Generowanie obrazów za pomocą Nano Banana
- Możesz też utworzyć własną na podstawie promptów:
-








-
Wygenerowano za pomocą Nano Banana 2 Prompt: „Zdjęcie błyszczącej okładki magazynu. Minimalistyczna niebieska okładka z dużym, pogrubionym napisem Nano Banana. Tekst jest wyświetlany czcionką szeryfową i wypełnia widok. Brak innego tekstu. Przed tekstem znajduje się portret osoby w eleganckiej, minimalistycznej sukience. Kobieta w zabawny sposób trzyma cyfrę 2, która jest punktem centralnym.
Umieść numer wydania i datę „luty 2026 r.” w rogu wraz z kodem kreskowym. Magazyn leży na półce przy pomarańczowej ścianie w markowym sklepie”. -
Wygenerowano za pomocą Nano Banana Pro Prompt: „Przedstaw wyraźną, izometryczną miniaturową scenę z kreskówki w 3D z widokiem z góry pod kątem 45° przedstawiającą Londyn z jego najbardziej charakterystycznymi zabytkami i elementami architektonicznymi. Używaj miękkich, dopracowanych tekstur z realistycznymi materiałami PBR oraz delikatnego, realistycznego oświetlenia i cieni. Zintegruj bieżące warunki pogodowe bezpośrednio ze środowiskiem miejskim, aby stworzyć wciągającą atmosferę. Zastosuj czystą, minimalistyczną kompozycję z miękkim, jednolitym tłem. U góry na środku umieść tytuł „Londyn” dużym pogrubionym tekstem, pod nim widoczną ikonę pogody, a następnie datę (mały tekst) i temperaturę (średni tekst). Cały tekst musi być wyśrodkowany i mieć spójne odstępy. Może nieznacznie nachodzić na górę budynków”. -
Wygenerowano za pomocą Nano Banana 2 Prompt: „Użyj wyszukiwarki obrazów, aby znaleźć dokładne zdjęcia kwezala herbowego. Utwórz piękną tapetę w formacie 3:2 z tym ptakiem, z naturalnym gradientem od góry do dołu i minimalistyczną kompozycją”. -

Wygenerowano za pomocą Nano Banana Pro Prompt: „Umieść to logo w reklamie perfum o zapachu banana z wyższej półki. Logo jest doskonale zintegrowane z butelką”. -
Wygenerowano za pomocą Nano Banana Pro Prompt: „Zdjęcie przedstawiające codzienną scenę w tętniącej życiem kawiarni serwującej śniadania. Na pierwszym planie znajduje się mężczyzna z anime z niebieskimi włosami, jedna z osób jest szkicem ołówkiem, a inna jest postacią z animacji poklatkowej. -
Wygenerowano za pomocą Nano Banana Pro Prompt: „Użyj wyszukiwarki, aby dowiedzieć się, jak przyjęto wprowadzenie na rynek Gemini 3 Flash. Wykorzystaj te informacje, aby napisać krótki artykuł (z nagłówkami). Zwróć zdjęcie artykułu w formie, w jakiej ukazał się w eleganckim magazynie o tematyce związanej z projektowaniem. Jest to zdjęcie pojedynczej złożonej strony z artykułem o Gemini 3 Flash. jedno zdjęcie główne, Nagłówek w szeryfowej czcionce”. -
Wygenerowano za pomocą Nano Banana Pro Prompt: „Ikona przedstawiająca uroczego psa. Tło jest białe. Stwórz ikony w kolorowym i wyrazistym stylu 3D. Brak tekstu”. -
Wygenerowano za pomocą Nano Banana 2 Prompt: „Utwórz zdjęcie, które będzie idealnie izometryczne. To nie jest miniatura, tylko zrobione zdjęcie, które akurat jest idealnie izometryczne. To zdjęcie pięknego nowoczesnego ogrodu. Jest tam duży basen w kształcie cyfry 2 i napis: Nano Banana 2.
Nano Banana to nazwa natywnych funkcji Gemini do generowania obrazów. Gemini może generować i przetwarzać obrazy w formie konwersacji za pomocą tekstu, obrazów lub kombinacji obu tych elementów. Dzięki temu możesz tworzyć, edytować i ulepszać obrazy z niespotykaną dotąd kontrolą.
Nano Banana to 2 różne modele dostępne w Gemini API:
- Nano Banana 2: model Gemini 3.1 Flash Image (
gemini-3.1-flash-image). Ten model jest wysoce wydajnym odpowiednikiem modelu Gemini 3 Pro Image, zoptymalizowanym pod kątem szybkości i dużej liczby przypadków użycia przez deweloperów. - Nano Banana Pro: model Gemini 3 Pro Image (
gemini-3-pro-image). Ten model został zaprojektowany z myślą o profesjonalnym tworzeniu zasobów. Wykorzystuje zaawansowane wnioskowanie („Myślący”), aby wykonywać złożone instrukcje i renderować tekst o wysokiej wierności. - Nano Banana: model Gemini 2.5 Flash Image (
gemini-2.5-flash-image). Ten model został zaprojektowany z myślą o szybkości i wydajności oraz zoptymalizowany pod kątem zadań o dużej objętości i krótkim czasie oczekiwania.
Wszystkie wygenerowane obrazy zawierają znak wodny SynthID.
Generowanie obrazów (zamiana tekstu na obraz)
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme";
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}'
Dane wygenerowanego obrazu możesz pobrać za pomocą właściwości interaction.output_image, która zwraca ostatni blok wygenerowanego obrazu. Więcej informacji o właściwościach ułatwiających korzystanie z usługi znajdziesz w omówieniu interakcji.
Edytowanie obrazów (tekst i obraz na obraz)
Przypomnienie: upewnij się, że masz wymagane prawa do wszystkich przesyłanych obrazów. Nie twórz treści naruszających prawa innych osób, w tym filmów ani obrazów, które mogą zostać wykorzystane do oszustwa, nękania lub wyrządzania krzywdy. Korzystanie z tej usługi generatywnej AI podlega naszym Zasadom dotyczącym niedozwolonych zastosowań.
Prześlij obraz i użyj promptów tekstowych, aby dodać, usunąć lub zmodyfikować elementy, zmienić styl lub dostosować korekcję kolorów.
Poniższy przykład pokazuje przesyłanie obrazów zakodowanych w formacie base64.
Więcej informacji o wielu obrazach, większych ładunkach i obsługiwanych typach MIME znajdziesz na stronie Rozumienie obrazów.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open("/path/to/cat_image.png", "rb") as f:
image_bytes = f.read()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "path/to/cat_image.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ type: "text", text: "Create a picture of my cat eating a nano-banana in a" +
"fancy restaurant under the Gemini constellation" },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation\"},
{
\"type\": \"image\",
\"mime_type\": \"image/jpeg\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
]
}"
Wieloetapowa edycja obrazów
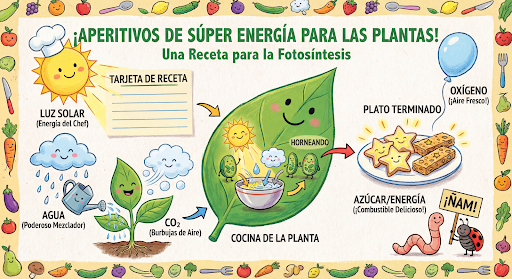
Kontynuuj generowanie i edytowanie obrazów w formie konwersacji. Wieloetapowa rozmowa to zalecany sposób iteracyjnego tworzenia obrazów. Poniższy przykład pokazuje prompta do wygenerowania infografiki na temat fotosyntezy.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools=[{"type": "google_search"}],
)
with open("photosynthesis.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const ai = new GoogleGenAI({});
async function main() {
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools: [{"type": "google_search"}],
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis.png", buffer);
console.log("Image saved as photosynthesis.png");
}
}
await main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plants favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids cookbook, suitable for a 4th grader."}
],
"tools": [{"type": "google_search"}]
}'

