
Każdy kalkulator jest węzłem grafu. Opisujemy sposób tworzenia
kalkulator, jak uruchomić kalkulator, jak wykonywać obliczenia,
strumienie wejściowe i wyjściowe, sygnatury czasowe oraz opcje. Każdy węzeł na wykresie jest
została zaimplementowana jako Calculator. Większość wykonywania grafów odbywa się wewnątrz
przy użyciu kalkulatorów. Kalkulator może odbierać zero lub więcej strumieni wejściowych lub boków
pakietów, przez co nie generuje żadnych lub więcej strumieni wyjściowych lub pakietów bocznych.
CalculatorBase
Kalkulator tworzy się przez zdefiniowanie nowej podklasy
CalculatorBase
klasy, implementując szereg metod i rejestrując nową podklasę za pomocą
Mediapipe. Nowy kalkulator musi implementować co najmniej 4 metody wymienione poniżej
GetContract()- Autorzy kalkulatora mogą określać oczekiwane typy danych wejściowych i wyjściowych kalkulatora w GetContract(). Przy inicjowaniu wykresu platforma wywołuje metodę statyczną, aby sprawdzić, czy typy pakietów połączone dane wejściowe i wyjściowe pasują do informacji w tym specyfikacji.
Open()- Po rozpoczęciu wykresu platforma wywołuje funkcję
Open(). Strona wejściowa pakiety są dostępne dla kalkulatora.Open()interpretuje operacje konfiguracji węzłów (patrz Wykresy). i przygotowuje stan poszczególnych uruchomień kalkulatora na wykresie. Ta funkcja może zapisuje też pakiety na dane wyjściowe kalkulatora. Błąd w trakcieOpen()może i przerywać działanie wykresu.
- Po rozpoczęciu wykresu platforma wywołuje funkcję
Process()- W przypadku kalkulatora z danymi wejściowymi platforma wielokrotnie wywołuje funkcję
Process()gdy co najmniej jeden strumień wejściowy ma dostępny pakiet. Struktura domyślnie gwarantuje, że wszystkie dane wejściowe mają tę samą sygnaturę czasową (patrz Synchronizacja). WieleProcess()wywołań może być wywoływane jednocześnie przy wykonywaniu równoległym jest włączona. Jeśli podczasProcess()wystąpi błąd, platforma wywołujeClose()i przebieg wykresu zostaje zakończona.
- W przypadku kalkulatora z danymi wejściowymi platforma wielokrotnie wywołuje funkcję
Close()- Po zakończeniu wszystkich połączeń z urządzeniem
Process()lub po zamknięciu wszystkich strumieni danych wejściowych: platforma nazywaClose(). Ta funkcja jest zawsze wywoływana, jeśli FunkcjaOpen()została wywołana i zakończyła się powodzeniem, a nawet po zakończeniu działania wykresu z powodu błędu. Brak dostępnych danych wejściowych przez strumienie wejściowe w czasieClose(), ale nadal ma dostęp do pakietów wejściowych po stronie i więc może zapisywać dane wyjściowe. GdyClose()zwróci wartość, kalkulator należy uznać za martwy węzeł. Obiekt kalkulatora jest zniszczony jako po zakończeniu tworzenia wykresu.
- Po zakończeniu wszystkich połączeń z urządzeniem
Oto fragmenty kodu z: CalculatorBase.h
class CalculatorBase {
public:
...
// The subclasses of CalculatorBase must implement GetContract.
// ...
static absl::Status GetContract(CalculatorContract* cc);
// Open is called before any Process() calls, on a freshly constructed
// calculator. Subclasses may override this method to perform necessary
// setup, and possibly output Packets and/or set output streams' headers.
// ...
virtual absl::Status Open(CalculatorContext* cc) {
return absl::OkStatus();
}
// Processes the incoming inputs. May call the methods on cc to access
// inputs and produce outputs.
// ...
virtual absl::Status Process(CalculatorContext* cc) = 0;
// Is called if Open() was called and succeeded. Is called either
// immediately after processing is complete or after a graph run has ended
// (if an error occurred in the graph). ...
virtual absl::Status Close(CalculatorContext* cc) {
return absl::OkStatus();
}
...
};
Jak działa kalkulator
Podczas inicjowania grafu MediaPipe platforma wywołuje
GetContract() metody statycznej do określania, jakie rodzaje pakietów są oczekiwanych.
