জেমিনি এপিআই এমন সুরক্ষা সেটিংস প্রদান করে যা আপনি প্রোটোটাইপিং পর্যায়ে সমন্বয় করে নির্ধারণ করতে পারেন যে আপনার অ্যাপ্লিকেশনের জন্য কম বা বেশি কঠোর সুরক্ষা কনফিগারেশন প্রয়োজন কিনা। নির্দিষ্ট ধরণের কন্টেন্ট সীমাবদ্ধ বা অনুমোদিত করার জন্য আপনি চারটি ফিল্টার ক্যাটাগরিতে এই সেটিংসগুলো সমন্বয় করতে পারেন।
এই নির্দেশিকায় আলোচনা করা হয়েছে যে, জেমিনি এপিআই কীভাবে সুরক্ষা সেটিংস ও ফিল্টারিং পরিচালনা করে এবং আপনি কীভাবে আপনার অ্যাপ্লিকেশনের জন্য সুরক্ষা সেটিংস পরিবর্তন করতে পারেন।
নিরাপত্তা ফিল্টার
জেমিনি এপিআই-এর সামঞ্জস্যযোগ্য সুরক্ষা ফিল্টারগুলো নিম্নলিখিত বিভাগগুলোকে অন্তর্ভুক্ত করে:
| বিভাগ | বর্ণনা |
|---|---|
| হয়রানি | পরিচয় এবং/অথবা সুরক্ষিত বৈশিষ্ট্য লক্ষ্য করে করা নেতিবাচক বা ক্ষতিকর মন্তব্য। |
| ঘৃণামূলক বক্তব্য | অভদ্র, অসম্মানজনক বা অশ্লীল বিষয়বস্তু। |
| যৌনভাবে স্পষ্ট | এতে যৌন কার্যকলাপ বা অন্যান্য অশ্লীল বিষয়বস্তুর উল্লেখ রয়েছে। |
| বিপজ্জনক | ক্ষতিকর কাজকে উৎসাহিত করে, সহায়তা করে বা প্ররোচিত করে। |
এই বিভাগগুলো HarmCategory তে সংজ্ঞায়িত করা আছে। আপনার ব্যবহারের ক্ষেত্রে কী উপযুক্ত, তা ঠিক করতে আপনি এই ফিল্টারগুলো ব্যবহার করতে পারেন। উদাহরণস্বরূপ, আপনি যদি ভিডিও গেমের সংলাপ তৈরি করেন, তবে গেমটির প্রকৃতির কারণে Dangerous হিসেবে রেট করা আরও বেশি কন্টেন্টের অনুমতি দেওয়া আপনার কাছে গ্রহণযোগ্য মনে হতে পারে।
পরিবর্তনযোগ্য সুরক্ষা ফিল্টার ছাড়াও, জেমিনি এপিআই-তে শিশু সুরক্ষার জন্য বিপজ্জনক বিষয়বস্তুর মতো মৌলিক ক্ষতিকর বিষয়গুলোর বিরুদ্ধে অন্তর্নির্মিত সুরক্ষা ব্যবস্থা রয়েছে। এই ধরনের ক্ষতিকর বিষয়গুলো সর্বদা ব্লক করা থাকে এবং এগুলো পরিবর্তন করা যায় না।
বিষয়বস্তু সুরক্ষা ফিল্টারিং স্তর
জেমিনি এপিআই কোনো কন্টেন্ট অনিরাপদ হওয়ার সম্ভাবনার স্তরকে HIGH , MEDIUM , LOW বা NEGLIGIBLE এই চারটি ভাগে ভাগ করে।
