含まれています。groundingChunks: 生成された画像のグラウンディングに使用された上位 3 つのウェブソースを返します
画像検索によるグラウンディング(3.1 Flash)
画像用の Google 検索によるグラウンディングを使用すると、モデルは Google 検索で取得したウェブ画像を画像生成の視覚的コンテキストとして使用できます。画像検索は、既存の Google 検索によるグラウンディング ツール内の新しい検索タイプで、標準のウェブ検索とともに機能します。
画像検索を有効にするには、API リクエストで googleSearch ツールを構成し、searchTypes オブジェクト内で imageSearch を指定します。画像検索は、単独で使用することも、ウェブ検索と組み合わせて使用することもできます。
画像に対する Google 検索でのグラウンディングは、人物の検索には使用できません。
Python
from google import genai
prompt = "A detailed painting of a Timareta butterfly resting on a flower"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
tools=[
types.Tool(google_search=types.GoogleSearch(
search_types=types.SearchTypes(
web_search=types.WebSearch(),
image_search=types.ImageSearch()
)
))
]
)
)
# Display grounding sources if available
if response.candidates and response.candidates[0].grounding_metadata and response.candidates[0].grounding_metadata.search_entry_point:
display(HTML(response.candidates[0].grounding_metadata.search_entry_point.rendered_content))
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const ai = new GoogleGenAI({});
const prompt = "A detailed painting of a Timareta butterfly resting on a flower";
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: prompt,
config: {
responseModalities: ["IMAGE"],
tools: [
{
googleSearch: {
searchTypes: {
webSearch: {},
imageSearch: {}
}
}
}
]
}
});
// Display grounding sources if available
if (response.candidates && response.candidates[0].groundingMetadata && response.candidates[0].groundingMetadata.searchEntryPoint) {
console.log(response.candidates[0].groundingMetadata.searchEntryPoint.renderedContent);
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
pb "google.golang.org/genai/schema"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image")
model.Tools = []*pb.Tool{
{
GoogleSearch: &pb.GoogleSearch{
SearchTypes: &pb.SearchTypes{
WebSearch: &pb.WebSearch{},
ImageSearch: &pb.ImageSearch{},
},
},
},
}
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Image},
}
prompt := "A detailed painting of a Timareta butterfly resting on a flower"
resp, err := model.GenerateContent(ctx, genai.Text(prompt))
if err != nil {
log.Fatal(err)
}
if resp.Candidates[0].GroundingMetadata != nil && resp.Candidates[0].GroundingMetadata.SearchEntryPoint != nil {
fmt.Println(resp.Candidates[0].GroundingMetadata.SearchEntryPoint.RenderedContent)
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageSearch;
import com.google.genai.types.SearchTypes;
import com.google.genai.types.Tool;
import com.google.genai.types.WebSearch;
import java.io.IOException;
public class ImageSearchGrounding {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("IMAGE")
.tools(Tool.builder()
.googleSearch(GoogleSearch.builder()
.searchTypes(SearchTypes.builder()
.webSearch(WebSearch.builder().build())
.imageSearch(ImageSearch.builder().build())
.build())
.build())
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image",
"A detailed painting of a Timareta butterfly resting on a flower",
config);
if (response.candidates().isPresent() && !response.candidates().get().isEmpty()) {
var candidate = response.candidates().get().get(0);
if (candidate.groundingMetadata().isPresent() && candidate.groundingMetadata().get().searchEntryPoint().isPresent()) {
System.out.println(candidate.groundingMetadata().get().searchEntryPoint().get().renderedContent().orElse(""));
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.Threading.Tasks;
public class ImageSearchGrounding {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "A detailed painting of a Timareta butterfly resting on a flower" }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "IMAGE" },
Tools = new List<Tool>
{
new Tool
{
GoogleSearch = new GoogleSearch
{
SearchTypes = new SearchTypes
{
WebSearch = new WebSearch(),
ImageSearch = new ImageSearch()
}
}
}
}
}
);
foreach (var candidate in response.Candidates) {
if (candidate.GroundingMetadata != null && candidate.GroundingMetadata.SearchEntryPoint != null) {
Console.WriteLine(candidate.GroundingMetadata.SearchEntryPoint.RenderedContent);
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "A detailed painting of a Timareta butterfly resting on a flower"}]}],
"tools": [{"google_search": {"searchTypes": {"webSearch": {}, "imageSearch": {}}}}],
"generationConfig": {
"responseModalities": ["IMAGE"]
}
}'
表示の要件
Google 検索によるグラウンディング内で画像検索を使用する場合は、次の条件を遵守する必要があります。
- 出典の帰属: ユーザーがリンクとして認識できる方法で、ソース画像を含むウェブページ(画像ファイル自体ではなく「包含ページ」)へのリンクを提供する必要があります。
- 直接ナビゲーション: ソース画像も表示する場合は、ソース画像からそのソース ウェブページへの直接のワンクリック パスを提供する必要があります。エンドユーザーが元のウェブページにアクセスするのを遅らせたり、抽象化したりする他の実装(複数回のクリックが必要なパスや、中間画像ビューアの使用など)は許可されません。
レスポンス
