
|
|
|
 Afficher la source sur GitHub Afficher la source sur GitHub
|
Présentation
Ce tutoriel explique comment visualiser et regrouper les représentations vectorielles continues de l'API Gemini. Vous allez visualiser un sous-ensemble des 20 ensembles de données Newsgroup à l'aide de t-SNE, puis regrouper ce sous-ensemble à l'aide de l'algorithme KMeans.
Pour commencer à utiliser les représentations vectorielles continues générées à partir de l'API Gemini, consultez le guide de démarrage rapide pour Python.
Prérequis
Vous pouvez suivre ce guide de démarrage rapide dans Google Colab.
Pour suivre ce guide de démarrage rapide dans votre propre environnement de développement, assurez-vous que votre environnement répond aux exigences suivantes:
- Python 3.9 ou version ultérieure
- Une installation de
jupyterpour exécuter le notebook.
Préparation
Commencez par télécharger et installer la bibliothèque Python de l'API Gemini.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
import google.ai.generativelanguage as glm
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
Obtenir une clé API
Pour pouvoir utiliser l'API Gemini, vous devez d'abord obtenir une clé API. Si vous ne possédez pas encore de clé, créez-en une en un clic dans Google AI Studio.
Dans Colab, ajoutez la clé au gestionnaire de secrets sous le bouton "EIDR" du panneau de gauche. Donnez-lui le nom API_KEY.
Une fois la clé API obtenue, transmettez-la au SDK. Pour cela, vous avez le choix entre deux méthodes :
- Placez la clé dans la variable d'environnement
GOOGLE_API_KEY(le SDK la récupérera automatiquement à partir de là). - Transmettre la clé à
genai.configure(api_key=...)
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
Ensemble de données
L'ensemble de données de texte des 20 groupes de discussion contient 18 000 messages de groupes de discussion portant sur 20 sujets,répartis en ensembles d'entraînement et de test. La répartition entre les ensembles de données d'entraînement et de test est basée sur les messages publiés avant et après une date spécifique. Pour ce tutoriel, vous utiliserez le sous-ensemble d'entraînement.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
Voici le premier exemple de l'ensemble d'entraînement.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
Vous allez ensuite échantillonner certaines données en prenant 100 points de données de l'ensemble de données d'entraînement et en supprimant quelques catégories pour suivre ce tutoriel. Choisissez les catégories scientifiques à comparer.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
Créer les représentations vectorielles continues
Dans cette section, vous allez découvrir comment générer des représentations vectorielles continues pour les différents textes du DataFrame à l'aide de celles de l'API Gemini.
Modifications apportées à l'API pour les représentations vectorielles continues avec le modèle Embedding-001
Pour le nouveau modèle de représentations vectorielles continues, Embedding-001, il existe un nouveau paramètre de type de tâche et un titre facultatif (valide uniquement si task_type=RETRIEVAL_DOCUMENT).
Ces nouveaux paramètres ne s'appliquent qu'aux modèles de représentations vectorielles continues les plus récents.Les types de tâches sont les suivants:
| Type de tâche | Description |
|---|---|
| RETRIEVAL_QUERY | Spécifie que le texte donné est une requête dans un contexte de recherche/récupération. |
| RETRIEVAL_DOCUMENT | Spécifie que le texte donné est un document dans un contexte de recherche/récupération. |
| SEMANTIC_SIMILARITY | Indique que le texte donné sera utilisé pour la similarité textuelle sémantique (STS). |
| CLASSIFICATION | Spécifie que les représentations vectorielles continues seront utilisées pour la classification. |
| CLUSTER | Spécifie que les représentations vectorielles continues seront utilisées pour le clustering. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
Réduction de la dimensionnalité
La longueur du vecteur de représentation vectorielle continue du document est de 768. Pour visualiser comment les documents intégrés sont regroupés, vous devez appliquer une réduction de la dimensionnalité, car vous ne pouvez visualiser les représentations vectorielles continues que dans un espace 2D ou 3D. Les documents contextuellement similaires devraient être plus proches les uns des autres dans l'espace, par opposition à des documents moins similaires.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
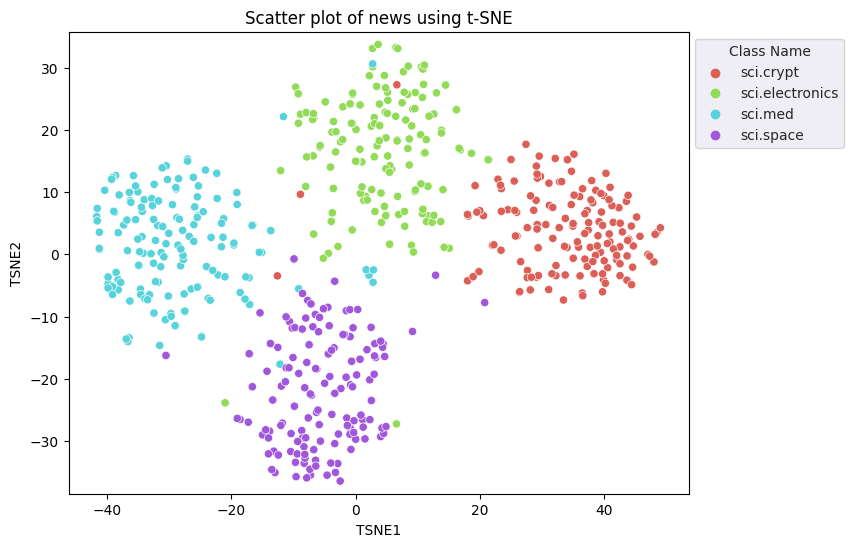
Vous allez appliquer l'approche de représentation vectorielle continue stochastique t-Distributed (t-SNE) pour réduire la dimensionnalité. Cette technique réduit le nombre de dimensions, tout en préservant les clusters (les points proches les uns des autres restent proches les uns des autres). Pour les données d'origine, le modèle tente de construire une distribution sur laquelle d'autres points de données sont "voisins" (c'est-à-dire, qui ont une signification similaire). Il optimise ensuite une fonction objectif pour conserver une distribution similaire dans la visualisation.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
Comparer les résultats aux KMEens
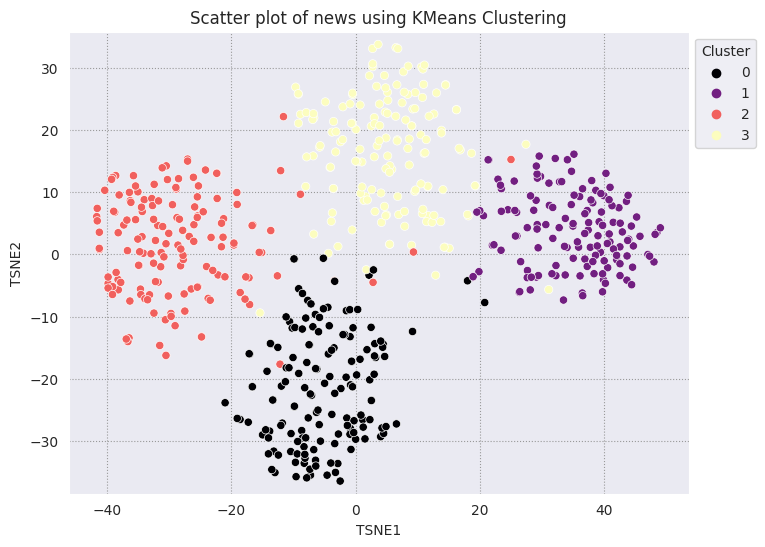
Le clustering KMS est un algorithme de clustering populaire, souvent utilisé pour l'apprentissage non supervisé. Il détermine de manière itérative les meilleurs k points centraux et attribue chaque exemple au centroïde le plus proche. Saisir les représentations vectorielles continues directement dans l'algorithme Kneans pour comparer la visualisation des représentations vectorielles continues aux performances d'un algorithme de machine learning
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
Obtenez la majorité des clusters par groupe et voyez combien de membres de ce groupe se trouvent dans ce cluster.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
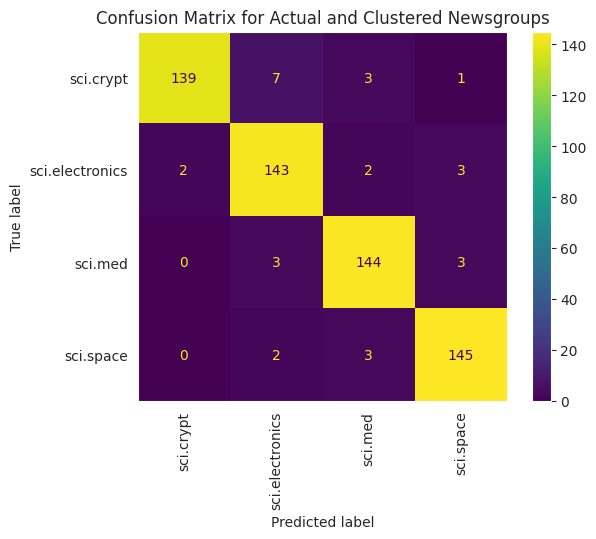
Pour mieux visualiser les performances des KLM appliqués à vos données, vous pouvez utiliser une matrice de confusion. La matrice de confusion vous permet d'évaluer les performances du modèle de classification au-delà de la justesse. Les points mal classés s'affichent. Vous aurez besoin des valeurs réelles et des valeurs prédites, que vous avez collectées dans le DataFrame ci-dessus.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
Étapes suivantes
Vous avez maintenant créé votre propre visualisation des représentations vectorielles continues avec clustering. Essayez d'utiliser vos propres données textuelles pour les visualiser sous forme de représentations vectorielles continues. Vous pouvez réduire la dimensionnalité pour terminer l'étape de visualisation. Notez que les TSNE sont efficaces pour regrouper les entrées, mais qu'ils peuvent mettre plus de temps à converger ou rester bloqués aux minimums locaux. Si vous rencontrez ce problème, vous pouvez également envisager d'utiliser l'analyse en composantes principales (ACP).
Il existe également d'autres algorithmes de clustering en dehors des ressources KMeans, comme le clustering spatial basé sur la densité (DBSCAN).
Pour découvrir comment utiliser d'autres services dans l'API Gemini, consultez le guide de démarrage rapide pour Python. Pour en savoir plus sur l'utilisation des représentations vectorielles continues, consultez les exemples disponibles. Pour apprendre à les créer à partir de zéro, consultez le tutoriel Représentations vectorielles continues de mots de TensorFlow.