জেমিনি এপিআই কোনো কন্টেন্টের অনিরাপদ হওয়ার সম্ভাবনার উপর ভিত্তি করে সেটিকে ব্লক করে, তার ক্ষতির তীব্রতার উপর ভিত্তি করে নয়। এই বিষয়টি বিবেচনা করা গুরুত্বপূর্ণ, কারণ কিছু কন্টেন্টের অনিরাপদ হওয়ার সম্ভাবনা কম থাকলেও, সেটির ক্ষতির তীব্রতা অনেক বেশি হতে পারে। উদাহরণস্বরূপ, এই বাক্যগুলো তুলনা করলে দেখা যায়:
- রোবটটা আমাকে ঘুষি মারল।
- রোবটটা আমাকে কোপ মেরেছে।
প্রথম বাক্যটির অনিরাপদ হওয়ার সম্ভাবনা বেশি থাকতে পারে, কিন্তু আপনি দ্বিতীয় বাক্যটিকে সহিংসতার দিক থেকে আরও গুরুতর বলে বিবেচনা করতে পারেন। এই পরিপ্রেক্ষিতে, আপনার মূল ব্যবহারের ক্ষেত্রগুলোকে সমর্থন করার জন্য এবং একই সাথে ব্যবহারকারীদের ক্ষতি কমানোর জন্য কী ধরনের উপযুক্ত ব্লকিং প্রয়োজন, তা সতর্কতার সাথে পরীক্ষা করা এবং বিবেচনা করা গুরুত্বপূর্ণ।
অনুরোধ অনুযায়ী নিরাপত্তা ফিল্টারিং
আপনি এপিআই-তে করা প্রতিটি অনুরোধের জন্য নিরাপত্তা সেটিংস সামঞ্জস্য করতে পারেন। আপনি যখন কোনো অনুরোধ করেন, তখন বিষয়বস্তুটি বিশ্লেষণ করা হয় এবং একটি নিরাপত্তা রেটিং নির্ধারণ করা হয়। এই নিরাপত্তা রেটিং-এ ক্ষতির শ্রেণিবিভাগের বিভাগ এবং সম্ভাবনা অন্তর্ভুক্ত থাকে। উদাহরণস্বরূপ, যদি হয়রানির উচ্চ সম্ভাবনার কারণে বিষয়বস্তুটি ব্লক করা হয়, তাহলে ফেরত আসা নিরাপত্তা রেটিং-এ বিভাগ হবে HARASSMENT এবং ক্ষতির সম্ভাবনা HIGH হিসেবে সেট করা থাকবে।
মডেলটির অন্তর্নিহিত নিরাপত্তার কারণে, অতিরিক্ত ফিল্টারগুলো ডিফল্টরূপে বন্ধ থাকে। আপনি যদি এগুলো চালু করতে চান, তবে কোনো কন্টেন্ট অনিরাপদ হওয়ার সম্ভাবনার ওপর ভিত্তি করে সেটিকে ব্লক করার জন্য সিস্টেমটি কনফিগার করতে পারবেন। মডেলটির ডিফল্ট আচরণ বেশিরভাগ ব্যবহারের ক্ষেত্রেই প্রযোজ্য, তাই আপনার অ্যাপ্লিকেশনের জন্য ধারাবাহিকতা প্রয়োজন হলেই কেবল এই সেটিংসগুলো পরিবর্তন করা উচিত।
নিচের সারণিতে প্রতিটি বিভাগের জন্য আপনি যে ব্লক সেটিংসগুলো সমন্বয় করতে পারেন, তা বর্ণনা করা হয়েছে। উদাহরণস্বরূপ, যদি আপনি 'ঘৃণামূলক বক্তব্য' বিভাগের জন্য ব্লক সেটিংটি ' কয়েকটি ব্লক করুন' (Block few) এ সেট করেন, তাহলে বিদ্বেষমূলক বক্তব্য হওয়ার উচ্চ সম্ভাবনা রয়েছে এমন সবকিছু ব্লক করা হবে। কিন্তু কম সম্ভাবনাযুক্ত যেকোনো কিছু অনুমোদিত থাকবে।
| থ্রেশহোল্ড (গুগল এআই স্টুডিও) | থ্রেশহোল্ড (এপিআই) | বর্ণনা |
|---|---|---|
| বন্ধ | OFF | সুরক্ষা ফিল্টারটি বন্ধ করুন। |
| ব্লক না করা | BLOCK_NONE | অনিরাপদ বিষয়বস্তুর সম্ভাবনা থাকা সত্ত্বেও সর্বদা প্রদর্শন করুন। |
| কয়েকটি ব্লক | BLOCK_ONLY_HIGH | অনিরাপদ বিষয়বস্তু থাকার উচ্চ সম্ভাবনা থাকলে ব্লক করুন। |
| কিছু ব্লক করুন | BLOCK_MEDIUM_AND_ABOVE | অনিরাপদ বিষয়বস্তুর মাঝারি বা উচ্চ সম্ভাবনা থাকলে ব্লক করুন। |
| ব্লক মোস্ট | BLOCK_LOW_AND_ABOVE | অনিরাপদ বিষয়বস্তুর সম্ভাবনা কম, মাঝারি বা বেশি হলে ব্লক করুন। |
| প্রযোজ্য নয় | HARM_BLOCK_THRESHOLD_UNSPECIFIED | থ্রেশহোল্ড অনির্দিষ্ট, ডিফল্ট থ্রেশহোল্ড ব্যবহার করে ব্লক করুন। |
থ্রেশহোল্ড সেট করা না থাকলে, জেমিনি ২.৫ এবং ৩ মডেলের জন্য ডিফল্ট ব্লক থ্রেশহোল্ড ' অফ' থাকে।
জেনারেটিভ সার্ভিসে করা আপনার প্রতিটি অনুরোধের জন্য আপনি এই সেটিংসগুলো সেট করতে পারেন। বিস্তারিত জানতে HarmBlockThreshold API রেফারেন্স দেখুন।
নিরাপত্তা প্রতিক্রিয়া
generateContent একটি GenerateContentResponse রিটার্ন করে, যাতে নিরাপত্তা সংক্রান্ত ফিডব্যাক অন্তর্ভুক্ত থাকে।
প্রম্পট ফিডব্যাক ` promptFeedback এর অন্তর্ভুক্ত। যদি promptFeedback.blockReason সেট করা থাকে, তাহলে প্রম্পটের বিষয়বস্তু ব্লক করা হয়েছিল।
প্রতিক্রিয়া প্রার্থীর মতামত Candidate.finishReason এবং Candidate.safetyRatings এ অন্তর্ভুক্ত থাকে। যদি প্রতিক্রিয়ার বিষয়বস্তু ব্লক করা হয়ে থাকে এবং finishReason হয় SAFETY , তাহলে আরও বিস্তারিত তথ্যের জন্য আপনি safetyRatings পরীক্ষা করতে পারেন। যে বিষয়বস্তুটি ব্লক করা হয়েছিল, তা ফেরত দেওয়া হয় না।
নিরাপত্তা সেটিংস সামঞ্জস্য করুন
এই অংশে গুগল এআই স্টুডিও এবং আপনার কোড উভয় ক্ষেত্রেই নিরাপত্তা সেটিংস কীভাবে সমন্বয় করতে হয়, তা আলোচনা করা হয়েছে।
গুগল এআই স্টুডিও
আপনি গুগল এআই স্টুডিও-তে নিরাপত্তা সেটিংস সমন্বয় করতে পারেন।
