
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub |
بررسی اجمالی
این آموزش نحوه تجسم و انجام خوشه بندی با جاسازی های Gemini API را نشان می دهد. شما زیرمجموعه ای از مجموعه داده ۲۰ گروه خبری را با استفاده از t-SNE تجسم خواهید کرد و آن زیر مجموعه را با استفاده از الگوریتم KMeans خوشه بندی خواهید کرد.
برای اطلاعات بیشتر درباره شروع کار با جاسازیهای ایجاد شده از API Gemini، شروع سریع پایتون را بررسی کنید.
پیش نیازها
می توانید این شروع سریع را در Google Colab اجرا کنید.
برای تکمیل این شروع سریع در محیط توسعه خود، مطمئن شوید که محیط شما شرایط زیر را برآورده می کند:
- پایتون 3.9+
- نصب
jupyterبرای اجرای نوت بوک.
برپایی
ابتدا کتابخانه Gemini API Python را دانلود و نصب کنید.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
یک کلید API بگیرید
قبل از اینکه بتوانید از Gemini API استفاده کنید، ابتدا باید یک کلید API دریافت کنید. اگر قبلاً یکی ندارید، با یک کلیک در Google AI Studio یک کلید ایجاد کنید.
در Colab، کلید را به مدیر مخفی زیر "🔑" در پانل سمت چپ اضافه کنید. نام API_KEY را به آن بدهید.
هنگامی که کلید API را دارید، آن را به SDK منتقل کنید. شما می توانید این کار را به دو صورت انجام دهید:
- کلید را در متغیر محیطی
GOOGLE_API_KEYقرار دهید (SDK به طور خودکار آن را از آنجا دریافت می کند). - کلید را به
genai.configure(api_key=...)بدهید
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
مجموعه داده
مجموعه داده متنی 20 گروه خبری شامل 18000 پست گروه خبری در 20 موضوع است که به مجموعه های آموزشی و آزمایشی تقسیم می شوند. تقسیم بین مجموعه داده های آموزشی و آزمایشی بر اساس پیام های ارسال شده قبل و بعد از یک تاریخ خاص است. برای این آموزش از زیر مجموعه آموزشی استفاده خواهید کرد.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
این اولین نمونه در مجموعه آموزشی است.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
در مرحله بعد، با در نظر گرفتن 100 نقطه داده در مجموعه داده آموزشی، و حذف تعدادی از دسته ها برای اجرای این آموزش، برخی از داده ها را نمونه برداری می کنید. دسته بندی های علمی را برای مقایسه انتخاب کنید.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
جاسازی ها را ایجاد کنید
در این بخش، نحوه ایجاد جاسازی برای متون مختلف در دیتافریم با استفاده از جاسازیهای Gemini API را خواهید دید.
API به Embeddings با مدل embedding-001 تغییر می کند
برای مدل embeddings جدید، embedding-001، یک پارامتر نوع کار جدید و عنوان اختیاری وجود دارد (فقط برای task_type= RETRIEVAL_DOCUMENT معتبر است).
این پارامترهای جدید فقط برای جدیدترین مدلهای جاسازی اعمال میشوند. انواع وظایف عبارتند از:
| نوع وظیفه | شرح |
|---|---|
| RETRIEVAL_QUERY | مشخص می کند که متن داده شده یک پرس و جو در تنظیمات جستجو/بازیابی باشد. |
| RETRIEVAL_DOCUMENT | مشخص می کند که متن داده شده یک سند در یک تنظیمات جستجو/بازیابی است. |
| SEMANTIC_SIMILARITY | مشخص می کند که متن داده شده برای تشابه متنی معنایی (STS) استفاده خواهد شد. |
