
|
|
|
 Ver código fuente en GitHub Ver código fuente en GitHub
|
Descripción general
En este notebook, aprenderás a usar las incorporaciones que produce la API de Gemini para entrenar un modelo que pueda clasificar diferentes tipos de publicaciones de grupos de noticias según el tema.
En este instructivo, entrenarás un clasificador para predecir a qué clase pertenece una publicación de un grupo de noticias.
Requisitos previos
Puedes ejecutar esta guía de inicio rápido en Google Colab.
Para completar esta guía de inicio rápido en tu propio entorno de desarrollo, asegúrate de que tu entorno cumpla con los siguientes requisitos:
- Python 3.9 y versiones posteriores
- Una instalación de
jupyterpara ejecutar el notebook
Configuración
Primero, descarga e instala la biblioteca de Python de la API de Gemini.
pip install -U -q google.generativeai
import re
import tqdm
import keras
import numpy as np
import pandas as pd
import google.generativeai as genai
import google.ai.generativelanguage as glm
# Used to securely store your API key
from google.colab import userdata
import seaborn as sns
import matplotlib.pyplot as plt
from keras import layers
from matplotlib.ticker import MaxNLocator
from sklearn.datasets import fetch_20newsgroups
import sklearn.metrics as skmetrics
Obtén una clave de API
Para poder usar la API de Gemini, primero debes obtener una clave de API. Si aún no tienes una, crea una con un clic en Google AI Studio.
En Colab, agrega la clave al administrador de Secrets en la "automated" del panel izquierdo. Asígnale el nombre API_KEY.
Una vez que tengas la clave de API, pásala al SDK. Puedes hacerlo de dos maneras:
- Coloca la clave en la variable de entorno
GOOGLE_API_KEY(el SDK la recogerá automáticamente desde allí). - Pasa la llave a
genai.configure(api_key=...)
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
Conjunto de datos
El conjunto de datos de texto de 20 grupos de noticias contiene 18,000 publicaciones de grupos de noticias sobre 20 temas divididos en conjuntos de entrenamiento y pruebas. La división entre los conjuntos de datos de entrenamiento y de prueba se basa en los mensajes publicados antes y después de una fecha específica. Para este instructivo, usarás los subconjuntos de los conjuntos de datos de entrenamiento y prueba. Preprocesará y organizará los datos en DataFrames de Pandas.
newsgroups_train = fetch_20newsgroups(subset='train')
newsgroups_test = fetch_20newsgroups(subset='test')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
Este es un ejemplo de cómo se ve un dato del conjunto de entrenamiento.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
Ahora, comenzarás a procesar previamente los datos para este instructivo. Quita cualquier información sensible, como nombres, correos electrónicos o partes redundantes del texto, como "From: " y "\nSubject: ". Organizar la información en un DataFrame de Pandas para que sea más legible
def preprocess_newsgroup_data(newsgroup_dataset):
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroup_dataset.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroup_dataset.data] # Remove email
newsgroup_dataset.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroup_dataset.data] # Remove names
newsgroup_dataset.data = [d.replace("From: ", "") for d in newsgroup_dataset.data] # Remove "From: "
newsgroup_dataset.data = [d.replace("\nSubject: ", "") for d in newsgroup_dataset.data] # Remove "\nSubject: "
# Cut off each text entry after 5,000 characters
newsgroup_dataset.data = [d[0:5000] if len(d) > 5000 else d for d in newsgroup_dataset.data]
# Put data points into dataframe
df_processed = pd.DataFrame(newsgroup_dataset.data, columns=['Text'])
df_processed['Label'] = newsgroup_dataset.target
# Match label to target name index
df_processed['Class Name'] = ''
for idx, row in df_processed.iterrows():
df_processed.at[idx, 'Class Name'] = newsgroup_dataset.target_names[row['Label']]
return df_processed
# Apply preprocessing function to training and test datasets
df_train = preprocess_newsgroup_data(newsgroups_train)
df_test = preprocess_newsgroup_data(newsgroups_test)
df_train.head()
A continuación, tomarás una muestra de algunos de los datos. Para ello, tomarás 100 datos en el conjunto de datos de entrenamiento y quitarás algunas de las categorías que ejecutarás en este instructivo. Elige las categorías de ciencia que quieres comparar.
def sample_data(df, num_samples, classes_to_keep):
df = df.groupby('Label', as_index = False).apply(lambda x: x.sample(num_samples)).reset_index(drop=True)
df = df[df['Class Name'].str.contains(classes_to_keep)]
# Reset the encoding of the labels after sampling and dropping certain categories
df['Class Name'] = df['Class Name'].astype('category')
df['Encoded Label'] = df['Class Name'].cat.codes
return df
TRAIN_NUM_SAMPLES = 100
TEST_NUM_SAMPLES = 25
CLASSES_TO_KEEP = 'sci' # Class name should contain 'sci' in it to keep science categories
df_train = sample_data(df_train, TRAIN_NUM_SAMPLES, CLASSES_TO_KEEP)
df_test = sample_data(df_test, TEST_NUM_SAMPLES, CLASSES_TO_KEEP)
df_train.value_counts('Class Name')
Class Name sci.crypt 100 sci.electronics 100 sci.med 100 sci.space 100 dtype: int64
df_test.value_counts('Class Name')
Class Name sci.crypt 25 sci.electronics 25 sci.med 25 sci.space 25 dtype: int64
Crea las incorporaciones
En esta sección, aprenderás a generar incorporaciones para un texto usando las incorporaciones de la API de Gemini. Para obtener más información sobre las incorporaciones, visita la guía de incorporaciones.
Cambios de la API a Embeddings embedding-001
Para el nuevo modelo de incorporaciones, hay un nuevo parámetro de tipo de tarea y el título opcional (solo válido con task_type=RETRIEVAL_DOCUMENT).
Estos parámetros nuevos se aplican solo a los modelos de incorporaciones más recientes.Los tipos de tareas son los siguientes:
| Tipo de tarea | Descripción |
|---|---|
| RETRIEVAL_QUERY | Especifica que el texto dado es una consulta en un parámetro de configuración de búsqueda/recuperación. |
| RETRIEVAL_DOCUMENT | Especifica que el texto dado de un documento en un parámetro de configuración de búsqueda y recuperación. |
| SEMANTIC_SIMILARITY | Especifica que el texto dado se usará para la similitud textual semántica (STS). |
| CLASIFICACIÓN | Especifica que las incorporaciones se usarán para la clasificación. |
| CLÚSTERES | Especifica que las incorporaciones se usarán para el agrupamiento en clústeres. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLASSIFICATION.
embedding = genai.embed_content(model=model,
content=text,
task_type="classification")
return embedding['embedding']
return embed_fn
def create_embeddings(model, df):
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
model = 'models/embedding-001'
df_train = create_embeddings(model, df_train)
df_test = create_embeddings(model, df_test)
0%| | 0/400 [00:00<?, ?it/s] 0%| | 0/100 [00:00<?, ?it/s]
df_train.head()
Compila un modelo de clasificación simple
Aquí, definirás un modelo simple con una capa oculta y un solo resultado de probabilidad de clase. La predicción corresponderá a la probabilidad de que un fragmento de texto sea una clase particular de noticias. Cuando crees tu modelo, Keras redistribuirá automáticamente los datos.
def build_classification_model(input_size: int, num_classes: int) -> keras.Model:
inputs = x = keras.Input(input_size)
x = layers.Dense(input_size, activation='relu')(x)
x = layers.Dense(num_classes, activation='sigmoid')(x)
return keras.Model(inputs=[inputs], outputs=x)
# Derive the embedding size from the first training element.
embedding_size = len(df_train['Embeddings'].iloc[0])
# Give your model a different name, as you have already used the variable name 'model'
classifier = build_classification_model(embedding_size, len(df_train['Class Name'].unique()))
classifier.summary()
classifier.compile(loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer = keras.optimizers.Adam(learning_rate=0.001),
metrics=['accuracy'])
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 768)] 0
dense (Dense) (None, 768) 590592
dense_1 (Dense) (None, 4) 3076
=================================================================
Total params: 593668 (2.26 MB)
Trainable params: 593668 (2.26 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
embedding_size
768
Entrena el modelo para clasificar grupos de noticias
Por último, puedes entrenar un modelo simple. Usa una pequeña cantidad de ciclos de entrenamiento para evitar el sobreajuste. El primer ciclo de entrenamiento tarda mucho más que el resto, porque las incorporaciones deben calcularse solo una vez.
NUM_EPOCHS = 20
BATCH_SIZE = 32
# Split the x and y components of the train and validation subsets.
y_train = df_train['Encoded Label']
x_train = np.stack(df_train['Embeddings'])
y_val = df_test['Encoded Label']
x_val = np.stack(df_test['Embeddings'])
# Train the model for the desired number of epochs.
callback = keras.callbacks.EarlyStopping(monitor='accuracy', patience=3)
history = classifier.fit(x=x_train,
y=y_train,
validation_data=(x_val, y_val),
callbacks=[callback],
batch_size=BATCH_SIZE,
epochs=NUM_EPOCHS,)
Epoch 1/20 /usr/local/lib/python3.10/dist-packages/keras/src/backend.py:5729: UserWarning: "`sparse_categorical_crossentropy` received `from_logits=True`, but the `output` argument was produced by a Softmax activation and thus does not represent logits. Was this intended? output, from_logits = _get_logits( 13/13 [==============================] - 1s 30ms/step - loss: 1.2141 - accuracy: 0.6675 - val_loss: 0.9801 - val_accuracy: 0.8800 Epoch 2/20 13/13 [==============================] - 0s 12ms/step - loss: 0.7580 - accuracy: 0.9400 - val_loss: 0.6061 - val_accuracy: 0.9300 Epoch 3/20 13/13 [==============================] - 0s 13ms/step - loss: 0.4249 - accuracy: 0.9525 - val_loss: 0.3902 - val_accuracy: 0.9200 Epoch 4/20 13/13 [==============================] - 0s 13ms/step - loss: 0.2561 - accuracy: 0.9625 - val_loss: 0.2597 - val_accuracy: 0.9400 Epoch 5/20 13/13 [==============================] - 0s 13ms/step - loss: 0.1693 - accuracy: 0.9700 - val_loss: 0.2145 - val_accuracy: 0.9300 Epoch 6/20 13/13 [==============================] - 0s 13ms/step - loss: 0.1240 - accuracy: 0.9850 - val_loss: 0.1801 - val_accuracy: 0.9600 Epoch 7/20 13/13 [==============================] - 0s 21ms/step - loss: 0.0931 - accuracy: 0.9875 - val_loss: 0.1623 - val_accuracy: 0.9400 Epoch 8/20 13/13 [==============================] - 0s 16ms/step - loss: 0.0736 - accuracy: 0.9925 - val_loss: 0.1418 - val_accuracy: 0.9600 Epoch 9/20 13/13 [==============================] - 0s 20ms/step - loss: 0.0613 - accuracy: 0.9925 - val_loss: 0.1315 - val_accuracy: 0.9700 Epoch 10/20 13/13 [==============================] - 0s 20ms/step - loss: 0.0479 - accuracy: 0.9975 - val_loss: 0.1235 - val_accuracy: 0.9600 Epoch 11/20 13/13 [==============================] - 0s 19ms/step - loss: 0.0399 - accuracy: 0.9975 - val_loss: 0.1219 - val_accuracy: 0.9700 Epoch 12/20 13/13 [==============================] - 0s 21ms/step - loss: 0.0326 - accuracy: 0.9975 - val_loss: 0.1158 - val_accuracy: 0.9700 Epoch 13/20 13/13 [==============================] - 0s 19ms/step - loss: 0.0263 - accuracy: 1.0000 - val_loss: 0.1127 - val_accuracy: 0.9700 Epoch 14/20 13/13 [==============================] - 0s 17ms/step - loss: 0.0229 - accuracy: 1.0000 - val_loss: 0.1123 - val_accuracy: 0.9700 Epoch 15/20 13/13 [==============================] - 0s 20ms/step - loss: 0.0195 - accuracy: 1.0000 - val_loss: 0.1063 - val_accuracy: 0.9700 Epoch 16/20 13/13 [==============================] - 0s 17ms/step - loss: 0.0172 - accuracy: 1.0000 - val_loss: 0.1070 - val_accuracy: 0.9700
Evaluar el rendimiento del modelo
Usar Keras Model.evaluate para obtener la pérdida y exactitud del conjunto de datos de prueba
classifier.evaluate(x=x_val, y=y_val, return_dict=True)
4/4 [==============================] - 0s 4ms/step - loss: 0.1070 - accuracy: 0.9700
{'loss': 0.10700511932373047, 'accuracy': 0.9700000286102295}
Una forma de evaluar el rendimiento del modelo es visualizar el rendimiento del clasificador. Usa plot_history para ver las tendencias de pérdida y precisión durante los ciclos de entrenamiento.
def plot_history(history):
"""
Plotting training and validation learning curves.
Args:
history: model history with all the metric measures
"""
fig, (ax1, ax2) = plt.subplots(1,2)
fig.set_size_inches(20, 8)
# Plot loss
ax1.set_title('Loss')
ax1.plot(history.history['loss'], label = 'train')
ax1.plot(history.history['val_loss'], label = 'test')
ax1.set_ylabel('Loss')
ax1.set_xlabel('Epoch')
ax1.legend(['Train', 'Validation'])
# Plot accuracy
ax2.set_title('Accuracy')
ax2.plot(history.history['accuracy'], label = 'train')
ax2.plot(history.history['val_accuracy'], label = 'test')
ax2.set_ylabel('Accuracy')
ax2.set_xlabel('Epoch')
ax2.legend(['Train', 'Validation'])
plt.show()
plot_history(history)
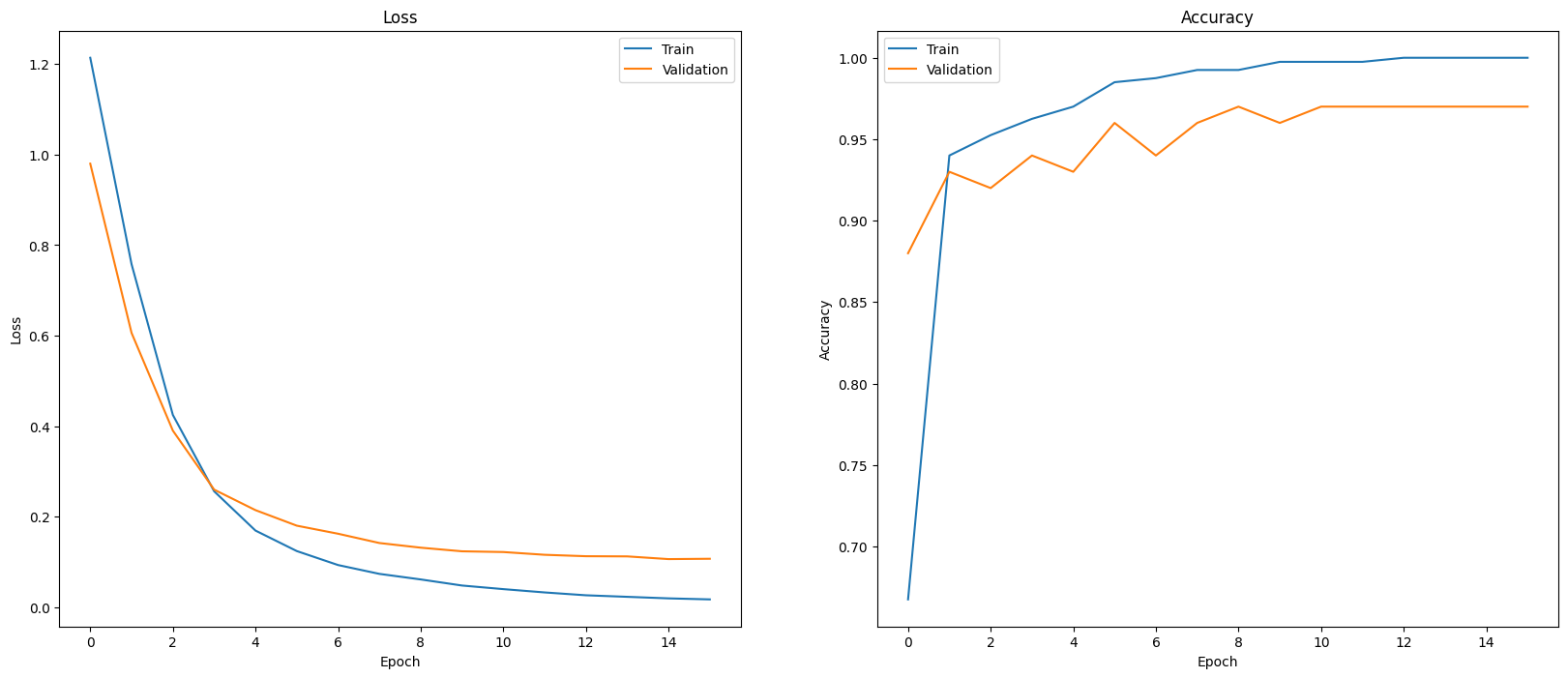
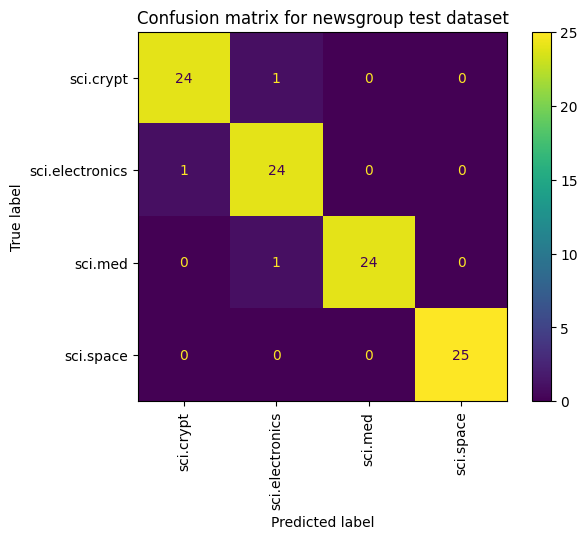
Otra forma de ver el rendimiento del modelo, más allá de solo medir la pérdida y la exactitud, es usar una matriz de confusión. La matriz de confusión te permite evaluar el rendimiento del modelo de clasificación más allá de la exactitud. Puedes ver en qué se clasifican los puntos mal clasificados. A fin de crear la matriz de confusión para este problema de clasificación de clases múltiples, obtén los valores reales en el conjunto de prueba y los valores predichos.
Comienza por generar la clase prevista para cada ejemplo en el conjunto de validación con Model.predict().
y_hat = classifier.predict(x=x_val)
y_hat = np.argmax(y_hat, axis=1)
4/4 [==============================] - 0s 4ms/step
labels_dict = dict(zip(df_test['Class Name'], df_test['Encoded Label']))
labels_dict
{'sci.crypt': 0, 'sci.electronics': 1, 'sci.med': 2, 'sci.space': 3}
cm = skmetrics.confusion_matrix(y_val, y_hat)
disp = skmetrics.ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=labels_dict.keys())
disp.plot(xticks_rotation='vertical')
plt.title('Confusion matrix for newsgroup test dataset');
plt.grid(False)
Próximos pasos
Para obtener más información sobre cómo usar las incorporaciones, consulta los ejemplos disponibles. Para obtener información sobre cómo usar otros servicios en la API de Gemini, visita la guía de inicio rápido de Python.