রান সেটিংস প্যানেলে অ্যাডভান্সড সেটিংস- এর অধীনে সেফটি সেটিংস-এ ক্লিক করে রান সেফটি সেটিংস মডালটি খুলুন। মডালটিতে, আপনি স্লাইডারগুলি ব্যবহার করে প্রতিটি সেফটি ক্যাটাগরি অনুযায়ী কন্টেন্ট ফিল্টারিং লেভেল অ্যাডজাস্ট করতে পারেন:
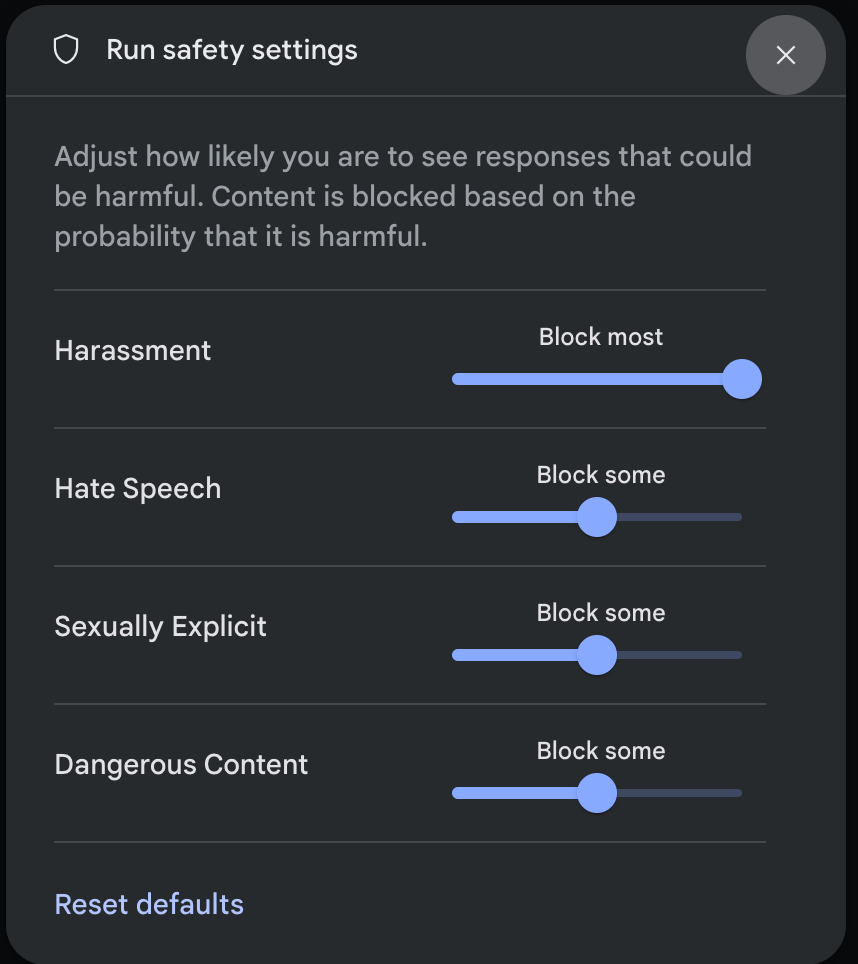
যখন আপনি কোনো অনুরোধ পাঠান (উদাহরণস্বরূপ, মডেলকে কোনো প্রশ্ন জিজ্ঞাসা করে), তখন অনুরোধটির বিষয়বস্তু ব্লক করা থাকলে ‘Content blocked’ লেখাটির একটি বার্তা প্রদর্শিত হয়। আরও বিস্তারিত দেখতে, ক্ষতির শ্রেণিবিভাগের বিভাগ এবং সম্ভাবনা দেখার জন্য ‘Content blocked’ লেখাটির উপর পয়েন্টারটি ধরে রাখুন।
কোডের উদাহরণ
নিম্নলিখিত কোড স্নিপেটটি দেখায় কিভাবে আপনার GenerateContent কলে সুরক্ষা সেটিংস সেট করতে হয়। এটি হেট স্পিচ ( HARM_CATEGORY_HATE_SPEECH ) ক্যাটাগরির জন্য থ্রেশহোল্ড নির্ধারণ করে। এই ক্যাটাগরিটি BLOCK_LOW_AND_ABOVE এ সেট করলে, হেট স্পিচ হওয়ার কম বা বেশি সম্ভাবনাযুক্ত যেকোনো কন্টেন্ট ব্লক হয়ে যায়। থ্রেশহোল্ড সেটিংস সম্পর্কে জানতে, 'Safety filtering per request' দেখুন।
পাইথন
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
যান
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
জাভাস্ক্রিপ্ট
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
জাভা
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
বিশ্রাম
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
পরবর্তী পদক্ষেপ
- সম্পূর্ণ এপিআই সম্পর্কে আরও জানতে এপিআই রেফারেন্স দেখুন।
- এলএলএম ব্যবহার করে ডেভেলপ করার সময় নিরাপত্তা সংক্রান্ত বিষয়গুলো সম্পর্কে সাধারণ ধারণা পেতে সুরক্ষা নির্দেশিকাটি পর্যালোচনা করুন।
- জিগস টিমের কাছ থেকে সম্ভাবনা বনাম তীব্রতা মূল্যায়ন সম্পর্কে আরও জানুন।
- Perspective API-এর মতো সুরক্ষা সমাধানে অবদান রাখে এমন পণ্যগুলি সম্পর্কে আরও জানুন। * আপনি এই সুরক্ষা সেটিংস ব্যবহার করে একটি বিষাক্ততা ক্লাসিফায়ার তৈরি করতে পারেন। শুরু করার জন্য ক্লাসিফিকেশন উদাহরণটি দেখুন।