
LiteRT는 에지 플랫폼에서 고성능 ML 및 생성형 AI를 배포하기 위한 Google의 온디바이스 프레임워크입니다.
효율적인 변환, 런타임, 기기 내 머신러닝 최적화
실전에서 검증된 TensorFlow Lite 기반으로 구축
LiteRT는 새로운 기능일 뿐만 아니라 전 세계에서 가장 널리 배포된 머신러닝 런타임의 차세대 버전입니다. 매일 사용하는 앱을 지원하며 수십억 대의 기기에서 짧은 지연 시간과 높은 개인 정보 보호를 제공합니다.
가장 중요한 Google 앱에서 신뢰함
10만 개 이상의 애플리케이션, 수십억 명의 전 세계 사용자
LiteRT 하이라이트

크로스 플랫폼 지원

생성형 AI 활용
간소화된 하드웨어 가속

다중 프레임워크 지원



개발 경로 선택
LiteRT를 사용하여 고성능 모바일 앱부터 리소스가 제한된 IoT 기기까지 어디에나 AI를 배포하세요.
기존 TFLite 사용자
플랫폼 (Android, 데스크톱, 웹) 전반에서 향상된 성능과 통합 API를 활용하기 위해 LiteRT로 전환합니다.
BYOM : 자체 모델 사용
PyTorch 모델이 있고 온디바이스 비전 또는 오디오 환경을 구현하려고 합니다.
생성형 AI 모델 배포
Gemma와 같은 최적화된 개방형 가중치 생성형 AI 모델 또는 다른 개방형 가중치 모델을 사용하여 정교한 온디바이스 챗봇 만들기
[고급] 모델 전문가
맞춤 모델을 작성하거나 최대 성능을 위해 하드웨어별 CPU/GPU/NPU 최적화를 실행합니다.
샘플, 모델, 데모

GitHub에서 LiteRT 샘플 앱 보기
완전한 엔드 투 엔드 샘플 앱

생성형 AI 모델 보기
선행 학습된 즉시 사용 가능한 생성형 AI 모델

데모 보기 - Google AI Edge 갤러리 앱
LiteRT를 사용하는 온디바이스 ML/생성형 AI 사용 사례를 보여주는 갤러리
블로그 및 공지사항
LiteRT팀의 최신 공지사항, 기술 심층 분석, 성능 벤치마크를 확인하세요.

LiteRT 및 NPU를 사용한 실제 온디바이스 AI 빌드
업계 리더가 LiteRT와 NPU를 사용하여 실제 고성능 온디바이스 AI 애플리케이션을 빌드하는 방법을 알아보세요.
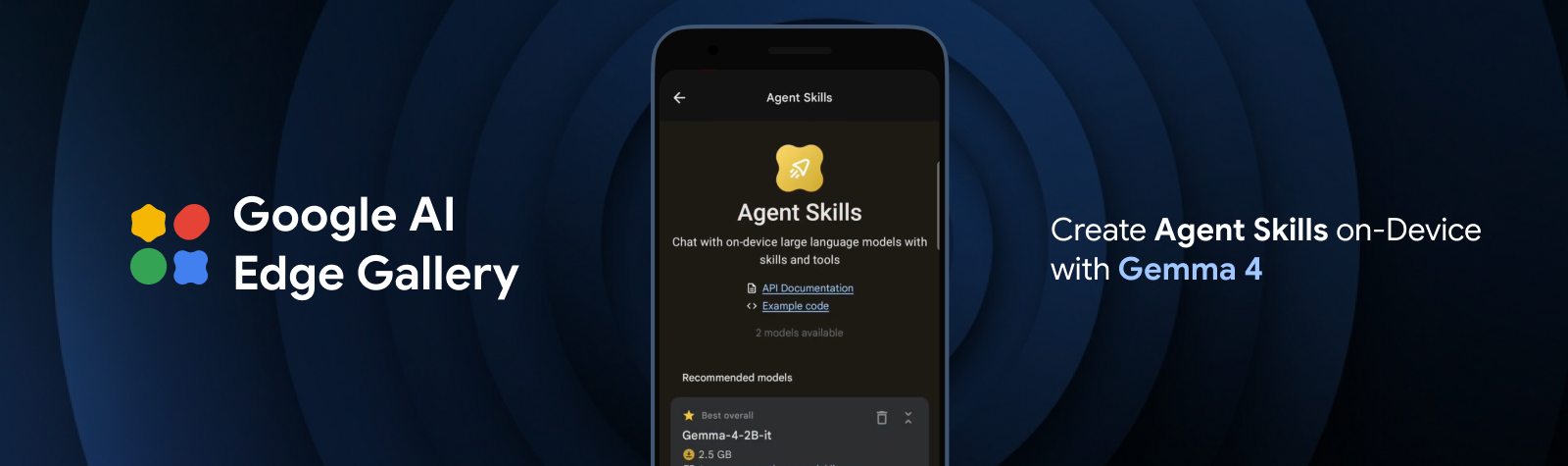
Gemma 4로 최첨단 에이전트 기술을 에지에 적용
새로운 Gemma 4 제품군과 LiteRT를 사용하여 에이전트 및 다단계 계획 기능을 완전히 온디바이스로 배포하세요.

LiteRT: 온디바이스 AI를 위한 범용 프레임워크
고성능 배포를 위해 TFLite에서 발전한 Google의 통합 온디바이스 ML 프레임워크입니다.
MediaTek NPU 및 LiteRT: 차세대 온디바이스 AI 지원
고효율 AI를 위해 MediaTek 칩셋으로 NPU 가속 지원 확대
LiteRT를 사용하여 Qualcomm NPU에서 최고 성능 실현
Qualcomm 신경망 처리 장치에서 생성형 AI의 획기적인 성능을 구현합니다.

LiteRT: 최대 성능, 간소화
자동 하드웨어 선택 및 비동기 실행을 위한 CompiledModel API가 도입되었습니다.
LiteRT-LM을 사용한 Chrome, Chromebook Plus, Pixel Watch의 온디바이스 생성형 AI
LiteRT-LM을 사용하여 웨어러블 및 브라우저 기반 플랫폼에 언어 모델을 배포합니다.

Google AI Edge 소형 언어 모델, 멀티모달리티, 함수 호출
에지 언어 모델의 RAG, 멀티모달, 함수 호출에 관한 최신 통계
커뮤니티 참여
LiteRT GitHub 커뮤니티
프로젝트에 직접 참여하고 핵심 개발자와 공동작업하세요.

Hugging Face Hub
Hugging Face Hub에서 최적화된 개방형 가중치 모델에 액세스하세요.