Następnie możesz użyć ikony previous_interaction_id, aby zmienić język na grafice na hiszpański.
Python
interaction_2 = client.interactions.create(
model="gemini-3.1-flash-image",
input="Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id=interaction.id,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
},
)
generated_image = interaction_2.output_image
if generated_image:
with open("photosynthesis_spanish.png", "wb") as f:
f.write(base64.b64decode(generated_image.data))
JavaScript
const interaction2 = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id: interaction.id,
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const generatedImage = interaction2.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis_spanish.png", buffer);
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Update this infographic to be in Spanish. Do not change any other elements of the image.",
"previous_interaction_id": "<PREVIOUS_INTERACTION_ID>",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
Nowości w modelach Gemini 3 Image
Gemini 3 oferuje najnowocześniejsze modele do generowania i edytowania obrazów. Gemini 3.1 Flash Image jest zoptymalizowany pod kątem szybkości i dużej liczby przypadków użycia, a Gemini 3 Pro Image – pod kątem profesjonalnego tworzenia zasobów. Zostały one zaprojektowane do wykonywania najbardziej wymagających przepływów pracy dzięki zaawansowanemu wnioskowaniu. Doskonale radzą sobie ze złożonymi, wieloetapowymi zadaniami tworzenia i modyfikowania.
- Wyjście w wysokiej rozdzielczości: wbudowane funkcje generowania obrazów w rozdzielczości 1K, 2K i 4K.
- Gemini 3.1 Flash Image dodaje mniejszą rozdzielczość 512 pikseli (0,5K).
- Zaawansowane renderowanie tekstu: umożliwia generowanie czytelnego, stylizowanego tekstu do infografik, menu, diagramów i materiałów marketingowych.
- Powiązanie ze źródłem informacji przy użyciu wyszukiwarki Google: model może używać wyszukiwarki Google jako narzędzia do weryfikowania faktów i generowania obrazów na podstawie danych w czasie rzeczywistym (np. aktualnych map pogody, wykresów akcji, ostatnich wydarzeń).
- Gemini 3.1 Flash Image dodaje integrację z wyszukiwarką obrazów Google Grounding oraz wyszukiwarką internetową.
- Tryb myślenia: model wykorzystuje proces „myślenia”, aby analizować złożone prompty. Generuje tymczasowe „obrazy myśli” (widoczne w backendzie, ale nie są naliczane), aby dopracować kompozycję przed wygenerowaniem końcowego obrazu wysokiej jakości.
- Do 14 obrazów referencyjnych: możesz teraz łączyć maksymalnie 14 obrazów referencyjnych, aby uzyskać obraz końcowy.
- Nowe współczynniki proporcji: Gemini 3.1 Flash Image dodaje współczynniki proporcji 1:4, 4:1, 1:8 i 8:1.
Używaj maksymalnie 14 obrazów referencyjnych
Modele obrazów Gemini 3 umożliwiają łączenie maksymalnie 14 obrazów referencyjnych. Te 14 obrazów może obejmować:
| Gemini 3.1 Flash Image | Gemini 3 Pro Image |
|---|---|
| Do 10 obrazów obiektów o wysokiej jakości, które mają zostać uwzględnione na obrazie końcowym | Do 6 obrazów obiektów o wysokiej jakości, które mają być uwzględnione na obrazie końcowym |
| Maksymalnie 4 zdjęcia postaci, aby zachować spójność postaci | Maksymalnie 5 zdjęć postaci, aby zachować spójność postaci |
| Nie dotyczy | Maksymalnie 3 obrazy, które będą używane jako odniesienia do stylu |
Python
from google import genai
from google.genai import types
from PIL import Image
import base64
prompt = "An office group photo of these people, they are making funny faces."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": prompt,
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
],
response_format={
"type": "image",
"aspect_ratio": "5:4",
"image_size": "2K"
},
)
with open("office.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const input = [
{
type: "text",
text: "An office group photo of these people, they are making funny faces.",
},
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile1 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile2 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile3 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile4 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile5 },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
response_format: {
type: "image",
aspect_ratio: "5:4",
image_size: "2K",
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('office.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"An office group photo of these people, they are making funny faces.\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_1>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_2>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_3>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_4>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_5>\"}
],
\"response_format\": {
\"type\": \"image\",
\"aspect_ratio\": \"5:4\",
\"image_size\": \"2K\"
}
}"

Powiązanie ze źródłem informacji przy użyciu wyszukiwarki Google
Użyj narzędzia wyszukiwarki Google, aby generować obrazy na podstawie informacji w czasie rzeczywistym, takich jak prognozy pogody, wykresy akcji czy ostatnie wydarzenia.
Pamiętaj, że podczas korzystania z powiązania ze źródłem informacji przy użyciu wyszukiwarki Google w przypadku generowania obrazów wyniki wyszukiwania oparte na obrazach nie są przekazywane do modelu generowania i są wykluczane z odpowiedzi (patrz Powiązanie ze źródłem informacji przy użyciu wyszukiwarki grafiki Google).
Python
from google import genai
from google.genai import types
import base64
prompt = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
tools=[{"type": "google_search"}],
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
},
)
with open("weather.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day",
tools: [{"type": "google_search"}],
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('weather.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"}
],
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
}
}'

Odpowiedź zawiera kroki google_search_call i google_search_result oraz wbudowane adnotacje url_citation w kroku tekstowym:
google_search_result: zawierasearch_suggestions, czyli fragment kodu HTML do renderowania sugestii wyszukiwania w interfejsie.url_citationadnotacje: wbudowane cytaty w kroku tekstowym, które łączą części odpowiedzi z ich źródłami internetowymi.
Powiązanie ze źródłem informacji przy użyciu wyszukiwarki Google (3.1 Flash)
Uziemienie za pomocą wyszukiwarki grafiki Google umożliwia modelom wykorzystywanie obrazów z internetu pobranych za pomocą wyszukiwarki grafiki Google jako kontekstu wizualnego do generowania obrazów. Wyszukiwanie obrazem to nowy typ wyszukiwania w ramach istniejącego narzędzia Powiązanie ze źródłem informacji przy użyciu wyszukiwarki Google, który działa równolegle ze standardowym wyszukiwaniem w internecie.
Aby włączyć wyszukiwanie obrazów, skonfiguruj narzędzie google_search w żądaniu do interfejsu API i określ image_search w tablicy search_types. Wyszukiwarki grafiki można używać samodzielnie lub razem z wyszukiwarką internetową.
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A detailed painting of a Timareta butterfly resting on a flower",
tools=[{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
)
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A detailed painting of a Timareta butterfly resting on a flower",
tools: [{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
});
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A detailed painting of a Timareta butterfly resting on a flower",
"tools": [{"type": "google_search", "search_types": ["web_search", "image_search"]}]
}'
Wymagania dotyczące wyświetlania
Jeśli korzystasz z wyszukiwania obrazem w ramach powiązania ze źródłem informacji przy użyciu wyszukiwarki Google, musisz wyświetlić search_suggestions z kroku google_search_result. Pełne wymagania dotyczące korzystania z usługi znajdziesz w Warunkach korzystania z usługi.
Odpowiedź
W przypadku odpowiedzi opartych na wyszukiwaniu obrazów interfejs API zwraca cytaty wbudowane i metadane atrybucji w ramach kroków odpowiedzi:
url_citationadnotacje: opisy bibliograficzne w bloku treści tekstowych w ramach elementumodel_output, które łączą wygenerowane treści z ich źródłem.google_search_result: zawierasearch_suggestions, czyli fragment kodu HTML do renderowania sugestii wyszukiwania w interfejsie.
Generowanie obrazów z filmu (3.1 Flash)
Generowanie obrazów na podstawie filmów umożliwia tworzenie nowych obrazów na podstawie kontekstu filmu jako odniesienia multimodalnego. Jest to przydatne do tworzenia wysokiej jakości miniatur filmów, plakatów kinowych, infografik podsumowujących lub nowych grafik inspirowanych sceną z filmu.
Podczas generowania model analizuje klatki filmu w kontekście, aby wyodrębnić motywy wizualne i kluczowe zdarzenia, a następnie wykorzystuje je wraz z promptem tekstowym do syntezy obrazu wyjściowego.
Możesz przekazywać publiczne adresy URL YouTube bezpośrednio w żądaniu do interfejsu API lub przesyłać lokalne pliki wideo za pomocą interfejsu Files API.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{"type": "text", "text": "Generate a poster image that captures the key themes of this video."}
],
response_format={"type": "image", "aspect_ratio": "16:9"}
)
# Save the generated image part
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("video_poster.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
print("Image saved as video_poster.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "video",
uri: "https://www.youtube.com/watch?v=UTdfxFyOQTI",
mime_type: "video/mp4"
},
{ type: "text", text: "Generate a poster image that captures the key themes of this video." }
],
response_format: {
type: "image",
aspect_ratio: "16:9"
}
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("video_poster.png", buffer);
console.log("Image saved as video_poster.png");
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{
"type": "text",
"text": "Generate a poster image that captures the key themes of this video."
}
],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

Generowanie obrazów w rozdzielczości do 4K
Modele obrazów Gemini 3 domyślnie generują obrazy o rozdzielczości 1K, ale mogą też tworzyć obrazy o rozdzielczości 2K, 4K i 512 pikseli (05.K) (tylko Gemini 3.1 Flash Image). Aby wygenerować komponenty o wyższej rozdzielczości, podaj wartość image_size w parametrze response_format.
Musisz użyć wielkiej litery „K” (np. 512px (05.K), 1K, 2K, 4K). Parametry pisane małymi literami (np.1 tys.) zostaną odrzucone.
Python
from google import genai
from google.genai import types
import base64
prompt = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
},
)
print(interaction.output_text)
with open("butterfly.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "1:1",
image_size: "1K",
},
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('butterfly.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
}
}'
Oto przykładowy obraz wygenerowany na podstawie tego prompta:

Proces myślowy
Modele obrazów Gemini 3 to modele myślące, które w przypadku złożonych promptów korzystają z procesu rozumowania („Myślenie”). Ta funkcja jest domyślnie włączona i nie można jej wyłączyć w interfejsie API. Więcej informacji o procesie myślowym znajdziesz w przewodniku Myślenie Gemini.
Model generuje maksymalnie 2 obrazy tymczasowe, aby przetestować kompozycję i logikę. Ostatni obraz w sekcji „Myślenie” jest też ostatecznym wyrenderowanym obrazem.
Możesz sprawdzić, jakie myśli doprowadziły do wygenerowania ostatecznego obrazu.
Python
for step in interaction.steps:
if step.type == "thought":
for content_block in step.summary:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
image = Image.open(io.BytesIO(base64.b64decode(content_block.data)))
image.show()
JavaScript
for (const step of interaction.steps) {
if (step.type === "thought") {
for (const contentBlock of step.summary) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, 'base64');
fs.writeFileSync('thought_image.png', buffer);
}
}
}
}
Tekst przeplatany obrazami
Standardowe modele generowania obrazów tworzą tylko obrazy, ale niektóre zaawansowane modele Gemini 3 (np. gemini-3-pro-image) mogą generować przeplatane treści, takie jak opowiadania lub przewodniki zawierające zarówno bloki tekstu, jak i ilustracje w ramach tej samej odpowiedzi.
Ponieważ dane wyjściowe są złożone i przeplatane, właściwości wygody, takie jak .output_image lub .output_text, nie obejmują całej sekwencji. Aby uzyskać dostęp do przeplatanych treści i je zapisać, musisz ręcznie iterować po steps:
Python
interaction = client.interactions.create(
model="gemini-3-pro-image",
input="Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
)
image_counter = 1
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
filename = f"butterfly_lifecycle_{image_counter}.png"
with open(filename, "wb") as f:
f.write(base64.b64decode(content_block.data))
print(f"\n[Saved illustration: {filename}]\n")
image_counter += 1
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3-pro-image",
input: "Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
});
let imageCounter = 1;
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
const filename = `butterfly_lifecycle_${imageCounter}.png`;
fs.writeFileSync(filename, buffer);
console.log(`\n[Saved illustration: ${filename}]\n`);
imageCounter++;
}
}
}
}
Sterowanie poziomami myślenia
Dzięki Gemini 3.1 Flash Image możesz kontrolować ilość „myślenia”, jaką model wykorzystuje do zachowania równowagi między jakością a czasem oczekiwania. Domyślna wartość thinking_level to minimal, a obsługiwane poziomy to minimal i high.
Python
from google import genai
from PIL import Image
import base64
import io
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A futuristic city built inside a giant glass bottle floating in space",
generation_config={"thinking_level": "high"},
)
print(interaction.output_text)
image = Image.open(io.BytesIO(base64.b64decode(interaction.output_image.data)))
image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A futuristic city built inside a giant glass bottle floating in space",
generation_config: { thinking_level: "high" },
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('image.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A futuristic city built inside a giant glass bottle floating in space",
"generation_config": {
"thinking_level": "high"
}
}'
Pamiętaj, że w przypadku modeli myślenia tokeny myślenia są domyślnie rozliczane, ponieważ proces myślenia zawsze odbywa się domyślnie, niezależnie od tego, czy go obserwujesz.
Inne tryby generowania obrazów
Modele generowania obrazów Nano Banana są zalecane w większości przypadków, ale możesz też wypróbować specjalne modele generowania obrazów:
- Imagen: modele Google do zamiany tekstu na obraz zoptymalizowane pod kątem generowania obrazów wysokiej jakości.
- Veo: model Google do generowania filmów.
Generowanie obrazów w trybie wsadowym
Wszystkie funkcje generowania obrazów opisane na tej stronie można też uruchamiać jako zadania wsadowe za pomocą wsadowego interfejsu API, co jest idealne, jeśli musisz wygenerować wiele obrazów.W zamian za czas realizacji do 24 godzin otrzymujesz wyższe limity żądań.
Przewodnik po promptach i strategiach
W tej sekcji znajdziesz przykłady promptów i szablony do typowych procesów generowania i edytowania obrazów. Każdy przykład zawiera szablon wielokrotnego użytku i przykładowy prompt dla interfejsu Interactions API.
Prompty do generowania obrazów
Przykłady poniżej pokazują, jak za pomocą promptów tekstowych generować różne rodzaje obrazów.
1. Fotorealistyczne sceny
Opisz szczegółowo scenę. Im bardziej szczegółowe informacje podasz, tym większą będziesz mieć kontrolę nad wynikami.
Szablon
A photorealistic [type of shot] of a [subject description] in a [setting
description]. [Description of the light]. Shot from a [camera angle]
with a [lens type].
Prompt
A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format=[
{
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
}
],
)
print(interaction.output_text)
with open("coral_reef.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format: [
{
type: "image",
mime_type: "image/jpeg",
aspect_ratio: "16:9",
}
],
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('coral_reef.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
"response_format": {
"type": "image",
"mime_type": "image/png",
"aspect_ratio": "16:9"
}
}'

2. Stylizowane ilustracje i naklejki
Opisz styl artystyczny, temat i medium. Aby uzyskać spójne wyniki, podaj szczegółowe informacje o elementach wizualnych (grube linie, kolory itp.).
Szablon
A [style] of a [subject, with details about accessories or actions]
doing [activity]. The design features [visual qualities, e.g., bold outlines,
cel-shading, etc.] and [color/background preference].
Prompt
A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("red_panda_sticker.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("red_panda_sticker.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It is munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white."
}'

3. Dokładny tekst na obrazach
Gemini świetnie radzi sobie z renderowaniem tekstu. Opisz dokładnie tekst, styl czcionki i ogólny projekt. Używaj Gemini 3 Pro Image do profesjonalnego tworzenia zasobów.
Szablon
Create a [image type] for [brand/concept] with the text "[text to render]"
in a [font style]. The design should be [style description], with a
[color scheme].
Prompt
Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format={"type": "image", "aspect_ratio": "1:1"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("logo_example.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format: { type: "image", aspect_ratio: "1:1" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("logo_example.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a modern, minimalist logo for a coffee shop called The Daily Grind. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
"response_format": {
"type": "image",
"aspect_ratio": "1:1"
}
}'
4. Makiety produktów i fotografia komercyjna
Idealne do tworzenia czystych, profesjonalnych zdjęć produktów na potrzeby e-commerce, reklam i brandingu.
Szablon
A high-resolution, studio-lit product photograph of a [product description]
on a [background surface/description]. The lighting is a [lighting setup,
e.g., three-point softbox setup] to [lighting purpose]. The camera angle is
a [angle type] to showcase [specific feature]. Ultra-realistic, with sharp
focus on [key detail]. [Aspect ratio].
Prompt
A high-resolution, studio-lit product photograph of a minimalist ceramic
coffee mug in matte black, presented on a polished concrete surface. The
lighting is a three-point softbox setup designed to create soft, diffused
highlights and eliminate harsh shadows. The camera angle is a slightly
elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with
sharp focus on the steam rising from the coffee. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("product_mockup.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("product_mockup.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image."
}'

5. Minimalistyczny projekt z negatywną przestrzenią
Doskonale nadaje się do tworzenia tła stron internetowych, prezentacji lub materiałów marketingowych, na których będzie wyświetlany tekst.
Szablon
A minimalist composition featuring a single [subject] positioned in the
[bottom-right/top-left/etc.] of the frame. The background is a vast, empty
[color] canvas, creating significant negative space. Soft, subtle lighting.
[Aspect ratio].
Prompt
A minimalist composition featuring a single, delicate red maple leaf
positioned in the bottom-right of the frame. The background is a vast, empty
off-white canvas, creating significant negative space for text. Soft,
diffused lighting from the top left. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("minimalist_design.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("minimalist_design.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image."
}'

6. Sztuka sekwencyjna (panel komiksu / scenorys)
Na podstawie spójności postaci i opisu sceny tworzy panele do wizualnego opowiadania historii. Aby uzyskać dokładność tekstu i możliwość opowiadania historii, te prompty najlepiej działają z modelami Gemini 3 Pro i Gemini 3.1 Flash Image.
Szablon
Make a 3 panel comic in a [style]. Put the character in a [type of scene].
Prompt
Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/jpeg"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("comic_panel.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/man_in_white_glasses.jpg";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene." },
{
type: "image",
mime_type: "image/jpeg",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("comic_panel.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."},
{"type": "image", "data": "<BASE64_IMAGE_DATA>", "mime_type": "image/jpeg"}
]
}'
Dane wejściowe |
Dane wyjściowe |

|

|
7. Powiązanie ze źródłem informacji przy użyciu wyszukiwarki Google
Generowanie obrazów na podstawie najnowszych informacji lub danych w czasie rzeczywistym za pomocą wyszukiwarki Google. Jest to przydatne w przypadku wiadomości, prognoz pogody i innych tematów, które wymagają aktualizacji w czasie rzeczywistym.
Prompt
Make a simple but stylish graphic of last night's Arsenal game in the Champion's League
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools=[{"type": "google_search"}],
response_format={"type": "image", "aspect_ratio": "16:9"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("football-score.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools: [{ type: "google_search" }],
response_format: { type: "image", aspect_ratio: "16:9", image_size: "2K" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("football-score.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Make a simple but stylish graphic of last nights Arsenal game in the Champions League",
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

Prompty do edytowania obrazów
Te przykłady pokazują, jak przesyłać obrazy wraz z promptami tekstowymi w celu edycji, kompozycji i przenoszenia stylu.
1. Dodawanie i usuwanie elementów
Prześlij obraz i opisz zmianę. Model dopasuje styl, oświetlenie i perspektywę oryginalnego obrazu.
Szablon
Using the provided image of [subject], please [add/remove/modify] [element]
to/from the scene. Ensure the change is [description of how the change should
integrate].
Prompt
"Using the provided image of my cat, please add a small, knitted wizard hat
on its head. Make it look like it's sitting comfortably and matches the soft
lighting of the photo."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/cat_photo.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("cat_with_hat.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/cat_photo.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off." },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("cat_with_hat.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off.\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"}
]
}"
Dane wejściowe |
Dane wyjściowe |

|

|
2. Retusz (maskowanie semantyczne)
Określ „maskę” w rozmowie, aby edytować konkretną część obrazu, nie zmieniając reszty.
Szablon
Using the provided image, change only the [specific element] to [new
element/description]. Keep everything else in the image exactly the same,
preserving the original style, lighting, and composition.
Prompt
"Using the provided image of a living room, change only the blue sofa to be
a vintage, brown leather chesterfield sofa. Keep the rest of the room,
including the pillows on the sofa and the lighting, unchanged."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/living_room.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("living_room_edited.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/living_room.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("living_room_edited.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged.\"}
]
}"
Dane wejściowe |
Dane wyjściowe |

|

|
3. Przenoszenie stylu
Prześlij obraz i poproś model o odtworzenie jego treści w innym stylu artystycznym.
Szablon
Transform the provided photograph of [subject] into the artistic style of [artist/art style]. Preserve the original composition but render it with [description of stylistic elements].
Prompt
"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/city.png', 'rb') as f:
image_bytes = f.read()
text_input = """Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("city_style_transfer.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imageData = fs.readFileSync("/path/to/your/city.png");
const base64Image = imageData.toString("base64");
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows." },
],
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("city_style_transfer.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows.\"}
]
}"
Dane wejściowe |
Dane wyjściowe |

|

|
4. Zaawansowana kompozycja: łączenie wielu obrazów
Prześlij kilka obrazów jako kontekst, aby utworzyć nową, złożoną scenę. To idealne rozwiązanie w przypadku makiet produktów lub kolaży.
Szablon
Create a new image by combining the elements from the provided images. Take
the [element from image 1] and place it with/on the [element from image 2].
The final image should be a [description of the final scene].
Prompt
"Create a professional e-commerce fashion photo. Take the blue floral dress
from the first image and let the woman from the second image wear it.
Generate a realistic, full-body shot of the woman wearing the dress, with
the lighting and shadows adjusted to match the outdoor environment."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/dress.png', 'rb') as f:
dress_bytes = f.read()
with open('/path/to/your/model.png', 'rb') as f:
model_bytes = f.read()
text_input = """Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(dress_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(model_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("fashion_ecommerce_shot.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/dress.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/model.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image1
},
{
type: "image",
mime_type: "image/png",
data: base64Image2
},
{ type: "text", text: "Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("fashion_ecommerce_shot.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment.\"}
}]
}"
Dane wejściowe 1 |
Dane wejściowe 2 |
Dane wyjściowe |

|

|

|
5. Zachowanie szczegółów w wysokiej jakości
Aby mieć pewność, że ważne szczegóły (np. twarz lub logo) zostaną zachowane podczas edycji, dokładnie je opisz w prośbie o zmiany.
Szablon
Using the provided images, place [element from image 2] onto [element from
image 1]. Ensure that the features of [element from image 1] remain
completely unchanged. The added element should [description of how the
element should integrate].
Prompt
"Take the first image of the woman with brown hair, blue eyes, and a neutral
expression. Add the logo from the second image onto her black t-shirt.
Ensure the woman's face and features remain completely unchanged. The logo
should look like it's naturally printed on the fabric, following the folds
of the shirt."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/woman.png', 'rb') as f:
woman_bytes = f.read()
with open('/path/to/your/logo.png', 'rb') as f:
logo_bytes = f.read()
text_input = """Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(woman_bytes).decode('utf-8')},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(logo_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("woman_with_logo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/woman.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/logo.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image1},
{"type": "image", "mime_type":"image/png", "data": base64Image2},
{"type": "text", "text": "Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("woman_with_logo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt.\"}
]
}"
Dane wejściowe 1 |
Dane wejściowe 2 |
Dane wyjściowe |

|
|
|
6. ożywiać coś,
Prześlij szkic lub rysunek i poproś model o przekształcenie go w gotowy obraz.
Szablon
Turn this rough [medium] sketch of a [subject] into a [style description]
photo. Keep the [specific features] from the sketch but add [new details/materials].
Prompt
"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/car_sketch.png', 'rb') as f:
sketch_bytes = f.read()
text_input = """Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(sketch_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("car_photo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/car_sketch.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image},
{"type": "text", "text": "Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("car_photo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting.\"}
]
}"
Dane wejściowe |
Dane wyjściowe |

|

|
7. Spójność postaci: widok 360°
Możesz generować widoki postaci w 360 stopniach, wielokrotnie prosząc o wyświetlenie jej pod różnymi kątami. Aby uzyskać najlepsze wyniki, w kolejnych promptach uwzględniaj wygenerowane wcześniej obrazy, aby zachować spójność. W przypadku złożonych póz dołącz obraz referencyjny wybranej pozy.
Szablon
A studio portrait of [person] against [background], [looking forward/in profile looking right/etc.]
Prompt
A studio portrait of this man against white, in profile looking right
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = """A studio portrait of this man against white, in profile looking right"""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input={
{"type": "text", "text": text_input},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(image_bytes).decode('utf-8')}
},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("man_right_profile.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
Dane wejściowe |
Dane wyjściowe 1 |
Dane wyjściowe 2 |
|
|

|

|
Sprawdzone metody
Aby poprawić wyniki, zastosuj w swoim przepływie pracy te profesjonalne strategie.
- Podawaj bardzo konkretne informacje: im więcej szczegółów podasz, tym większą będziesz mieć kontrolę. Zamiast „zbroja fantasy” opisz ją: „ozdobna elfia zbroja płytowa, wyryte wzory z liści srebra, wysoki kołnierz i naramienniki w kształcie skrzydeł sokoła”.
- Podaj kontekst i cel: wyjaśnij cel obrazu. Zrozumienie kontekstu przez model wpłynie na ostateczne dane wyjściowe. Na przykład „Utwórz logo dla minimalistycznej marki kosmetyków z wyższej półki” da lepsze wyniki niż samo „Utwórz logo”.
- Powtarzaj i dopracowuj: nie oczekuj idealnego obrazu za pierwszym razem. Wykorzystaj konwersacyjny charakter modelu, aby wprowadzać drobne zmiany. Następnie możesz wydać kolejne polecenia, np. „Świetnie, ale czy możesz sprawić, żeby oświetlenie było nieco cieplejsze?” lub „Pozostaw wszystko bez zmian, ale zmień wyraz twarzy postaci na bardziej poważny”.
- Używaj instrukcji krok po kroku: w przypadku złożonych scen z wieloma elementami podziel prompt na kroki. „Najpierw utwórz tło przedstawiające spokojny, mglisty las o świcie. Następnie na pierwszym planie dodaj pokryty mchem starożytny kamienny ołtarz. Na koniec połóż na ołtarzu jeden świecący miecz”.
- Używaj „semantycznych promptów negatywnych”: zamiast pisać „bez samochodów” opisz zamierzoną scenę w sposób pozytywny: „pusta, opuszczona ulica bez śladów ruchu”.
- Sterowanie kamerą: używaj języka fotograficznego i filmowego, aby sterować kompozycją. Określenia takie jak
wide-angle shot,macro shot,low-angle perspective.
Ograniczenia
- Aby uzyskać najlepsze wyniki, używaj tych języków: EN, ar-EG, de-DE, es-MX, fr-FR, hi-IN, id-ID, it-IT, ja-JP, ko-KR, pt-BR, ru-RU, ua-UA, vi-VN, zh-CN.
- Generowanie obrazów nie obsługuje danych wejściowych audio. Dane wejściowe wideo są obsługiwane tylko w przypadku Gemini 3.1 Flash Image.
- Model nie zawsze będzie generować dokładnie taką liczbę obrazów, o jaką użytkownik wyraźnie poprosi.
gemini-2.5-flash-imagedziała najlepiej z maksymalnie 3 obrazami wejściowymi, agemini-3-pro-imageobsługuje 5 obrazów o wysokiej wierności i maksymalnie 14 obrazów.gemini-3.1-flash-imageobsługuje podobieństwo znaków do 4 znaków i wierność do 10 obiektów w ramach jednego procesu.- Podczas generowania tekstu do obrazu Gemini działa najlepiej, jeśli najpierw wygenerujesz tekst, a potem poprosisz o obraz z tym tekstem.
gemini-3.1-flash-imagePowiązanie ze źródłami informacji przy użyciu wyszukiwarki Google nie obsługuje obecnie korzystania z rzeczywistych obrazów osób z wyszukiwarki.- Wszystkie wygenerowane obrazy zawierają znak wodny SynthID.
Konfiguracje opcjonalne
Opcjonalnie możesz skonfigurować format wyjściowy, format obrazu i rozmiar obrazu za pomocą parametru response_format.
Format wyjściowy
Domyślnie model zwraca odpowiedzi tekstowe i obrazowe. Możesz skonfigurować odpowiedź tak, aby zwracała tylko wygenerowane obrazy (z pominięciem tekstu konwersacyjnego), określając format obrazu w parametrze response_format.
Aby poprosić o wiele rodzajów danych (np. tekst i wygenerowany obraz), przekaż tablicę wpisów formatu do parametru response_format.
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Write a short poem about a starry night and generate an image of it.",
response_format=[
{"type": "text"},
{"type": "image"},
],
)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Write a short poem about a starry night and generate an image of it.",
response_format: [
{ type: "text" },
{ type: "image" },
],
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Write a short poem about a starry night and generate an image of it.",
"response_format": [
{ "type": "text" },
{ "type": "image" }
]
}'
Format obrazu i rozmiar obrazu
Domyślnie model dopasowuje rozmiar obrazu wyjściowego do rozmiaru obrazu wejściowego lub generuje kwadraty o proporcjach 1:1. Współczynnik proporcji i rozmiar obrazu wyjściowego możesz kontrolować za pomocą pól aspect_ratio i image_size w sekcji response_format, gdy w polu type ustawiona jest wartość "image".
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K",
},
)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
response_format: {
type: "image",
aspect_ratio: "16:9",
image_size: "2K",
},
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
"response_format": {
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
Dostępne proporcje i rozmiar wygenerowanego obrazu znajdziesz w tabelach poniżej:
3.1 Flash Image
| Format obrazu | rozdzielczość 512 pikseli, | 500 tokenów | Rozdzielczość 1K | 1 tysiąc tokenów | Rozdzielczość 2K | 2 tys. tokenów | Rozdzielczość 4K | 4 tys. tokenów |
|---|---|---|---|---|---|---|---|---|
| 1:1 | 512 x 512 | 747 | 1024 × 1024 | 1120 | 2048 x 2048 | 1120 | 4096 x 4096 | 2000 |
| 1:4 | 256 x 1024 | 747 | 512x2048 | 1120 | 1024 x 4096 | 1120 | 2048x8192 | 2000 |
| 1:8 | 192x1536 | 747 | 384 x 3072 | 1120 | 768 x 6144 | 1120 | 1536 x 12288 | 2000 |
| 2:3 | 424 x 632 | 747 | 848 x 1264 | 1120 | 1696 x 2528 | 1120 | 3392 x 5056 | 2000 |
| 3:2 | 632 x 424 | 747 | 1264 x 848 | 1120 | 2528 x 1696 | 1120 | 5056 x 3392 | 2000 |
| 3:4 | 448 x 600 | 747 | 896 x 1200 | 1120 | 1792 x 2400 | 1120 | 3584 x 4800 | 2000 |
| 4:1 | 1024 x 256 | 747 | 2048 x 512 | 1120 | 4096 x 1024 | 1120 | 8192 x 2048 | 2000 |
| 4:3 | 600 x 448 | 747 | 1200 x 896 | 1120 | 2400 x 1792 | 1120 | 4800 x 3584 | 2000 |
| 4:5 | 464 x 576 | 747 | 928 x 1152 | 1120 | 1856 x 2304 | 1120 | 3712x4608 | 2000 |
| 5:4 | 576 x 464 | 747 | 1152 x 928 | 1120 | 2304 x 1856 | 1120 | 4608x3712 | 2000 |
| 8:1 | 1536 x 192 | 747 | 3072 x 384 | 1120 | 6144 x 768 | 1120 | 12288 x 1536 | 2000 |
| 9:16 | 384 x 688 | 747 | 768 x 1376 | 1120 | 1536 x 2752 | 1120 | 3072 x 5504 | 2000 |
| 16:9 | 688 x 384 | 747 | 1376 x 768 | 1120 | 2752x1536 | 1120 | 5504 x 3072 | 2000 |
| 21:9 | 792 x 168 | 747 | 1584 x 672 | 1120 | 3168 x 1344 | 1120 | 6336 x 2688 | 2000 |
3 Pro Image
| Format obrazu | Rozdzielczość 1K | 1 tysiąc tokenów | Rozdzielczość 2K | 2 tys. tokenów | Rozdzielczość 4K | 4 tys. tokenów |
|---|---|---|---|---|---|---|
| 1:1 | 1024 × 1024 | 1120 | 2048 x 2048 | 1120 | 4096 x 4096 | 2000 |
| 2:3 | 848 x 1264 | 1120 | 1696 x 2528 | 1120 | 3392 x 5056 | 2000 |
| 3:2 | 1264 x 848 | 1120 | 2528 x 1696 | 1120 | 5056 x 3392 | 2000 |
| 3:4 | 896 x 1200 | 1120 | 1792 x 2400 | 1120 | 3584 x 4800 | 2000 |
| 4:3 | 1200 x 896 | 1120 | 2400 x 1792 | 1120 | 4800 x 3584 | 2000 |
| 4:5 | 928 x 1152 | 1120 | 1856 x 2304 | 1120 | 3712x4608 | 2000 |
| 5:4 | 1152 x 928 | 1120 | 2304 x 1856 | 1120 | 4608x3712 | 2000 |
| 9:16 | 768 x 1376 | 1120 | 1536 x 2752 | 1120 | 3072 x 5504 | 2000 |
| 16:9 | 1376 x 768 | 1120 | 2752x1536 | 1120 | 5504 x 3072 | 2000 |
| 21:9 | 1584 x 672 | 1120 | 3168 x 1344 | 1120 | 6336 x 2688 | 2000 |
Gemini 2.5 Flash Image
| Format obrazu | Rozdzielczość | Tokeny |
|---|---|---|
| 1:1 | 1024 × 1024 | 1290 |
| 2:3 | 832 x 1248 | 1290 |
| 3:2 | 1248 x 832 | 1290 |
| 3:4 | 864 x 1184 | 1290 |
| 4:3 | 1184 x 864 | 1290 |
| 4:5 | 896 x 1152 | 1290 |
| 5:4 | 1152 x 896 | 1290 |
| 9:16 | 768 x 1344 | 1290 |
| 16:9 | 1344 x 768 | 1290 |
| 21:9 | 1536 x 672 | 1290 |
Wybór modelu
Wybierz model, który najlepiej pasuje do Twojego konkretnego zastosowania.
Gemini 3.1 Flash Image (Nano Banana 2) to model do generowania obrazów, który zapewnia najlepszą ogólną wydajność i równowagę między inteligencją a kosztem i czasem oczekiwania. Więcej informacji znajdziesz na stronie z cenami i możliwościami modeli.
Gemini 3 Pro Image (Nano Banana Pro) to model stworzony do profesjonalnego tworzenia zasobów i złożonych instrukcji. Ten model wykorzystuje informacje z wyszukiwarki Google, domyślny proces „myślenia”, który dopracowuje kompozycję przed wygenerowaniem obrazu, i może generować obrazy w rozdzielczości do 4K. Więcej informacji znajdziesz na stronie z cenami i możliwościami modeli.
Gemini 2.5 Flash Image (Nano Banana) został zaprojektowany z myślą o szybkości i wydajności. Ten model jest zoptymalizowany pod kątem zadań wymagających dużej liczby danych i krótkiego czasu oczekiwania. Generuje obrazy w rozdzielczości 1024 pikseli. Więcej informacji znajdziesz na stronie z cenami i możliwościami modelu.
Kiedy używać Imagen
Oprócz korzystania z wbudowanych funkcji generowania obrazów w Gemini możesz też uzyskać dostęp do Imagen, naszego specjalistycznego modelu generowania obrazów, za pomocą interfejsu Gemini API. Zaplanuj migrację przed datą wyłączenia.
Co dalej?
- Aby dowiedzieć się, jak generować filmy za pomocą Gemini API, zapoznaj się z przewodnikiem po Veo.
- Więcej informacji o modelach Gemini znajdziesz w artykule Modele Gemini.