
|
|
|
 הצגת המקור ב-GitHub הצגת המקור ב-GitHub
|
סקירה
במדריך הזה מוסבר איך להציג באופן חזותי ולבצע אשכולות באמצעות ההטמעות של Gemini API. תוצג לכם המחשה חזותית של קבוצת משנה של מערך הנתונים של 20 Newsgroup באמצעות t-SNE וקיבוץ של קבוצת המשנה באמצעות האלגוריתם KMeans.
למידע נוסף על תחילת העבודה עם הטמעות שנוצרו מ-Gemini API, תוכלו לעיין במדריך למתחילים בנושא Python.
דרישות מוקדמות
אפשר להפעיל את המדריך למתחילים הזה ב-Google Colab.
כדי להשלים את המדריך למתחילים הזה בסביבת הפיתוח שלכם, צריך לוודא שהסביבה שלכם עומדת בדרישות הבאות:
- Python 3.9 ואילך
- התקנה של
jupyterכדי להריץ את ה-notebook.
הגדרה
קודם כול, מורידים ומתקינים את ספריית Python של Gemini API.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
קבלת מפתח API
כדי להשתמש ב-Gemini API, קודם צריך לקבל מפתח API. אם עדיין אין לכם מפתח, אתם יכולים ליצור מפתח בלחיצה אחת ב-Google AI Studio.
ב-Colab, מוסיפים את המפתח למנהל הסודות שמופיע מתחת לסמל 🔑 בחלונית השמאלית. נותנים למכשיר את השם API_KEY.
אחרי שמקבלים את מפתח ה-API, מעבירים אותו ל-SDK. תוכל לעשות זאת בשתי דרכים:
- מכניסים את המפתח למשתנה הסביבה
GOOGLE_API_KEY(ערכת ה-SDK תאסוף אותו משם באופן אוטומטי). - צריך להעביר את המפתח אל
genai.configure(api_key=...)
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
מערך נתונים
מערך נתוני הטקסט של 20 קבוצות חדשות מכיל 18,000 פוסטים של קבוצות חדשות ב-20 נושאים, המחולקים לערכות של אימון ובדיקה. החלוקה בין מערכי הנתונים לאימון ולמבחן מבוססת על הודעות שפורסמו לפני ואחרי תאריך מסוים. במדריך הזה נשתמש בקבוצת המשנה לאימון.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
זאת הדוגמה הראשונה בערכת האימון.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
בשלב הבא, תדגמו חלק מהנתונים על ידי איסוף של 100 נקודות נתונים במערך הנתונים לאימון, ושחרור של כמה מהקטגוריות שנלמדו במדריך הזה. בוחרים את הקטגוריות המדעיות להשוואה.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
יצירת הטמעות
בקטע הזה נסביר איך ליצור הטמעות לטקסטים השונים ב-dataframe באמצעות הטמעות מ-Gemini API.
שינויים ב-API של הטמעות עם מודל הטמעת מודל-001
למודל ההטמעות החדש, embed-001, יש פרמטר חדש של סוג משימה והכותרת האופציונלית (רלוונטי רק ל-task_type=RETRIEVAL_DOCUMENT).
הפרמטרים החדשים האלה רלוונטיים רק למודלים החדשים ביותר של הטמעות.סוגי המשימות הם:
| סוג המשימה | תיאור |
|---|---|
| RETRIEVAL_QUERY | מציינת שהטקסט הנתון הוא שאילתה בהגדרת חיפוש/אחזור. |
| RETRIEVAL_DOCUMENT | מציינת שהטקסט הנתון הוא מסמך בהגדרת חיפוש/אחזור. |
| SEMANTIC_SIMILARITY | מציינת שהטקסט הנתון ישמש לדמיון סמנטי (STS). |
| סיווג | מציינת שההטמעות ישמשו לסיווג. |
| אשכול | מציינת שההטמעות ישמשו לקיבוץ לאשכולות. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
צמצום ממדים
אורך הווקטור של הטמעת המסמך הוא 768. כדי להמחיש את אופן קיבוץ המסמכים המוטמעים יחד, צריך להשתמש בתכונה 'הפחתת מידות', מכיוון שניתן להמחיש את ההטמעות רק בסביבה דו-ממדית או בתלת-ממד. מסמכים דומים לפי הקשר צריכים להיות קרובים יותר זה לזה במרחב, בניגוד למסמכים שאינם דומים זה לזה.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
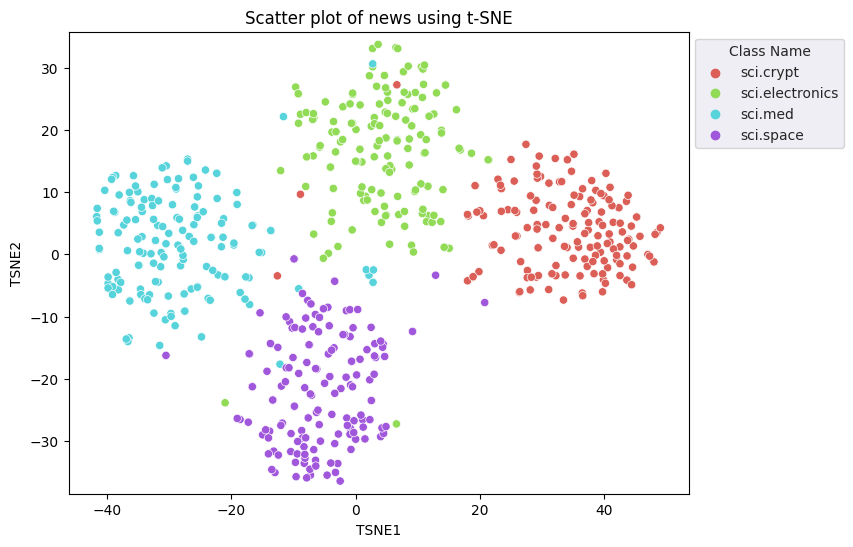
תפעילו את הגישה של הטמעה של שכנות סטוכסטיות ב-t (t-SNE) כדי לבצע הפחתת ממדים. השיטה הזו מצמצמת את מספר המאפיינים תוך שימור אשכולות (נקודות שקרובות זו לזו נשארות קרובות זו לזו). המודל מנסה ליצור התפלגות של הנתונים המקוריים, שבה נקודות נתונים אחרות הן "שכנות" (למשל, אם יש להן משמעות דומה). לאחר מכן, המערכת מבצעת אופטימיזציה של פונקציית יעד כדי לשמור על התפלגות דומה בתצוגה החזותית.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
השוואת התוצאות ל-KMeans
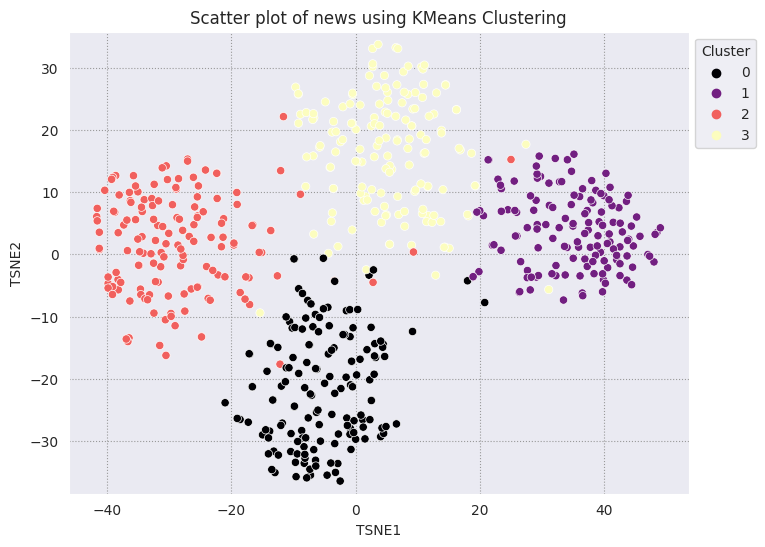
אשכולות KMeans הם אלגוריתם קיבוץ פופולרי ללמידה בלתי מונחית. הוא קובע באופן חזרתי את נקודות האמצע הטובות ביותר, ומקצה כל דוגמה למרכז הטיפוס הקרוב ביותר. מזינים את ההטמעות ישירות באלגוריתם של KMeans כדי להשוות בין ההדמיה של ההטמעות לביצועים של אלגוריתם של למידת מכונה.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
לקבל את רוב האשכולות לכל קבוצה, ולראות כמה מהחברים בפועל בקבוצה יש באשכול הזה.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
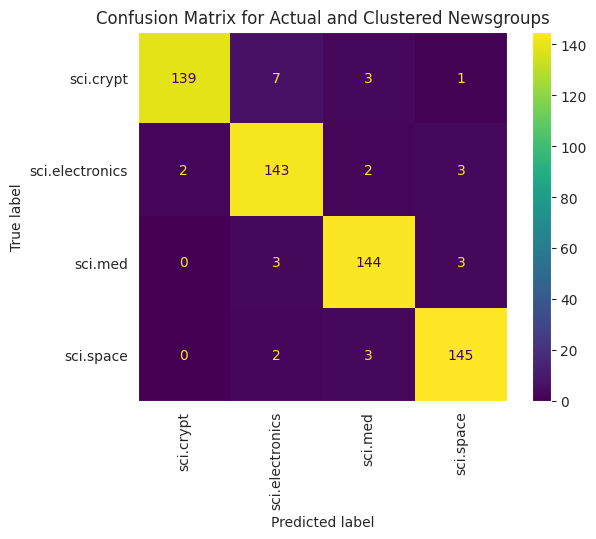
כדי להמחיש בצורה טובה יותר את הביצועים של KMeans על הנתונים, אפשר להשתמש במטריצה של מבוכים. מטריצת הבלבול מאפשרת להעריך את הביצועים של מודל הסיווג מעבר לרמת הדיוק. אתם יכולים לראות לאילו נקודות שסווגו באופן שגוי. לשם כך נדרשים הערכים בפועל והערכים החזויים, שאותם אספתם במסגרת הנתונים שלמעלה.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
השלבים הבאים
יצרתם עכשיו תרשימים להמחשה של הטמעות באמצעות אשכולות! נסו להשתמש בנתונים טקסטואליים משלכם כדי להמחיש אותן כהטמעות. אפשר לבצע הפחתת מידות כדי להשלים את שלב התצוגה החזותית. הערה: TSNE טוב לקיבוץ קלטים, אבל יכול להיות שייקח זמן רב יותר להתכנס או שהוא ייתקע בשלב המינימום המקומי. אם נתקלתם בבעיה הזו, כדאי לנסות שיטה נוספת היא ניתוח רכיבים עיקריים (PCA).
יש גם אלגוריתמים אחרים של קיבוץ לאשכולות מחוץ ל-KMeans, כמו קיבוץ מרחבי לפי צפיפות (DBSCAN).
למידע נוסף על שימוש בהטמעות, כדאי לעיין במדריכים הבאים: