
|
|
|
 Visualizza il codice sorgente su GitHub Visualizza il codice sorgente su GitHub
|
Panoramica
Questo tutorial mostra come visualizzare ed eseguire il clustering con gli incorporamenti dell'API Gemini. Vedrai un sottoinsieme del set di dati di 20 Newsgroup utilizzando t-SNE e raggruppa quel sottoinsieme utilizzando l'algoritmo KMeans.
Per ulteriori informazioni su come iniziare a utilizzare gli incorporamenti generati dall'API Gemini, consulta la guida rapida di Python.
Prerequisiti
Puoi eseguire questa guida rapida in Google Colab.
Per completare questa guida rapida sul tuo ambiente di sviluppo, assicurati che quest'ultimo soddisfi i requisiti seguenti:
- Python 3.9 e versioni successive
- Un'installazione di
jupyterper eseguire il blocco note.
Configurazione
Innanzitutto, scarica e installa la libreria Python dell'API Gemini.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
import google.ai.generativelanguage as glm
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
Acquisisci una chiave API
Prima di poter utilizzare l'API Gemini, devi ottenere una chiave API. Se non ne hai già una, crea una chiave con un clic in Google AI Studio.
In Colab, aggiungi la chiave al gestore dei secret nella sezione "☁" del riquadro a sinistra. Assegna il nome API_KEY.
Una volta ottenuta la chiave API, passala all'SDK. A tale scopo, puoi procedere in uno dei due seguenti modi:
- Inserisci la chiave nella variabile di ambiente
GOOGLE_API_KEY(l'SDK la acquisirà automaticamente da lì). - Passa la chiave a
genai.configure(api_key=...)
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
Set di dati
Il set di dati di testo 20 Newsgroup contiene 18.000 post di newsgroup su 20 argomenti,suddivisi in set di addestramento e test. La suddivisione tra i set di dati di addestramento e di test si basa sui messaggi pubblicati prima e dopo una data specifica. Per questo tutorial, utilizzerai il sottoinsieme di addestramento.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
Ecco il primo esempio del set di addestramento.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
Quindi, campionerai alcuni dati prendendo 100 punti dati nel set di dati di addestramento ed eliminando alcune delle categorie da eseguire in questo tutorial. Scegli le categorie scientifiche da confrontare.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
Crea gli incorporamenti
In questa sezione, vedrai come generare incorporamenti per i diversi testi nel dataframe utilizzando gli incorporamenti dell'API Gemini.
Modifiche all'API Embeddings con modello Embedding-001
Per il nuovo modello di incorporamenti, Embedding-001, sono presenti un nuovo parametro del tipo di attività e il titolo facoltativo (valido solo con task_type=RETRIEVAL_DOCUMENT).
Questi nuovi parametri si applicano solo ai modelli di incorporamenti più recenti.I tipi di attività sono:
| Tipo di attività | Descrizione |
|---|---|
| RETRIEVAL_QUERY | Specifica che il testo specificato è una query in un'impostazione di ricerca/recupero. |
| RETRIEVAL_DOCUMENT | Specifica che il testo specificato è un documento in un'impostazione di ricerca/recupero. |
| SEMANTIC_SIMILARITY | Consente di specificare che il testo specificato verrà utilizzato per la somiglianza testuale semantica (STS). |
| CLASSIFICAZIONE | Specifica che gli incorporamenti verranno utilizzati per la classificazione. |
| CLUSTERING | Specifica che gli incorporamenti verranno utilizzati per il clustering. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
Riduzione della dimensionalità
La lunghezza del vettore di incorporamento del documento è 768. Per visualizzare come i documenti incorporati sono raggruppati, dovrai applicare la riduzione della dimensionalità, poiché puoi visualizzare solo gli incorporamenti nello spazio 2D o 3D. Documenti contestualmente simili dovrebbero trovarsi più vicini nello spazio, a differenza di documenti che non sono così simili.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
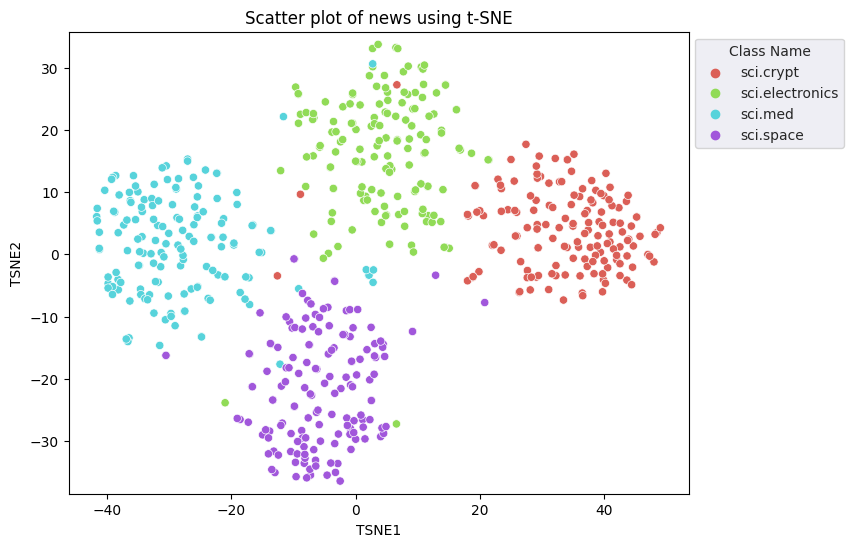
Per eseguire la riduzione della dimensionalità, applicherai l'approccio t-Distributed Stochastic Nearby Embedding (t-SNE). Questa tecnica riduce il numero di dimensioni, mantenendo al contempo i cluster (i punti vicini rimangono vicini). Per i dati originali, il modello cerca di costruire una distribuzione sulla quale altri punti dati sono "vicini" (ad es. condividono un significato simile). Ottimizza quindi una funzione obiettivo per mantenere una distribuzione simile nella visualizzazione.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
Confronta i risultati con KMeans
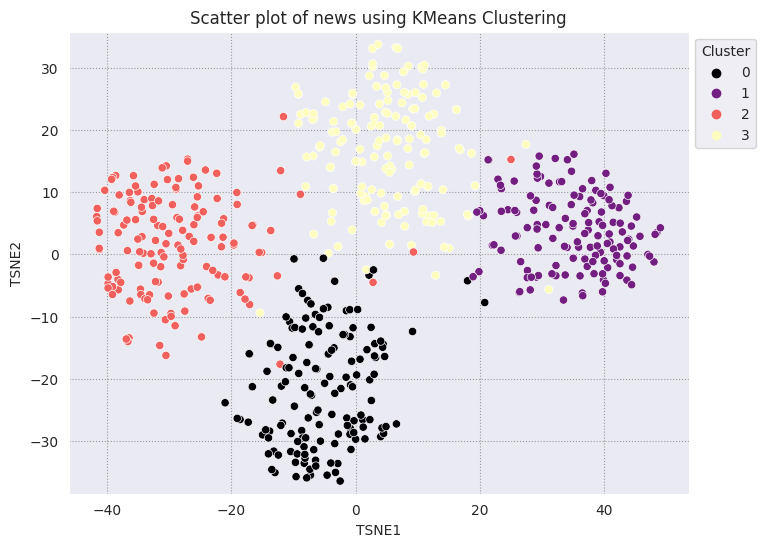
Il clustering KMeans è un popolare algoritmo di clustering, spesso utilizzato per l'apprendimento non supervisionato. Determina iterativamente i migliori punti k centrali e assegna ogni esempio al baricentro più vicino. Inserisci gli incorporamenti direttamente nell'algoritmo KMeans per confrontare la visualizzazione degli incorporamenti con le prestazioni di un algoritmo di machine learning.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
Ottieni la maggior parte dei cluster per gruppo e controlla quanti dei membri effettivi di quel gruppo si trovano in quel cluster.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
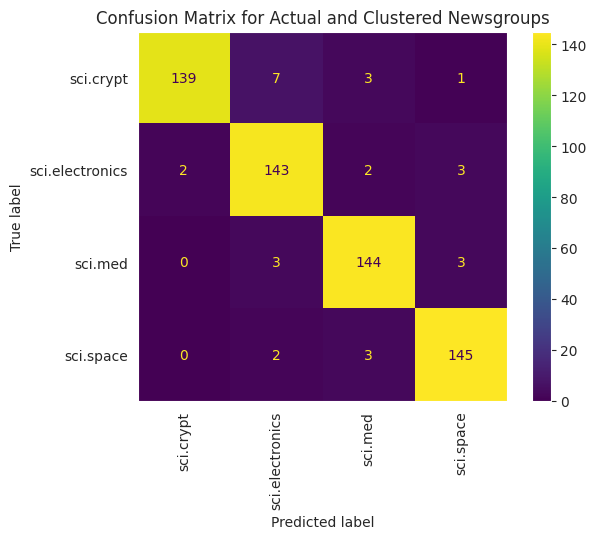
Per visualizzare meglio le prestazioni dei KMeans applicati ai dati, puoi utilizzare una matrice di confusione. La matrice di confusione consente di valutare le prestazioni del modello di classificazione oltre l'accuratezza. Puoi vedere come vengono classificati i punti classificati in modo errato. Avrai bisogno dei valori effettivi e previsti, che hai raccolto nel dataframe sopra.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
Passaggi successivi
A questo punto hai creato una visualizzazione personalizzata degli incorporamenti con il clustering. Prova a utilizzare i tuoi dati testuali per visualizzarli come incorporamenti. Puoi eseguire la riduzione della dimensionalità per completare il passaggio di visualizzazione. Tieni presente che TSNE è un'ottima soluzione per il clustering degli input, ma può richiedere più tempo per convergere o potrebbe bloccarsi ai minimi locali. Se riscontri questo problema, un'altra tecnica che puoi prendere in considerazione è l'analisi delle componenti principali (PCA).
Esistono anche altri algoritmi di clustering al di fuori di KMeans, come il clustering spaziale basato sulla densità (DBSCAN).
Per scoprire come utilizzare altri servizi dell'API Gemini, visita la guida rapida di Python. Per saperne di più su come utilizzare gli incorporamenti, controlla gli esempi disponibili. Per scoprire come crearle da zero, consulta il tutorial su incorporamenti di parole di TensorFlow.