画像検索を使用するグラウンディングされたレスポンスの場合、API は明確な帰属とメタデータを提供し、出力を検証済みのソースにリンクします。groundingMetadata オブジェクトの主なフィールドは次のとおりです。
imageSearchQueries: モデルが視覚的コンテキスト(画像検索)に使用する特定のクエリ。groundingChunks: 取得した結果のソース情報が含まれます。画像ソースの場合、新しい画像チャンクタイプを使用してリダイレクト URL として返されます。このチャンクには次のものが含まれます。uri: アトリビューションのウェブページ URL(ランディング ページ)。image_uri: 画像の直接 URL。
groundingSupports: 生成されたコンテンツをチャンク内の関連する引用元にリンクする特定のマッピングを提供します。searchEntryPoint: 検索候補をレンダリングするための準拠した HTML と CSS を含む「Google 検索」チップが含まれます。
動画から画像への生成(3.1 Flash)
動画から画像への生成では、動画のコンテキストをマルチモーダル参照として使用して、新しい画像を生成できます。この機能は、高品質な動画のサムネイル、映画のポスター、概要のインフォグラフィック、動画のシーンからインスピレーションを得た新しいアートワークの作成に役立ちます。
生成中、モデルはコンテキスト内の動画フレームを分析し(モデルの入力トークン上限である 131,072 トークンまで)、視覚的なテーマとキーイベントを抽出します。次に、テキスト プロンプトとともにそれらを使用して、出力画像を合成します。
API リクエストで公開 YouTube URL を直接渡すか、Files API を使用してローカル動画ファイルをアップロードできます。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Pass a public YouTube video URL as part of the contents
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=[
types.Part(
file_data=types.FileData(file_uri="https://www.youtube.com/watch?v=UTdfxFyOQTI"),
video_metadata=types.VideoMetadata(fps=0.5)
),
"Generate a poster image that captures the key themes of this video."
],
config=types.GenerateContentConfig(
response_modalities=["TEXT", "IMAGE"]
)
)
# Save the generated image part
for part in response.parts:
if part.inline_data is not None:
image = part.as_image()
image.save("video_poster.png")
print("Image saved as video_poster.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: [
{
fileData: {
fileUri: "https://www.youtube.com/watch?v=UTdfxFyOQTI",
},
videoMetadata: {
fps: 0.5
}
},
{ text: "Generate a poster image that captures the key themes of this video." }
],
config: {
responseModalities: ["TEXT", "IMAGE"]
}
});
for (const part of response.candidates[0].content.parts) {
if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("video_poster.png", buffer);
console.log("Image saved as video_poster.png");
}
}
}
main();
Go
package main
import (
"context"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
videoPart := genai.NewPartFromURI("https://www.youtube.com/watch?v=UTdfxFyOQTI", "video/mp4")
videoPart.VideoMetadata = &genai.VideoMetadata{FPS: genai.Ptr(0.5)}
parts := []*genai.Part{
videoPart,
genai.NewPartFromText("Generate a poster image that captures the key themes of this video."),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, err := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image",
contents,
&genai.GenerateContentConfig{
ResponseModalities: []string{"TEXT", "IMAGE"},
},
)
if err != nil {
log.Fatal(err)
}
for _, part := range result.Candidates[0].Content.Parts {
if part.InlineData != nil {
imageBytes := part.InlineData.Data
_ = os.WriteFile("video_poster.png", imageBytes, 0644)
log.Println("Image saved as video_poster.png")
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.FileData;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import com.google.genai.types.VideoMetadata;
import com.google.common.collect.ImmutableList;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class VideoToImage {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
Part videoPart = Part.builder()
.fileData(FileData.builder()
.fileUri("https://www.youtube.com/watch?v=UTdfxFyOQTI")
.build())
.videoMetadata(VideoMetadata.builder()
.fps(0.5)
.build())
.build();
Part textPart = Part.builder()
.text("Generate a poster image that captures the key themes of this video.")
.build();
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image",
Content.builder()
.role("user")
.parts(ImmutableList.of(videoPart, textPart))
.build(),
config);
for (Part part : response.parts()) {
if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("video_poster.png"), blob.data().get());
System.out.println("Image saved as video_poster.png");
}
}
}
}
}
}
C#
using Google.GenAI;
using Google.GenAI.Types;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class VideoToImage {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part
{
FileData = new FileData { FileUri = "https://www.youtube.com/watch?v=UTdfxFyOQTI" },
VideoMetadata = new VideoMetadata { Fps = 0.5 }
},
new Part { Text = "Generate a poster image that captures the key themes of this video." }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "TEXT", "IMAGE" }
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("video_poster.png", imageBytes);
Console.WriteLine("Image saved as video_poster.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{
"file_data": {
"file_uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI"
},
"video_metadata": {
"fps": 0.5
}
},
{"text": "Generate a poster image that captures the key themes of this video."}
]
}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'

最大 4K 解像度の画像を生成する
Gemini 3 画像モデルは、デフォルトで 1K 画像を生成しますが、2K、4K、512(0.5K)(Gemini 3.1 Flash Image のみ)の画像を出力することもできます。高解像度のアセットを生成するには、generation_config で image_size を指定します。
大文字の「K」を使用する必要があります(例: 1K、2K、4K)。512 値には「K」という接尾辞は使用されません。小文字のパラメータ(1k など)は拒否されます。
Python
from google import genai
from google.genai import types
prompt = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
aspect_ratio = "1:1" # "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
resolution = "1K" # "512", "1K", "2K", "4K"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
response_format={"image": {aspect_ratio: aspect_ratio, image_size: resolution}},
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("butterfly.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
'Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.';
const aspectRatio = '1:1';
const resolution = '1K';
const response = await ai.models.generateContent({
model: 'gemini-3.1-flash-image',
contents: prompt,
config: {
responseModalities: ['TEXT', 'IMAGE'],
responseFormat: {
image: {
aspectRatio: aspectRatio,
imageSize: resolution,
}
},
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
ImageConfig: &pb.ImageConfig{
AspectRatio: "1:1",
ImageSize: "1K",
},
}
prompt := "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
resp, err := model.GenerateContent(ctx, genai.Text(prompt))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("butterfly.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.Tool;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class HiRes {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.imageSize("4K")
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image", """
Da Vinci style anatomical sketch of a dissected Monarch butterfly.
Detailed drawings of the head, wings, and legs on textured
parchment with notes in English.
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("butterfly.png"), blob.data().get());
}
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class HiRes {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English." }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "TEXT", "IMAGE" },
ImageConfig = new ImageConfig
{
AspectRatio = "1:1",
ImageSize = "1K"
}
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("butterfly.png", imageBytes);
Console.WriteLine("Image saved as butterfly.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."}]}],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"responseFormat": {
"image": {"aspectRatio": "1:1", "imageSize": "1K"}
}
}
}'
このプロンプトから生成された画像の例を次に示します。

思考プロセス
Gemini 3 画像モデルは、複雑なプロンプトに推論プロセス(「思考」)を使用する思考モデルです。この機能はデフォルトで有効になっており、API で無効にすることはできません。思考プロセスの詳細については、Gemini の思考ガイドをご覧ください。
このモデルは、構図とロジックをテストするために最大 2 つの中間画像を生成します。Thinking の最後の画像は、最終的にレンダリングされた画像でもあります。
最終的な画像が生成されるまでの思考を確認できます。
Python
for part in response.parts:
if part.thought:
if part.text:
print(part.text)
elif image:= part.as_image():
image.show()
JavaScript
for (const part of response.candidates[0].content.parts) {
if (part.thought) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, 'base64');
fs.writeFileSync('image.png', buffer);
console.log('Image saved as image.png');
}
}
}
Java
for (Part part : response.parts()) {
if (part.thought().orElse(false)) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("image.png"), blob.data().get());
System.out.println("Image saved as image.png");
}
}
}
}
C#
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Thought) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("image.png", imageBytes);
Console.WriteLine("Image saved as image.png");
}
}
}
}
思考レベルを制御する
Gemini 3.1 Flash Image を使用すると、モデルが使用する思考の量を制御して、品質とレイテンシのバランスを取ることができます。デフォルトの thinkingLevel は minimal で、サポートされているレベルは minimal と high です。thinkingLevel を minimal に設定すると、レイテンシが最小限に抑えられたレスポンスが返されます。最小限の思考とは、モデルがまったく思考を使用しないという意味ではないことに注意してください。
includeThoughts ブール値を追加して、モデルが生成した思考をレスポンスで返すか、非表示のままにするかを指定できます。
Python
from google import genai
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents="A futuristic city built inside a giant glass bottle floating in space",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
thinking_level="High",
include_thoughts=True
),
)
)
for part in response.parts:
if part.thought: # Skip outputting thoughts
continue
if part.text:
display(Markdown(part.text))
elif image:= part.as_image():
image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: "A futuristic city built inside a giant glass bottle floating in space",
config: {
responseModalities: ["IMAGE"],
thinkingConfig: {
thinkingLevel: "High",
includeThoughts: true
},
},
});
for (const part of response.candidates[0].content.parts) {
if (part.thought) { // Skip outputting thoughts
continue;
}
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
pb "google.golang.org/genai/schema"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Image},
ThinkingConfig: &pb.ThinkingConfig{
ThinkingLevel: "High",
IncludeThoughts: true,
},
}
prompt := "A futuristic city built inside a giant glass bottle floating in space"
resp, err := model.GenerateContent(ctx, genai.Text(prompt))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if part.Thought { // Skip outputting thoughts
continue
}
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("image.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import com.google.genai.types.ThinkingConfig;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class ThinkingLevels {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("IMAGE")
.thinkingConfig(ThinkingConfig.builder()
.thinkingLevel("High")
.includeThoughts(true)
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image",
"A futuristic city built inside a giant glass bottle floating in space",
config);
for (Part part : response.parts()) {
if (part.thought().orElse(false)) {
// Skip outputting thoughts
continue;
}
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("image.png"), blob.data().get());
System.out.println("Image saved as image.png");
}
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class ThinkingLevels {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "A futuristic city built inside a giant glass bottle floating in space" }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "IMAGE" },
ThinkingConfig = new ThinkingConfig
{
ThinkingLevel = "High",
IncludeThoughts = true
}
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Thought) {
// Skip outputting thoughts
continue;
}
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("image.png", imageBytes);
Console.WriteLine("Image saved as image.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "A futuristic city built inside a giant glass bottle floating in space"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "High",
"includeThoughts": true
}
}
}'
includeThoughts が true または false に設定されているかどうかにかかわらず、思考トークンは課金されます。これは、プロセスを表示するかどうかにかかわらず、思考プロセスがデフォルトで常に実行されるためです。
思考シグネチャ
思考シグネチャは、モデルの内部的な思考プロセスを暗号化したもので、マルチターンのインタラクションで推論コンテキストを保持するために使用されます。すべてのレスポンスに thought_signature フィールドが含まれます。原則として、モデルのレスポンスで思考シグネチャを受け取った場合は、次のターンで会話履歴を送信するときに、受け取ったとおりに渡す必要があります。思考シグネチャを循環させないと、レスポンスが失敗する可能性があります。署名全般について詳しくは、思考署名のドキュメントをご覧ください。
思考シグネチャの仕組みは次のとおりです。
- レスポンスの一部である画像
mimetypeを含むすべてのinline_data部分には署名が必要です。 - 考えの直後に(画像の前に)テキスト部分がある場合は、最初のテキスト部分にも署名が必要です。
- 画像
mimetypeを含むinline_data部分が思考の一部である場合、署名は含まれません。
次のコードは、思考シグネチャが含まれる場所の例を示しています。
[
{
"inline_data": {
"data": "<base64_image_data_0>",
"mime_type": "image/png"
},
"thought": true // Thoughts don't have signatures
},
{
"inline_data": {
"data": "<base64_image_data_1>",
"mime_type": "image/png"
},
"thought": true // Thoughts don't have signatures
},
{
"inline_data": {
"data": "<base64_image_data_2>",
"mime_type": "image/png"
},
"thought": true // Thoughts don't have signatures
},
{
"text": "Here is a step-by-step guide to baking macarons, presented in three separate images.\n\n### Step 1: Piping the Batter\n\nThe first step after making your macaron batter is to pipe it onto a baking sheet. This requires a steady hand to create uniform circles.\n\n",
"thought_signature": "<Signature_A>" // The first non-thought part always has a signature
},
{
"inline_data": {
"data": "<base64_image_data_3>",
"mime_type": "image/png"
},
"thought_signature": "<Signature_B>" // All image parts have a signatures
},
{
"text": "\n\n### Step 2: Baking and Developing Feet\n\nOnce piped, the macarons are baked in the oven. A key sign of a successful bake is the development of \"feet\"—the ruffled edge at the base of each macaron shell.\n\n"
// Follow-up text parts don't have signatures
},
{
"inline_data": {
"data": "<base64_image_data_4>",
"mime_type": "image/png"
},
"thought_signature": "<Signature_C>" // All image parts have a signatures
},
{
"text": "\n\n### Step 3: Assembling the Macaron\n\nThe final step is to pair the cooled macaron shells by size and sandwich them together with your desired filling, creating the classic macaron dessert.\n\n"
},
{
"inline_data": {
"data": "<base64_image_data_5>",
"mime_type": "image/png"
},
"thought_signature": "<Signature_D>" // All image parts have a signatures
}
]
その他の画像生成モード
Gemini は、プロンプトの構造とコンテキストに基づいて、次のような他の画像操作モードをサポートしています。
- テキスト画像変換とテキスト(インターリーブ): 関連するテキストを含む画像を出力します。
- プロンプトの例: 「パエリアのレシピをイラスト付きで生成してください。」
- 画像とテキスト画像変換とテキスト(インターリーブ): 入力画像とテキストを使用して、関連する新しい画像とテキストを作成します。
- プロンプトの例:(家具付きの部屋の画像を提示して)「この部屋に合いそうなソファの色には他にどんなものがありますか?画像を更新してください」。
画像をバッチで生成する
多数の画像を生成する必要がある場合は、Batch API を使用できます。最大 24 時間のターンアラウンドと引き換えに、レートの上限が引き上げられます。
Batch API の画像例とコードについては、Batch API の画像生成に関するドキュメントとクックブックをご覧ください。
プロンプト ガイドと戦略
画像生成をマスターするには、次の基本原則から始めます。
キーワードを並べるだけでなく、シーンを説明します。このモデルの強みは、言語を深く理解していることです。物語形式の記述的な段落は、関連性のない単語のリストよりも、一貫性のある優れた画像を生成する可能性がほぼ常に高くなります。
画像を生成するためのプロンプト
次の戦略は、効果的なプロンプトを作成して、思いどおりの画像を生成するのに役立ちます。
写真
リアルな画像の場合は、写真用語を使用します。カメラアングル、レンズの種類、照明、細部について言及して、モデルがリアルな結果を生成するようにします。
| プロンプト | 生成された出力 |
|---|---|
| 深い日焼けのしわと、温かく知的な笑顔を浮かべた、日本の高齢の陶芸家のクローズアップ ポートレートの写真。彼は、新しく釉薬をかけた茶碗を注意深く調べています。舞台は、太陽の光が差し込む彼の素朴な工房。窓から差し込む柔らかいゴールデンアワーの光で照らされ、粘土のきめ細かい質感が際立っている。85 mm ポートレート レンズで撮影したように、背景が柔らかくぼかされている(ボケ)ようにしてください。全体的に穏やかで、熟練した印象を与える仕上がり。縦向き。 |

|
スタイリッシュなイラストとステッカー
ステッカー、アイコン、アセットを作成する場合は、スタイルを明示的に指定し、白い背景をリクエストします。
| プロンプト | 生成された出力 |
|---|---|
| 小さな竹の帽子をかぶった、嬉しそうなレッサーパンダの kawaii スタイルのステッカー。緑色の竹の葉を食べています。太くてくっきりとした輪郭、シンプルなセルシェーディング、鮮やかなカラーパレットが特徴です。背景は白である必要があります。 |

|
画像内の正確なテキスト
Gemini はテキストのレンダリングに優れています。テキスト、フォント スタイル(説明)、全体的なデザインを明確にします。Gemini 3 Pro Image を使用して、プロフェッショナルなアセットを制作します。
| プロンプト | 生成された出力 |
|---|---|
| 「The Daily Grind」というコーヒー ショップのモダンでミニマルなロゴを作成してください。テキストは、クリーンで太字の Sans Serif フォントを使用してください。カラーパターンが白黒である。ロゴを円の中に配置します。コーヒー豆を賢く使う。 |
|
商品のモックアップと広告写真
e コマース、広告、ブランディング用のクリーンでプロフェッショナルな商品ショットの作成に最適です。
| プロンプト | 生成された出力 |
|---|---|
| 高解像度のスタジオ照明で撮影された商品写真。マットブラックのミニマルなセラミック製コーヒー マグが、磨かれたコンクリートの表面に置かれている。照明は、柔らかく拡散したハイライトを作り出し、強い影をなくすように設計されたソフトボックスを使った 3 点照明です。カメラの角度は、クリーンなラインを際立たせるため、やや上向きの 45 度で撮影されています。コーヒーから立ち上る湯気に焦点が合っている、超リアルな画像。正方形の画像。 |

|
ミニマルでネガティブ スペースのデザイン
テキストを重ねて表示するウェブサイト、プレゼンテーション、マーケティング資料の背景の作成に最適です。
| プロンプト | 生成された出力 |
|---|---|
| フレームの右下に配置された 1 枚の繊細な赤いカエデの葉をフィーチャーしたミニマリストの構図。背景は広大なオフホワイトのキャンバスで、テキスト用のネガティブ スペースが大きく取られています。左上から柔らかく拡散した照明。正方形の画像。 |

|
連続アート(コミック パネル / ストーリーボード)
キャラクターの一貫性とシーンの説明に基づいて、ビジュアル ストーリーテリング用のパネルを作成します。テキストの精度とストーリーテリングの能力については、これらのプロンプトは Gemini 3.1 Pro と Gemini 3.1 Flash Image で最適に動作します。
| プロンプト | 生成された出力 |
|---|---|
|
入力画像: 
プロンプト: 3 コマのマンガを、高コントラストのモノクロ インクを使った、ざらざらしたノワール アート スタイルで作成して。キャラクターをユーモラスなシーンに配置します。 |

|
Google 検索によるグラウンディング
Google 検索を使用して、最近の情報やリアルタイムの情報に基づいて画像を生成します。これは、ニュースや天気など、時間的制約のあるトピックに役立ちます。
| プロンプト | 生成された出力 |
|---|---|
| 昨夜のチャンピオンズ リーグのアーセナル戦のシンプルでスタイリッシュなグラフィックを作成して |

|
画像を編集するためのプロンプト
これらの例は、編集、構図、スタイル転送のテキスト プロンプトとともに画像を提供する方法を示しています。
要素の追加と削除
画像を提供し、変更内容を説明します。モデルは、元の画像のスタイル、照明、遠近法に一致します。
| プロンプト | 生成された出力 |
|---|---|
|
入力画像: 
プロンプト: 提供した猫の画像を使用して、猫の頭に小さな編み物の魔法使いの帽子を追加してください。写真の柔らかい照明と一致し、快適に座っているように見えるようにします。 |

|
インペイント(セマンティック マスク)
会話形式で「マスク」を定義して、画像の特定の部分を編集し、残りの部分はそのままにできます。
| プロンプト | 生成された出力 |
|---|---|
|
入力画像: 
プロンプト: 提供されたリビングルームの画像を使用して、青いソファだけをヴィンテージの茶色の革製チェスターフィールド ソファに変更してください。ソファの枕や照明など、部屋の他の部分は変更しないでください。 |

|
画風変換
画像を提供し、異なる画風でコンテンツを再現するようにモデルに指示します。
| プロンプト | 生成された出力 |
|---|---|
|
入力画像: 
プロンプト: 夜の都会のストリートの写真を、フィンセント ファン ゴッホの『星月夜』の画風に変換して。建物や車の元の構図はそのままに、すべての要素を渦巻くようなインパスト ブラシストロークと、濃い青と明るい黄色の劇的なパレットでレンダリングします。 |

|
高度な構図: 複数の画像を組み合わせる
複数の画像をコンテキストとして提供し、新しい複合シーンを作成します。これは、プロダクト モックアップやクリエイティブ コラージュに最適です。
| プロンプト | 生成された出力 |
|---|---|
|
入力画像: 

プロンプト: プロ仕様の e コマース ファッション写真を作成します。1 枚目の画像の青い花柄のドレスを、2 枚目の画像の女性に着せてください。屋外の環境に合わせて照明と影を調整し、ドレスを着た女性のリアルな全身ショットを生成します。 |

|
高忠実度の詳細保持
編集時に重要な詳細(顔やロゴなど)が保持されるように、編集リクエストとともに詳細を説明してください。
| プロンプト | 生成された出力 |
|---|---|
|
入力画像: 
プロンプト: 茶色の髪、青い目、無表情の女性の最初の画像を取得します。2 枚目の画像のロゴを彼女の黒い T シャツに追加して。女性の顔と特徴が完全に変わらないようにします。ロゴは、シャツの折り目に沿って生地に自然にプリントされているように見える必要があります。 |
|
命を吹き込む
ラフスケッチや図面をアップロードし、モデルに完成した画像に仕上げるよう依頼します。
| プロンプト | 生成された出力 |
|---|---|
|
入力画像: 
プロンプト: この未来的な車のラフな鉛筆スケッチを、ショールームに展示されている完成したコンセプトカーの洗練された写真に変換してください。スケッチの滑らかなラインとロープロファイルはそのままに、メタリック ブルーの塗装とネオンのリム照明を追加します。 |

|
キャラクターの一貫性: 360 度ビュー
さまざまな角度を繰り返しプロンプトすることで、キャラクターの 360 度ビューを生成できます。最適な結果を得るには、一貫性を保つために、以前に生成した画像を後続のプロンプトに含めます。複雑なポーズの場合は、目的のポーズの参照画像を含めます。
| プロンプト | 生成された出力 |
|---|---|
|
入力画像:
プロンプト: 白い背景を背に、右を向いた横顔の男性のスタジオ ポートレート |


|
ベスト プラクティス
結果を優れたものにするには、これらのプロフェッショナルな戦略をワークフローに組み込みます。
- 非常に具体的にする: 詳細に説明するほど、より細かく制御できます。「ファンタジー アーマー」ではなく、「銀の葉の模様がエッチングされた、装飾的なエルフのプレート アーマー。ハイカラーとハヤブサの翼の形をした肩当て付き」とします。
- コンテキストと意図を提供する: 画像の目的を説明します。モデルのコンテキストの理解が最終出力に影響します。たとえば、「高級感のあるミニマリストのスキンケア ブランドのロゴを作成して」は、「ロゴを作成して」よりも効果的です。
- 繰り返して改良: 最初の試行で完璧な画像が生成されるとは限りません。モデルの会話的な性質を利用して、小さな変更を行います。「素晴らしいですが、照明をもう少し暖色にできますか?」や「すべてそのままにして、キャラクターの表情をもっとシリアスにしてください」などのフォローアップ プロンプトを使用します。
- 手順ガイドを使用する: 多くの要素を含む複雑なシーンの場合は、プロンプトを手順に分割します。「まず、夜明けの静かで霧のかかった森の背景を作成して。次に、前景に苔むした古代の石の祭壇を追加して。最後に、祭壇の上に光る剣を 1 本置いて。」
- 「セマンティック ネガティブ プロンプト」を使用する: 「車なし」ではなく、「交通の気配のない、空っぽの寂れた通り」のように、ポジティブな表現でシーンを説明します。
- カメラを制御する: 写真や映画の撮影用語を使用して、構図を制御します。
wide-angle shot、macro shot、low-angle perspectiveなどの用語。
制限事項
- 最高のパフォーマンスを実現するには、EN、ar-EG、de-DE、es-MX、fr-FR、hi-IN、id-ID、it-IT、ja-JP、ko-KR、pt-BR、ru-RU、ua-UA、vi-VN、zh-CN のいずれかの言語を使用してください。
- 画像生成では、音声入力はサポートされていません。動画入力は Gemini 3.1 Flash Image でのみサポートされています。
- モデルは、ユーザーが明示的にリクエストした画像の出力数を正確に守るとは限りません。
gemini-2.5-flash-imageは最大 3 枚の画像を、gemini-3-pro-imageは高忠実度で 5 枚の画像をサポートし、合計で最大 14 枚の画像をサポートします。gemini-3.1-flash-imageは、1 つのワークフローで最大 4 文字の文字類似性と最大 10 個のオブジェクトの忠実度をサポートします。- テキストを含む画像を生成するときは、まずテキストを生成してから、そのテキストを画像に変換するように頼むと、良い結果が得られます。
gemini-3.1-flash-image現在、Google 検索によるグラウンディングでは、ウェブ検索から取得した人物の実写画像を使用することはできません。- 生成されたすべての画像には SynthID の透かしが埋め込まれています。
オプションの構成
必要に応じて、generate_content 呼び出しの config フィールドで、モデルの出力のレスポンス モダリティとアスペクト比を構成できます。
出力形式
モデルはデフォルトでテキストと画像の両方のレスポンス(response_modalities=['Text', 'Image'])を返します。response_modalities=['Image'] を使用すると、テキストなしで画像のみを返すようにレスポンスを構成できます。
Python
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=['Image']
)
)
JavaScript
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: prompt,
config: {
responseModalities: ['Image']
}
});
Go
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
&genai.GenerateContentConfig{
ResponseModalities: "Image",
},
)
Java
response = client.models.generateContent(
"gemini-3.1-flash-image",
prompt,
GenerateContentConfig.builder()
.responseModalities("IMAGE")
.build());
C#
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part> { new Part { Text = prompt } },
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "IMAGE" }
}
);
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}],
"generationConfig": {
"responseModalities": ["Image"]
}
}'
アスペクト比と画像サイズ
デフォルトでは、モデルは出力画像のサイズを入力画像のサイズに合わせるか、1:1 の正方形を生成します。レスポンス リクエストの response_format の aspect_ratio フィールドを使用して、出力画像のアスペクト比を制御できます。
Python
# For gemini-2.5-flash-image
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents=[prompt],
config=types.GenerateContentConfig(
response_format={"image": {aspect_ratio: "16:9",}}
)
)
# For gemini-3.1-flash-image and gemini-3-pro-image
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=[prompt],
config=types.GenerateContentConfig(
response_format={"image": {aspect_ratio: "16:9", image_size: "2K",}}
)
)
JavaScript
// For gemini-2.5-flash-image
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
config: {
responseFormat: {
image: {
aspectRatio: "16:9",
}
},
}
});
// For gemini-3.1-flash-image and gemini-3-pro-image
const response_gemini3 = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: prompt,
config: {
responseFormat: {
image: {
aspectRatio: "16:9",
imageSize: "2K",
}
},
}
});
Go
// For gemini-2.5-flash-image
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
&genai.GenerateContentConfig{
ImageConfig: &genai.ImageConfig{
AspectRatio: "16:9",
},
}
)
// For gemini-3.1-flash-image and gemini-3-pro-image
result_gemini3, _ := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
&genai.GenerateContentConfig{
ImageConfig: &genai.ImageConfig{
AspectRatio: "16:9",
ImageSize: "2K",
},
}
)
Java
// For gemini-2.5-flash-image
response = client.models.generateContent(
"gemini-2.5-flash-image",
prompt,
GenerateContentConfig.builder()
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.build())
.build());
// For gemini-3.1-flash-image and gemini-3-pro-image
response_gemini3 = client.models.generateContent(
"gemini-3.1-flash-image",
prompt,
GenerateContentConfig.builder()
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.imageSize("2K")
.build())
.build());
C#
// For gemini-2.5-flash-image
var response = await client.Models.GenerateContentAsync(
model: "gemini-2.5-flash-image",
contents: new List<Part> { new Part { Text = prompt } },
config: new GenerateContentConfig
{
ImageConfig = new ImageConfig
{
AspectRatio = "16:9"
}
}
);
// For gemini-3.1-flash-image and gemini-3-pro-image
var response_gemini3 = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part> { new Part { Text = prompt } },
config: new GenerateContentConfig
{
ImageConfig = new ImageConfig
{
AspectRatio = "16:9",
ImageSize = "2K"
}
}
);
REST
# For gemini-2.5-flash-image
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}],
"generationConfig": {
"responseFormat": {
"image": {
"aspectRatio": "16:9"
}
}
}
}'
# For gemini-3-pro-image
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}],
"generationConfig": {
"responseFormat": {
"image": {
"aspectRatio": "16:9",
"imageSize": "2K"
}
}
}
}'
使用可能なさまざまな比率と生成される画像のサイズを次の表に示します。
3.1 Flash Image
| アスペクト比 | 512 解像度 | 0.5K トークン | 1K 解像度 | 1K トークン | 2K 解像度 | 2K トークン | 4K 解像度 | 4K トークン |
|---|---|---|---|---|---|---|---|---|
| 1:1 | 512x512 | 747 | 1024 x 1024 | 1120 | 2,048x2,048 | 1680 | 4096x4096 | 2520 |
| 1:4 | 256x1024 | 747 | 512x2048 | 1120 | 1024x4096 | 1680 | 2048x8192 | 2520 |
| 1:8 | 192x1536 | 747 | 384x3072 | 1120 | 768x6144 | 1680 | 1536x12288 | 2520 |
| 2:3 | 424x632 | 747 | 848x1264 | 1120 | 1696x2528 | 1680 | 3392x5056 | 2520 |
| 3:2 | 632x424 | 747 | 1264x848 | 1120 | 2528x1696 | 1680 | 5056x3392 | 2520 |
| 3:4 | 448×600 | 747 | 896x1200 | 1120 | 1792x2400 | 1680 | 3584x4800 | 2520 |
| 4:1 | 1024x256 | 747 | 2048x512 | 1120 | 4096x1024 | 1680 | 8192x2048 | 2520 |
| 4:3 | 600×448 | 747 | 1,200×896 | 1120 | 2400x1792 | 1680 | 4800x3584 | 2520 |
| 4:5 | 464×576 | 747 | 928x1152 | 1120 | 1856x2304 | 1680 | 3712x4608 | 2520 |
| 5:4 | 576x464 | 747 | 1152x928 | 1120 | 2304x1856 | 1680 | 4608x3712 | 2520 |
| 8:1 | 1536x192 | 747 | 3072x384 | 1120 | 6144x768 | 1680 | 12288x1536 | 2520 |
| 9:16 | 384x688 | 747 | 768x1376 | 1120 | 1536x2752 | 1680 | 3072x5504 | 2520 |
| 16:9 | 688x384 | 747 | 1376x768 | 1120 | 2752x1536 | 1680 | 5,504 x 3,072 | 2520 |
| 21:9 | 792×168 | 747 | 1584x672 | 1120 | 3168x1344 | 1680 | 6336x2688 | 2520 |
3.1 Pro Image
| アスペクト比 | 1K 解像度 | 1K トークン | 2K 解像度 | 2K トークン | 4K 解像度 | 4K トークン |
|---|---|---|---|---|---|---|
| 1:1 | 1024 x 1024 | 1120 | 2,048x2,048 | 1120 | 4096x4096 | 2000 |
| 2:3 | 848x1264 | 1120 | 1696x2528 | 1120 | 3392x5056 | 2000 |
| 3:2 | 1264x848 | 1120 | 2528x1696 | 1120 | 5056x3392 | 2000 |
| 3:4 | 896x1200 | 1120 | 1792x2400 | 1120 | 3584x4800 | 2000 |
| 4:3 | 1,200×896 | 1120 | 2400x1792 | 1120 | 4800x3584 | 2000 |
| 4:5 | 928x1152 | 1120 | 1856x2304 | 1120 | 3712x4608 | 2000 |
| 5:4 | 1152x928 | 1120 | 2304x1856 | 1120 | 4608x3712 | 2000 |
| 9:16 | 768x1376 | 1120 | 1536x2752 | 1120 | 3072x5504 | 2000 |
| 16:9 | 1376x768 | 1120 | 2752x1536 | 1120 | 5,504 x 3,072 | 2000 |
| 21:9 | 1584x672 | 1120 | 3168x1344 | 1120 | 6336x2688 | 2000 |
Gemini 2.5 Flash Image
| アスペクト比 | 解決策 | トークン |
|---|---|---|
| 1:1 | 1024 x 1024 | 1290 |
| 2:3 | 832x1248 | 1290 |
| 3:2 | 1248x832 | 1290 |
| 3:4 | 864x1184 | 1290 |
| 4:3 | 1184x864 | 1290 |
| 4:5 | 896x1152 | 1290 |
| 5:4 | 1152x896 | 1290 |
| 9:16 | 768x1344 | 1290 |
| 16:9 | 1344x768 | 1290 |
| 21:9 | 1536x672 | 1290 |
モデルの選択
特定のユースケースに最適なモデルを選択します。
Gemini 3.1 Flash Image(Nano Banana 2)は、コストとレイテンシのバランスが取れた、最高の総合的なパフォーマンスとインテリジェンスを備えているため、画像生成モデルとして最適です。詳細については、モデルの料金と機能のページをご覧ください。
Gemini 3 Pro Image(Nano Banana Pro)は、プロフェッショナルなアセット制作と複雑な指示に対応するように設計されています。このモデルは、Google 検索を使用した実世界のグラウンディング、生成前に構成を調整するデフォルトの「思考」プロセスを備えており、最大 4K の解像度の画像を生成できます。詳細については、モデルの料金と機能のページをご覧ください。
Gemini 2.5 Flash Image(Nano Banana)は、速度と効率性を重視して設計されています。このモデルは、大容量で低レイテンシのタスク向けに最適化されており、1, 024 ピクセルの解像度で画像を生成します。詳細については、モデルの料金と機能のページをご覧ください。
Imagen を使用する場面
Gemini の組み込みの画像生成機能を使用するだけでなく、Gemini API を介して Google の特別な画像生成モデルである Imagen にもアクセスできます。シャットダウン日より前に移行する計画を立ててください。
次のステップ
- その他の例とコードサンプルについては、クックブック ガイドをご覧ください。
- Gemini API を使用して動画を生成する方法については、Veo ガイドをご覧ください。
- Gemini モデルの詳細については、Gemini モデルをご覧ください。