
|
|
|
 Wyświetl źródło na GitHubie Wyświetl źródło na GitHubie
|
Przegląd
Ten samouczek pokazuje, jak wizualizować i wykonywać klastry za pomocą wektorów dystrybucyjnych z interfejsu Gemini API. Zwizualizujesz podzbiór zbioru danych z 20 grup dyskusyjnych przy użyciu funkcji t-SNE i zwizualizujesz ten podzbiór za pomocą algorytmu KMeans.
Więcej informacji o tym, jak zacząć używać wektorów dystrybucyjnych wygenerowanych za pomocą interfejsu Gemini API, znajdziesz w krótkim wprowadzeniu do Pythona.
Wymagania wstępne
Możesz uruchomić to krótkie wprowadzenie w Google Colab.
Aby wykonać to krótkie wprowadzenie we własnym środowisku programistycznym, upewnij się, że spełnia ono te wymagania:
- Python 3.9 lub nowszy
- Instalacja pakietu
jupyterdo uruchamiania notatnika.
Konfiguracja
Najpierw pobierz i zainstaluj bibliotekę Gemini API w języku Python.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
import google.ai.generativelanguage as glm
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
Wygeneruj klucz interfejsu API
Aby korzystać z interfejsu Gemini API, musisz najpierw uzyskać klucz interfejsu API. Jeśli nie masz jeszcze klucza, utwórz go jednym kliknięciem w Google AI Studio.
Uzyskiwanie klucza interfejsu API
W Colab dodaj klucz do menedżera obiektów tajnych w sekcji „🔑” w panelu po lewej stronie. Nadaj mu nazwę API_KEY.
Przekaż klucz interfejsu API do pakietu SDK. Można to zrobić na dwa sposoby:
- Umieść klucz w zmiennej środowiskowej
GOOGLE_API_KEY(pakiet SDK automatycznie go stamtąd zabierze). - Przekaż klucz do:
genai.configure(api_key=...)
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
Zbiór danych
Zbiór danych tekstowych 20 grup dyskusyjnych zawiera 18 000 postów na 20 tematów w grupach dyskusyjnych,które są podzielone na zbiory treningowe i testowe. Podział między zbiorem danych treningowych i testowych jest oparty na wiadomościach opublikowanych przed określoną datą i po niej. W tym samouczku będziesz używać podzbioru do trenowania.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
Oto pierwszy przykład w zbiorze treningowym.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
Następnie wykorzystasz 100 punktów danych w zbiorze danych treningowych i upuść kilka kategorii, które zostaną opisane w tym samouczku. Wybierz kategorie nauki do porównania.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
Tworzenie wektorów dystrybucyjnych
W tej sekcji dowiesz się, jak generować wektory dystrybucyjne dla różnych tekstów w ramce DataFrame za pomocą wektorów dystrybucyjnych z interfejsu Gemini API.
Zmiany interfejsu API we reprezentacji właściwościowych z działaniem 001 modelu
W nowym modelu reprezentacji właściwościowych (Embed_type=001) dostępny jest nowy parametr typu zadania i opcjonalny tytuł (prawidłowy tylko z parametrem load_type=RETRIEVAL_DOCUMENT).
Te nowe parametry mają zastosowanie tylko do najnowszych modeli reprezentacji właściwościowych.Typy zadań to:
| Typ zadania | Opis |
|---|---|
| RETRIEVAL_QUERY | Określa, że podany tekst jest zapytaniem w ustawieniu wyszukiwania/pobierania. |
| RETRIEVAL_DOCUMENT | Określa, że podany tekst jest dokumentem w ustawieniu wyszukiwania/pobierania. |
| SEMANTIC_SIMILARITY | Określa podany tekst, który będzie używany do semantycznego podobieństwa tekstu (STS). |
| KLASYFIKACJA | Określa, że do klasyfikacji będą używane wektory dystrybucyjne. |
| KLASTRY | Określa, że wektory dystrybucyjne będą używane do grupowania. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
Redukcja wymiarów
Długość wektora dystrybucyjnego dokumentu wynosi 768. Aby zobaczyć, jak są grupowane umieszczone dokumenty, musisz zastosować redukcję wymiarów, ponieważ możesz wizualizować osadzone elementy tylko w przestrzeni 2D lub 3D. Dokumenty podobne pod względem kontekstu powinny znajdować się bliżej siebie w przestrzeni – inaczej dokumenty nie są tak podobne.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
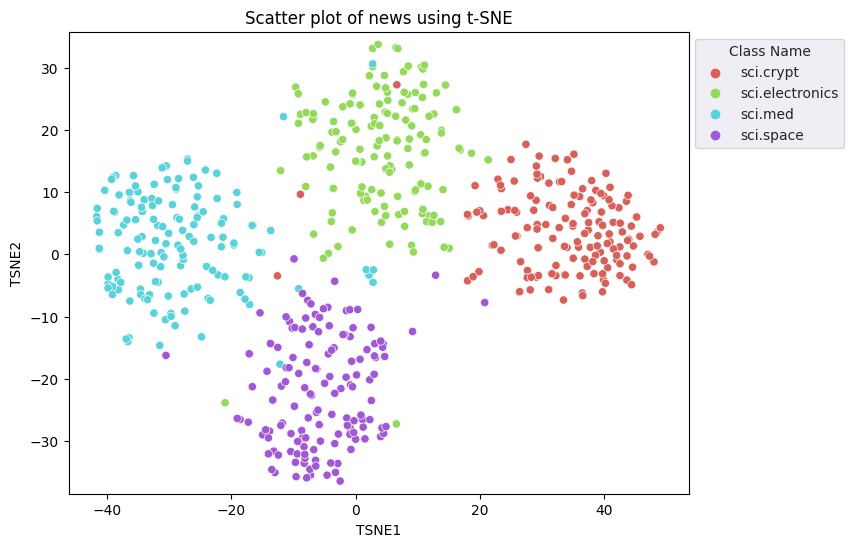
W celu redukcji wymiarów zastosujesz metodę t-Distributed Stochastic Embedding (t-SNE). Ta metoda zmniejsza liczbę wymiarów przy zachowaniu klastrów (punkty, które znajdują się blisko siebie, i są blisko siebie). W przypadku danych oryginalnych model próbuje utworzyć rozkład, w którym inne punkty danych są „sąsiadami” (np. mają podobne znaczenie). Następnie optymalizuje funkcję celu, aby zachować podobny rozkład na wizualizacji.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
Porównaj wyniki z Kmeanami
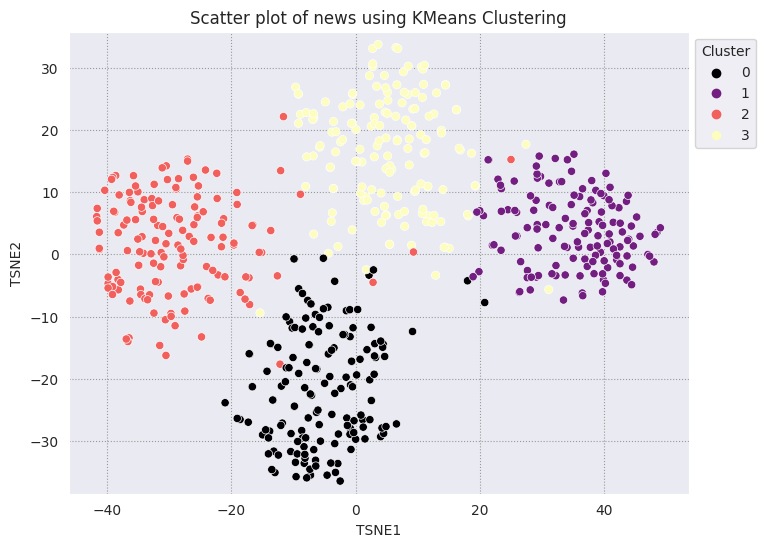
Klasterowanie KMeans to popularny algorytm grupowania, często używany do uczenia się nienadzorowanego. Ta funkcja określa iteracyjnie najlepsze punkty środkowe (k) i przypisuje każdy przykład do najbliższego centrum. Wprowadź wektory dystrybucyjne bezpośrednio do algorytmu KMeans, aby porównać wizualizację reprezentacji właściwościowych z wydajnością algorytmu systemów uczących się.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
Pobierz większość klastrów na grupę i zobacz, ilu rzeczywistych członków tej grupy znajduje się w tym klastrze.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
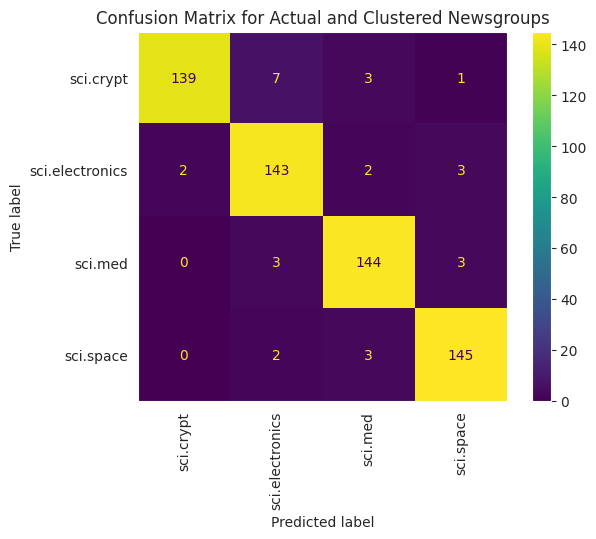
Aby lepiej wizualizować skuteczność KMean zastosowanych do danych, możesz użyć macierzy pomyłek. Tablica pomyłek pozwala ocenić wydajność modelu klasyfikacji poza poziomem dokładności. Możesz sprawdzić, jak nieprawidłowo klasyfikowane są punkty. Potrzebne będą wartości rzeczywiste i prognozowane zebrane w ramce powyżej.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
Dalsze kroki
Udało Ci się utworzyć własną wizualizację reprezentacji właściwościowych za pomocą grupowania. Spróbuj użyć własnych danych tekstowych, aby zwizualizować je jako reprezentacje właściwościowe. Aby zakończyć etap wizualizacji, możesz zmniejszyć wymiary. Pamiętaj, że TSNE dobrze sprawdza się w grupowaniu danych wejściowych, ale ich zjednoczenie może zająć więcej czasu lub może utknąć na poziomie lokalnych minimalnych wartości minimalnych. W przypadku tego problemu możesz wypróbować analizę głównych komponentów (PCA) (analiza głównych komponentów).
Poza KMeanami istnieją też inne algorytmy grupowania, na przykład klaster przestrzenny oparty na gęstości (DBSCAN).
Aby dowiedzieć się, jak korzystać z innych usług w interfejsie Gemini API, zapoznaj się z krótkim wprowadzeniem do Pythona. Aby dowiedzieć się więcej o używaniu reprezentacji właściwościowych, zapoznaj się z dostępnymi przykładami. Aby dowiedzieć się, jak tworzyć je od podstaw, zobacz samouczek dotyczący umieszczania słów w TensorFlow.