Platforma tworzy i niszczy cały kalkulator dla każdego uruchomienia grafu (np. raz na film lub obraz). drogie lub duże przedmioty, które pozostają; stałe na wykresie należy przekazywać jako pakiety po stronie wejściowej, tak aby obliczenia nie są powtarzane przy kolejnych uruchomieniach.
Po zainicjowaniu każdego uruchomienia wykresu następuje taka sekwencja:
Open()Process()(powtarzanie)Close()
Aby zainicjować kalkulator, platforma wywołuje metodę Open(). Open() powinien
zinterpretować wszystkie opcje i skonfigurować stan poszczególnych uruchomień kalkulatora na wykresie. Open()
może uzyskiwać pakiety po stronie wejściowej i zapisywać pakiety na potrzeby danych wyjściowych kalkulatora. Jeśli
odpowiednie, powinien wywoływać metodę SetOffset(), by ograniczyć potencjalne buforowanie pakietów
strumieni wejściowych.
Jeśli podczas działania Open() lub Process() wystąpi błąd (jak wskazuje jedna z tych opcji)
zwrócony stan inny niż Ok), wykres zostanie zakończony bez dalszych wywołań
do metod kalkulatora, co spowoduje zniszczenie go.
W przypadku kalkulatora z danymi wejściowymi platforma wywołuje Process(), jeśli co najmniej
jedno z danych wejściowych ma dostępny pakiet. Platforma gwarantuje, że wszystkie dane wejściowe mają
tę samą sygnaturę czasową, która zwiększa się z każdym wywołaniem funkcji Process() oraz
że wszystkie pakiety zostały dostarczone. W rezultacie niektóre dane wejściowe mogą nie mieć
pakiety po wywołaniu funkcji Process(). Dane wejściowe, których brakuje pakietu, wydają się
generują pusty pakiet (bez sygnatury czasowej).
Platforma wywołuje Close() po wszystkich wywołaniach Process(). Wszystkie dane wejściowe będą
został wyczerpany, ale Close() ma dostęp do pakietów wejściowych i może
i zapisywania danych wyjściowych. Po zwróceniu funkcji Zamknij kalkulator zostaje zniszczony.
Kalkulatory bez danych wejściowych są nazywane źródłami. Kalkulator źródeł
funkcja Process() jest nadal wywoływana, dopóki zwraca stan Ok. O
kalkulator źródła wskazuje, że jest wyczerpany przez zwrócenie stanu zatrzymania
(np. mediaPipe::tool::StatusStop()).
Identyfikowanie danych wejściowych i wyjściowych
Publiczny interfejs kalkulatora składa się ze strumienia wejściowego oraz
strumienie wyjściowe. W konfiguracji CalculatorGraphConfiguration dane wyjściowe z niektórych
kalkulatory są połączone z danymi wejściowymi innych kalkulatorów przy użyciu nazwanych
strumienie. Nazwy strumieni mają zwykle małe litery, a tagi wejściowe i wyjściowe –
WIELKIE LITERY. W poniższym przykładzie dane wyjściowe z tagiem VIDEO to:
połączone z danymi wejściowymi za pomocą tagu o nazwie VIDEO_IN za pomocą strumienia o nazwie
video_stream
# Graph describing calculator SomeAudioVideoCalculator
node {
calculator: "SomeAudioVideoCalculator"
input_stream: "INPUT:combined_input"
output_stream: "VIDEO:video_stream"
}
node {
calculator: "SomeVideoCalculator"
input_stream: "VIDEO_IN:video_stream"
output_stream: "VIDEO_OUT:processed_video"
}
Strumienie wejściowe i wyjściowe można identyfikować według numeru indeksu, nazwy tagu lub
kombinacji nazwy tagu i numeru indeksu. Możesz zobaczyć kilka przykładów
identyfikatorów wyjściowych w podanym niżej przykładzie. SomeAudioVideoCalculator identyfikuje
jego wyjścia wideo według tagu i wyjścia audio za pomocą kombinacji tagów i tagów
indeksu. Źródło danych z tagiem VIDEO jest połączone ze strumieniem o nazwie
video_stream Dane wyjściowe z tagiem AUDIO i indeksami 0 i 1 są
połączony ze strumieniami o nazwach audio_left i audio_right.
Interfejs SomeAudioCalculator identyfikuje wejścia audio tylko na podstawie indeksu (tagi nie są potrzebne).
# Graph describing calculator SomeAudioVideoCalculator
node {
calculator: "SomeAudioVideoCalculator"
input_stream: "combined_input"
output_stream: "VIDEO:video_stream"
output_stream: "AUDIO:0:audio_left"
output_stream: "AUDIO:1:audio_right"
}
node {
calculator: "SomeAudioCalculator"
input_stream: "audio_left"
input_stream: "audio_right"
output_stream: "audio_energy"
}
W implementacji kalkulatora dane wejściowe i wyjściowe są również wskazywane przez tag nazwę i numer indeksu. W poniższej funkcji identyfikowane są dane wejściowe i wyjściowe:
- Według numeru indeksu: połączony strumień danych wejściowych jest identyfikowany po prostu przez indeks
0 - Według nazwy tagu: strumień wyjścia wideo jest identyfikowany przez nazwę tagu „VIDEO”.
- Według nazwy tagu i numeru indeksu: wyjściowe strumienie audio są identyfikowane przez tag
kombinacji nazwy tagu
AUDIOi numerów indeksu0i1.
// c++ Code snippet describing the SomeAudioVideoCalculator GetContract() method
class SomeAudioVideoCalculator : public CalculatorBase {
public:
static absl::Status GetContract(CalculatorContract* cc) {
cc->Inputs().Index(0).SetAny();
// SetAny() is used to specify that whatever the type of the
// stream is, it's acceptable. This does not mean that any
// packet is acceptable. Packets in the stream still have a
// particular type. SetAny() has the same effect as explicitly
// setting the type to be the stream's type.
cc->Outputs().Tag("VIDEO").Set<ImageFrame>();
cc->Outputs().Get("AUDIO", 0).Set<Matrix>();
cc->Outputs().Get("AUDIO", 1).Set<Matrix>();
return absl::OkStatus();
}
Przetwarzam
Funkcja Process() wywołana w węźle innym niż źródłowy musi zwrócić absl::OkStatus() do
oznacza, że wszystko poszło dobrze, lub inny kod stanu sygnalizujący błąd.
Jeśli kalkulator inny niż źródłowy zwraca wartość tool::StatusStop(), sygnalizuje to funkcji
wykres jest wczesne anulowanie. W tym przypadku wszystkie kalkulatory źródłowe i wykresy
strumienie wejściowe zostaną zamknięte (a pozostałe pakiety będą propagowane przez
wykres).
Węzeł źródłowy na wykresie będzie nadal wywoływać funkcję Process() tak długo, jak długo
(zwraca absl::OkStatus(). Aby wskazać, że nie ma więcej danych do wyświetlenia
wygenerowany zwrot tool::StatusStop(). Jakikolwiek inny stan oznacza, że wystąpił błąd
.
Close() zwraca wartość absl::OkStatus(), co oznacza sukces. Dowolny inny stan
oznacza błąd.
Oto podstawowa funkcja Process(). Wykorzystuje metodę Input() (która może
w przypadku, gdy kalkulator ma pojedyncze dane wejściowe) do żądania danych wejściowych. it
a następnie używa std::unique_ptr, aby przydzielać pamięć niezbędną dla pakietu wyjściowego,
i przeprowadza obliczenia. Gdy to zrobisz, wskaźnik zostanie zwolniony podczas dodawania elementu do
w strumieniu wyjściowym.
absl::Status MyCalculator::Process() {
const Matrix& input = Input()->Get<Matrix>();
std::unique_ptr<Matrix> output(new Matrix(input.rows(), input.cols()));
// do your magic here....
// output->row(n) = ...
Output()->Add(output.release(), InputTimestamp());
return absl::OkStatus();
}
Opcje kalkulatora
Kalkulatory akceptują parametry przetwarzania przez (1) pakiety strumienia wejściowego (2)
oraz (3) opcje kalkulatora. opcje kalkulatora, jeśli
są określone, występują jako wartości literału w polu node_options argumentu
CalculatorGraphConfiguration.Node wiadomość.
node {
calculator: "TfLiteInferenceCalculator"
input_stream: "TENSORS:main_model_input"
output_stream: "TENSORS:main_model_output"
node_options: {
[type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] {
model_path: "mediapipe/models/detection_model.tflite"
}
}
}
Pole node_options akceptuje składnię proto3. Albo kalkulator,
opcje można określić w polu options za pomocą składni proto2.
node {
calculator: "TfLiteInferenceCalculator"
input_stream: "TENSORS:main_model_input"
output_stream: "TENSORS:main_model_output"
node_options: {
[type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] {
model_path: "mediapipe/models/detection_model.tflite"
}
}
}
Nie wszystkie kalkulatory obsługują opcje kalkulatora. Aby zaakceptować opcje,
kalkulator zwykle zdefiniuje nowy typ komunikatu protokołu protobuf, który będzie reprezentował jego
opcje, takie jak PacketClonerCalculatorOptions. Kalkulator wtedy
odczytają ten komunikat buforowania za pomocą metody CalculatorBase::Open i prawdopodobnie
również w jej funkcji CalculatorBase::GetContract lub
CalculatorBase::Process. Zwykle nowy typ wiadomości protobuf
być zdefiniowane jako schemat protokołu protobuf za pomocą pliku „.proto” i
mediapipe_proto_library() reguła kompilacji.
mediapipe_proto_library(
name = "packet_cloner_calculator_proto",
srcs = ["packet_cloner_calculator.proto"],
visibility = ["//visibility:public"],
deps = [
"//mediapipe/framework:calculator_options_proto",
"//mediapipe/framework:calculator_proto",
],
)
Przykładowy kalkulator
W tej sekcji omawiamy implementację PacketClonerCalculator, która
to stosunkowo proste zadanie i jest używane w wielu kalkulatorach na wykresie.
PacketClonerCalculator po prostu tworzy kopię swoich najnowszych pakietów wejściowych
na żądanie.
Funkcja PacketClonerCalculator jest przydatna, gdy sygnatury czasowe napływających pakietów danych
nie są idealnie dopasowane. Załóżmy, że w pomieszczeniu jest mikrofon, światło
czujnik i kamerę wideo zbierającą dane sensoryczne. Każdy czujnik
działa niezależnie i zbiera dane z przerwami. Załóżmy, że dane wyjściowe
każdego czujnika to:
- mikrofon = głośność w decybelach dźwięku w pomieszczeniu (liczba całkowita)
- czujnik światła = jasność pomieszczenia (liczba całkowita)
- kamera wideo = ramka obrazu RGB pokoju (ImageFrame)
Nasz prosty potok percepcyjny ma przetwarzać dane sensoryczne dzięki czemu w każdej chwili, gdy mamy dostęp do danych ramki obrazu jest zsynchronizowany z ostatnio zebranymi danymi dotyczącymi głośności i światła mikrofonu dane o jasności czujnika. W tym celu MediaPipe mamy do dyspozycji 3 elementy strumienie wejściowe:
- Room_mic_signal – każdy pakiet danych w tym strumieniu wejściowym to dane całkowite informujące, jak głośny jest dźwięk w pomieszczeniu, wraz z sygnaturą czasową.
- Room_lightening_sensor – każdy pakiet danych w tym strumieniu danych wejściowych jest liczbą całkowitą dane, które pokazują, jak jasne jest pomieszczenie, wraz z sygnaturą czasową.
- Room_video_tick_signal – Każdy pakiet danych w tym strumieniu danych wejściowych jest ramka obrazu danych wideo reprezentująca film zebrany z kamery w sala z sygnaturą czasową.
Poniżej znajduje się implementacja PacketClonerCalculator. Możesz zobaczyć,
GetContract(), Open() i Process(), a także instancję
zmienna current_, która zawiera najnowsze pakiety wejściowe.
// This takes packets from N+1 streams, A_1, A_2, ..., A_N, B.
// For every packet that appears in B, outputs the most recent packet from each
// of the A_i on a separate stream.
#include <vector>
#include "absl/strings/str_cat.h"
#include "mediapipe/framework/calculator_framework.h"
namespace mediapipe {
// For every packet received on the last stream, output the latest packet
// obtained on all other streams. Therefore, if the last stream outputs at a
// higher rate than the others, this effectively clones the packets from the
// other streams to match the last.
//
// Example config:
// node {
// calculator: "PacketClonerCalculator"
// input_stream: "first_base_signal"
// input_stream: "second_base_signal"
// input_stream: "tick_signal"
// output_stream: "cloned_first_base_signal"
// output_stream: "cloned_second_base_signal"
// }
//
class PacketClonerCalculator : public CalculatorBase {
public:
static absl::Status GetContract(CalculatorContract* cc) {
const int tick_signal_index = cc->Inputs().NumEntries() - 1;
// cc->Inputs().NumEntries() returns the number of input streams
// for the PacketClonerCalculator
for (int i = 0; i < tick_signal_index; ++i) {
cc->Inputs().Index(i).SetAny();
// cc->Inputs().Index(i) returns the input stream pointer by index
cc->Outputs().Index(i).SetSameAs(&cc->Inputs().Index(i));
}
cc->Inputs().Index(tick_signal_index).SetAny();
return absl::OkStatus();
}
absl::Status Open(CalculatorContext* cc) final {
tick_signal_index_ = cc->Inputs().NumEntries() - 1;
current_.resize(tick_signal_index_);
// Pass along the header for each stream if present.
for (int i = 0; i < tick_signal_index_; ++i) {
if (!cc->Inputs().Index(i).Header().IsEmpty()) {
cc->Outputs().Index(i).SetHeader(cc->Inputs().Index(i).Header());
// Sets the output stream of index i header to be the same as
// the header for the input stream of index i
}
}
return absl::OkStatus();
}
absl::Status Process(CalculatorContext* cc) final {
// Store input signals.
for (int i = 0; i < tick_signal_index_; ++i) {
if (!cc->Inputs().Index(i).Value().IsEmpty()) {
current_[i] = cc->Inputs().Index(i).Value();
}
}
// Output if the tick signal is non-empty.
if (!cc->Inputs().Index(tick_signal_index_).Value().IsEmpty()) {
for (int i = 0; i < tick_signal_index_; ++i) {
if (!current_[i].IsEmpty()) {
cc->Outputs().Index(i).AddPacket(
current_[i].At(cc->InputTimestamp()));
// Add a packet to output stream of index i a packet from inputstream i
// with timestamp common to all present inputs
} else {
cc->Outputs().Index(i).SetNextTimestampBound(
cc->InputTimestamp().NextAllowedInStream());
// if current_[i], 1 packet buffer for input stream i is empty, we will set
// next allowed timestamp for input stream i to be current timestamp + 1
}
}
}
return absl::OkStatus();
}
private:
std::vector<Packet> current_;
int tick_signal_index_;
};
REGISTER_CALCULATOR(PacketClonerCalculator);
} // namespace mediapipe
Zwykle kalkulator ma tylko plik .cc. Rozszerzenie .h nie jest wymagane, ponieważ Mediapipe wykorzystuje rejestrację, aby przekazać jej kalkulatory. Po zdefiniowano klasę kalkulatora, zarejestruj ją za pomocą wywołania makra REGISTER_CALCULATOR(calculator_class_name).
Poniżej znajduje się trywialny wykres MediaPipe, który ma 3 strumienie wejściowe, 1 węzeł (PacketClonerCalculator) i 2 strumienie wyjściowe.
input_stream: "room_mic_signal"
input_stream: "room_lighting_sensor"
input_stream: "room_video_tick_signal"
node {
calculator: "PacketClonerCalculator"
input_stream: "room_mic_signal"
input_stream: "room_lighting_sensor"
input_stream: "room_video_tick_signal"
output_stream: "cloned_room_mic_signal"
output_stream: "cloned_lighting_sensor"
}
Poniższy diagram pokazuje, jak PacketClonerCalculator definiuje swoje dane wyjściowe
pakietów (u dołu) na podstawie serii pakietów wejściowych (u góry).
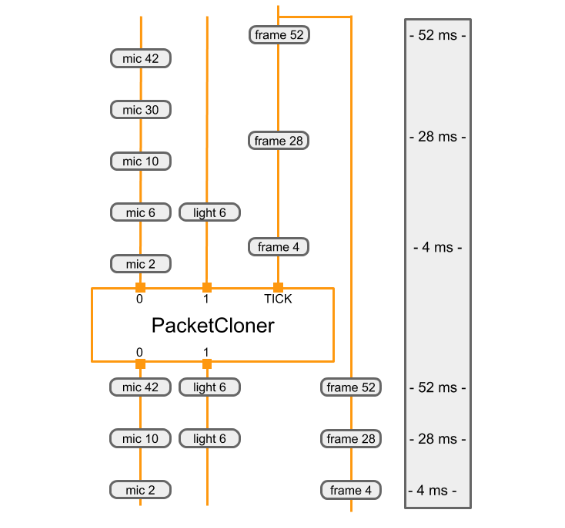 |
|---|
| Za każdym razem, gdy odbiera pakiet do strumienia wejściowego TICK, narzędzie PacketClonerCalculator na wyjściu generuje najnowszy pakiet z każdego strumienia wejściowego. Sekwencja pakietów wyjściowych (u dołu) jest określana na podstawie sekwencji pakietów wejściowych (u góry) i ich sygnatur czasowych. Sygnatury czasowe są wyświetlane po prawej stronie diagramu. |