| طبقه بندی | مشخص می کند که از تعبیه ها برای طبقه بندی استفاده می شود. |
| خوشه بندی | مشخص می کند که جاسازی ها برای خوشه بندی استفاده خواهند شد. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
کاهش ابعاد
طول بردار جاسازی سند 768 است. به منظور تجسم نحوه گروه بندی اسناد جاسازی شده با هم، باید کاهش ابعاد را اعمال کنید زیرا فقط می توانید جاسازی ها را در فضای دو بعدی یا سه بعدی تجسم کنید. اسناد مشابه متنی باید از نظر فضا به هم نزدیکتر باشند، در مقابل اسنادی که مشابه نیستند.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
شما از روش t-Distributed Stochastic Neighbor Embedding (t-SNE) برای کاهش ابعاد استفاده خواهید کرد. این تکنیک تعداد ابعاد را کاهش می دهد، در حالی که خوشه ها را حفظ می کند (نقاط نزدیک به هم نزدیک به هم می مانند). برای داده های اصلی، مدل سعی می کند توزیعی بسازد که سایر نقاط داده "همسایه" باشند (مثلاً معنای مشابهی دارند). سپس یک تابع هدف را برای حفظ توزیع مشابه در تجسم بهینه می کند.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
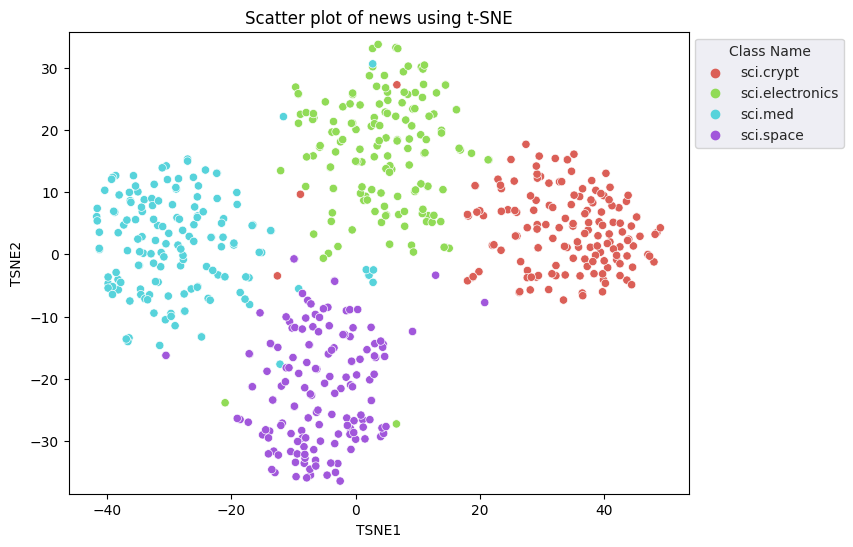
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
نتایج را با KMeans مقایسه کنید
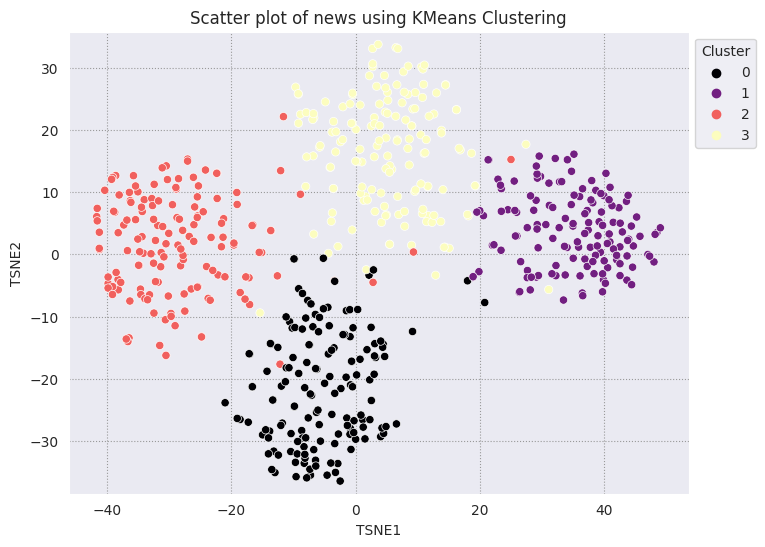
خوشهبندی KMeans یک الگوریتم خوشهبندی محبوب است و اغلب برای یادگیری بدون نظارت استفاده میشود. به طور مکرر بهترین K نقطه مرکزی را تعیین می کند و هر مثال را به نزدیکترین مرکز می دهد. جاسازیها را مستقیماً در الگوریتم KMeans وارد کنید تا تجسم جاسازیها را با عملکرد یک الگوریتم یادگیری ماشین مقایسه کنید.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
اکثر خوشه ها را در هر گروه دریافت کنید و ببینید چه تعداد از اعضای واقعی آن گروه در آن خوشه هستند.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
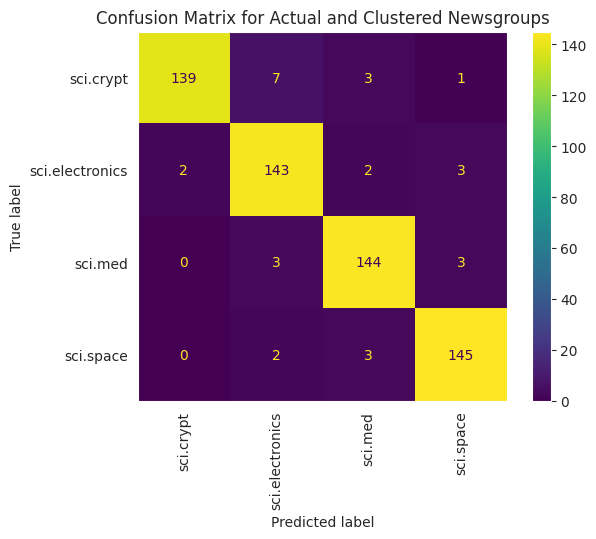
برای تجسم بهتر عملکرد KMeans اعمال شده بر روی داده های خود، می توانید از یک ماتریس سردرگمی استفاده کنید. ماتریس سردرگمی به شما امکان می دهد عملکرد مدل طبقه بندی را فراتر از دقت ارزیابی کنید. می توانید ببینید که چه نقاطی طبقه بندی شده به عنوان اشتباه طبقه بندی می شوند. شما به مقادیر واقعی و مقادیر پیش بینی شده نیاز خواهید داشت که در قالب داده بالا جمع آوری کرده اید.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
مراحل بعدی
شما اکنون تجسم خود را از جاسازی ها با خوشه بندی ایجاد کرده اید! سعی کنید از داده های متنی خود برای تجسم آنها به عنوان جاسازی استفاده کنید. برای تکمیل مرحله تجسم می توانید کاهش ابعاد را انجام دهید. توجه داشته باشید که TSNE در خوشهبندی ورودیها خوب است، اما ممکن است زمان بیشتری طول بکشد تا همگرا شود یا ممکن است در حداقلهای محلی گیر کند. اگر با این مشکل مواجه شدید، تکنیک دیگری که می توانید در نظر بگیرید ، تجزیه و تحلیل اجزای اصلی (PCA) است.
الگوریتم های خوشه بندی دیگری خارج از KMeans نیز وجود دارد، مانند خوشه بندی فضایی مبتنی بر چگالی (DBSCAN) .
برای کسب اطلاعات بیشتر در مورد نحوه استفاده از جاسازیها، این آموزشهای دیگر را ببینید: