
|
|
|
 Kaynağı GitHub'da görüntüle Kaynağı GitHub'da görüntüle
|
Genel Bakış
Bu eğitimde, Gemini API'deki yerleştirmelerle kümelemenin nasıl görselleştirileceği ve gerçekleştirileceği gösterilmektedir. 20 Newsgroup veri kümesinin bir alt kümesini t-SNE kullanarak ve bu alt kümeyi KMeans algoritmasıyla görselleştireceksiniz.
Gemini API'den oluşturulan yerleştirmeleri kullanmaya başlama hakkında daha fazla bilgi için Python hızlı başlangıç kılavuzu sayfasına göz atın.
Ön koşullar
Bu hızlı başlangıç kılavuzunu Google Colab'de çalıştırabilirsiniz.
Bu hızlı başlangıç kılavuzunu kendi geliştirme ortamınızda tamamlamak için çevrenizin aşağıdaki gereksinimleri karşıladığından emin olun:
- Python 3.9+
- Not defterini çalıştırmak için
jupyteryüklemesi.
Kurulum
Öncelikle Gemini API Python kitaplığını indirip yükleyin.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
API Anahtarı Alma
Gemini API'yi kullanabilmek için önce bir API anahtarı edinmeniz gerekir. Henüz yoksa Google AI Studio'da tek tıklamayla bir anahtar oluşturun.
Colab'de, anahtarı "🔑" bölümünün altında gizli anahtar yöneticisine ekleyin tıklayın. API_KEY adını verin.
API anahtarınızı aldıktan sonra SDK'ya iletin. Bunu iki şekilde yapabilirsiniz:
- Anahtarı
GOOGLE_API_KEYortam değişkenine yerleştirin (SDK, değişkeni otomatik olarak oradan alır). - Anahtarı
genai.configure(api_key=...)adlı cihaza geçirin
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
Veri kümesi
20 Haber Grubu Metin Veri Kümesi,eğitim ve test kümelerine bölünmüş 20 konu hakkında 18.000 haber grubu yayını içerir. Eğitim ve test veri kümeleri arasındaki ayrım, belirli bir tarihten önce ve sonra gönderilen mesajlara dayanır. Bu eğitimde, eğitim alt kümesini kullanacaksınız.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
Burada, eğitim veri kümesindeki ilk örnek verilmiştir.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
Daha sonra eğitim veri kümesinden 100 veri noktası alıp kategorilerden birkaçını bırakarak verilerin bir kısmını örnekleyeceksiniz. Karşılaştırılacak bilim kategorilerini seçin.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
Yerleştirmeleri oluşturma
Bu bölümde, Gemini API'deki yerleştirmeleri kullanarak veri çerçevesindeki farklı metinler için nasıl yerleştirme oluşturacağınızı öğreneceksiniz.
Model yerleştirme-001 ile yerleştirmelerde yapılan API değişiklikleri
Yeni yerleştirme modeli (embed-001) için yeni bir görev türü parametresi ve isteğe bağlı başlık (yalnızca task_type=RETRIEVAL_DOCUMENT ile geçerlidir).
Bu yeni parametreler yalnızca en yeni yerleştirme modelleri için geçerlidir.Görev türleri şunlardır:
| Görev Türü | Açıklama |
|---|---|
| RETRIEVAL_QUERY | Belirtilen metnin, arama/alma ayarındaki bir sorgu olduğunu belirtir. |
| RETRIEVAL_DOCUMENT | Belirtilen metnin, arama/alma ayarındaki bir doküman olduğunu belirtir. |
| SEMANTIC_SIMILARITY | Belirtilen metnin Semantik Metin Benzerliği (STS) için kullanılacağını belirtir. |
| SINIFLANDIRMA | Yerleştirmelerin sınıflandırma için kullanılacağını belirtir. |
| KÜMELEME | Yerleştirmelerin kümeleme için kullanılacağını belirtir. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
Boyut azaltma
Belge yerleştirme vektörünün uzunluğu 768'dir. Yerleştirilen dokümanların nasıl birlikte gruplandırıldığını görselleştirmek için, yerleştirmeleri yalnızca 2D veya 3D alanda görselleştirebileceğinizden boyut azaltma uygulamanız gerekir. Bağlamsal olarak benzer dokümanlar, benzer olmayan dokümanlar yerine alanda birbirine daha yakın olmalıdır.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
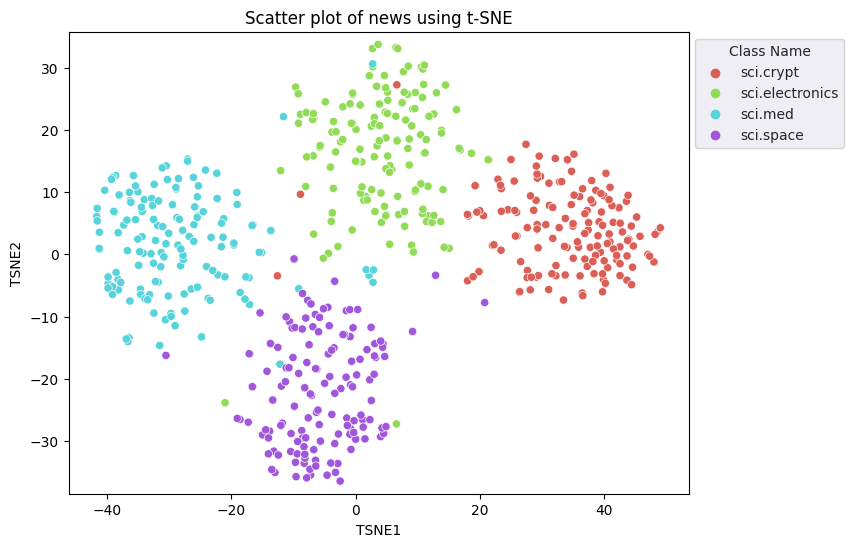
Boyut azaltma işlemi gerçekleştirmek için t-Dağıtılmış Stokastik Komşu Yerleştirme (t-SNE) yaklaşımını uygulayacaksınız. Bu teknik, kümeleri korurken boyutların sayısını azaltır (birbirine yakın olan noktalar birbirine yakın kalır). Model, orijinal veriler için diğer veri noktalarının "komşu" olduğu bir dağıtım oluşturmaya çalışır (ör. aynı anlama gelmeleri). Ardından, görselleştirmede benzer bir dağılıma sahip olmak için bir hedef işlevi optimize eder.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
Sonuçları KMeans ile karşılaştır
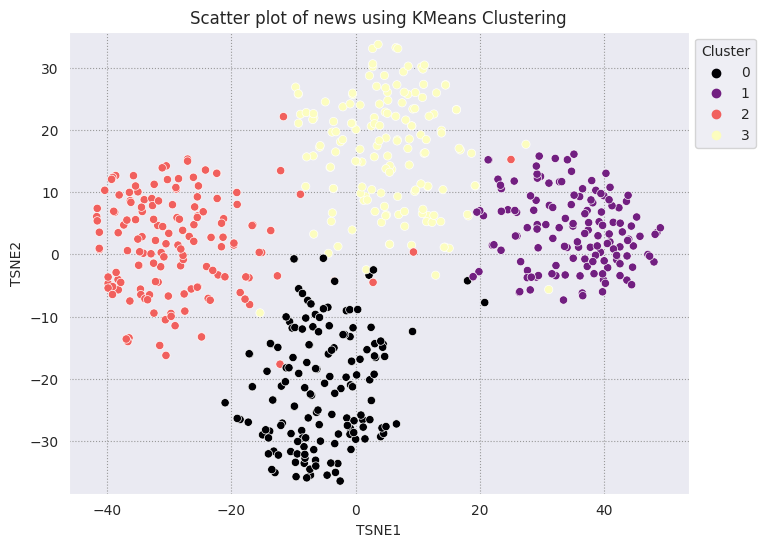
KMeans kümeleme popüler bir kümeleme algoritmasıdır ve genellikle gözetimsiz öğrenme için kullanılır. Bu yinelemeli olarak en iyi k merkez noktasını belirler ve her bir örneği en yakın merkeze atar. Yerleştirmelerin görselleştirmesini makine öğrenimi algoritmasının performansıyla karşılaştırmak için yerleştirmeleri doğrudan KMeans algoritmasına girin.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
Grup başına kümelerin çoğunluğunu alın ve ilgili grubun gerçek üyelerinden kaç tanesinin bu kümede olduğunu görün.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
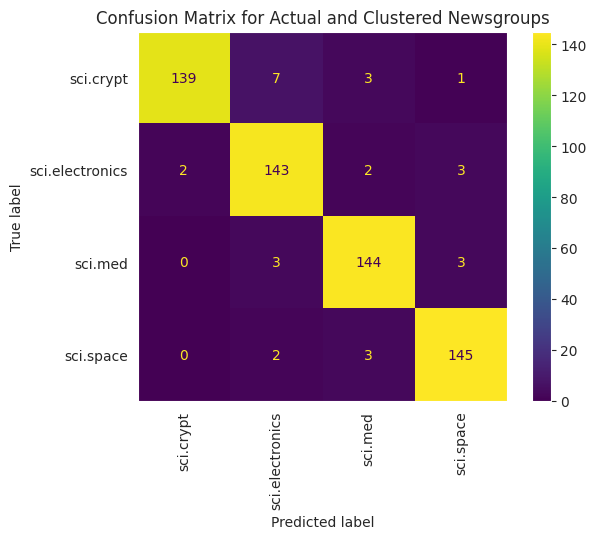
Verilerinize uygulanan KMe'lerin performansını daha iyi görselleştirmek için bir karıştırma matrisi kullanabilirsiniz. Karışıklık matrisi, sınıflandırma modelinin performansını doğruluğun ötesinde değerlendirmenize olanak tanır. Yanlış sınıflandırılan puanların ne olarak sınıflandırıldığını görebilirsiniz. Yukarıdaki veri çerçevesinde topladığınız gerçek değerlere ve tahmin edilen değerlere ihtiyacınız olacak.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
Sonraki adımlar
Artık kümeleme ile kendi yerleştirme görselleştirmenizi oluşturdunuz. Kendi metin verilerinizi kullanarak bunları yerleştirme olarak görselleştirmeyi deneyin. Görselleştirme adımını tamamlamak için boyutluluk azaltma işlemi yapabilirsiniz. TSNE'nin girişleri kümeleme konusunda iyi olduğunu, ancak yakınlaşmanın daha uzun sürebileceğini veya yerel minimumda takılabileceğini unutmayın. Bu sorunla karşılaşırsanız yararlanabileceğiniz bir diğer teknik de ana bileşen analizidir (PCA).
KMeans dışında yoğunluğa dayalı uzamsal kümeleme (DBSCAN) gibi başka kümeleme algoritmaları da vardır.
Yerleştirmeleri nasıl kullanabileceğiniz hakkında daha fazla bilgi edinmek için şu eğiticilere göz atın: