
La gestione delle richieste dei clienti, incluse le email, è una parte necessaria della gestione di molte attività, ma può diventare rapidamente ingestibile. Con un po' di impegno, i modelli di intelligenza artificiale (AI) come Gemma possono contribuire a semplificare questo lavoro.
Ogni attività gestisce le richieste come le email in modo leggermente diverso, quindi è importante essere in grado di adattare tecnologie come l'AI generativa alle esigenze della tua attività. Questo progetto affronta il problema specifico dell'estrazione di informazioni sugli ordini dalle email inviate a un panificio in dati strutturati, in modo che possano essere aggiunti rapidamente a un sistema di gestione degli ordini. Utilizzando da 10 a 20 esempi di richieste e dell'output che desideri, puoi ottimizzare un modello Gemma per elaborare le email dei tuoi clienti, aiutarti a rispondere rapidamente e integrarlo con i tuoi sistemi aziendali esistenti. Questo progetto è creato come pattern di applicazione AI che puoi estendere e adattare per ottenere valore dai modelli Gemma per la tua attività.
Per una panoramica video del progetto e su come estenderlo, inclusi approfondimenti delle persone che lo hanno creato, guarda il video Assistente AI per le email aziendali di Build with Google AI. Puoi anche esaminare il codice di questo progetto nel repository di codice di Gemma Cookbook. In caso contrario, puoi iniziare a estendere il progetto seguendo le istruzioni riportate di seguito.
Panoramica
Questo tutorial ti guida nella configurazione, nell'esecuzione e nell'estensione di un'applicazione di assistenza per le email aziendali creata con Gemma, Python e Flask. Il progetto fornisce un'interfaccia utente web di base che puoi modificare in base alle tue esigenze. L'applicazione è progettata per estrarre i dati dalle email dei clienti in una struttura per una panetteria fittizia. Puoi utilizzare questo pattern di applicazione per qualsiasi attività aziendale che utilizza l'input e l'output di testo.
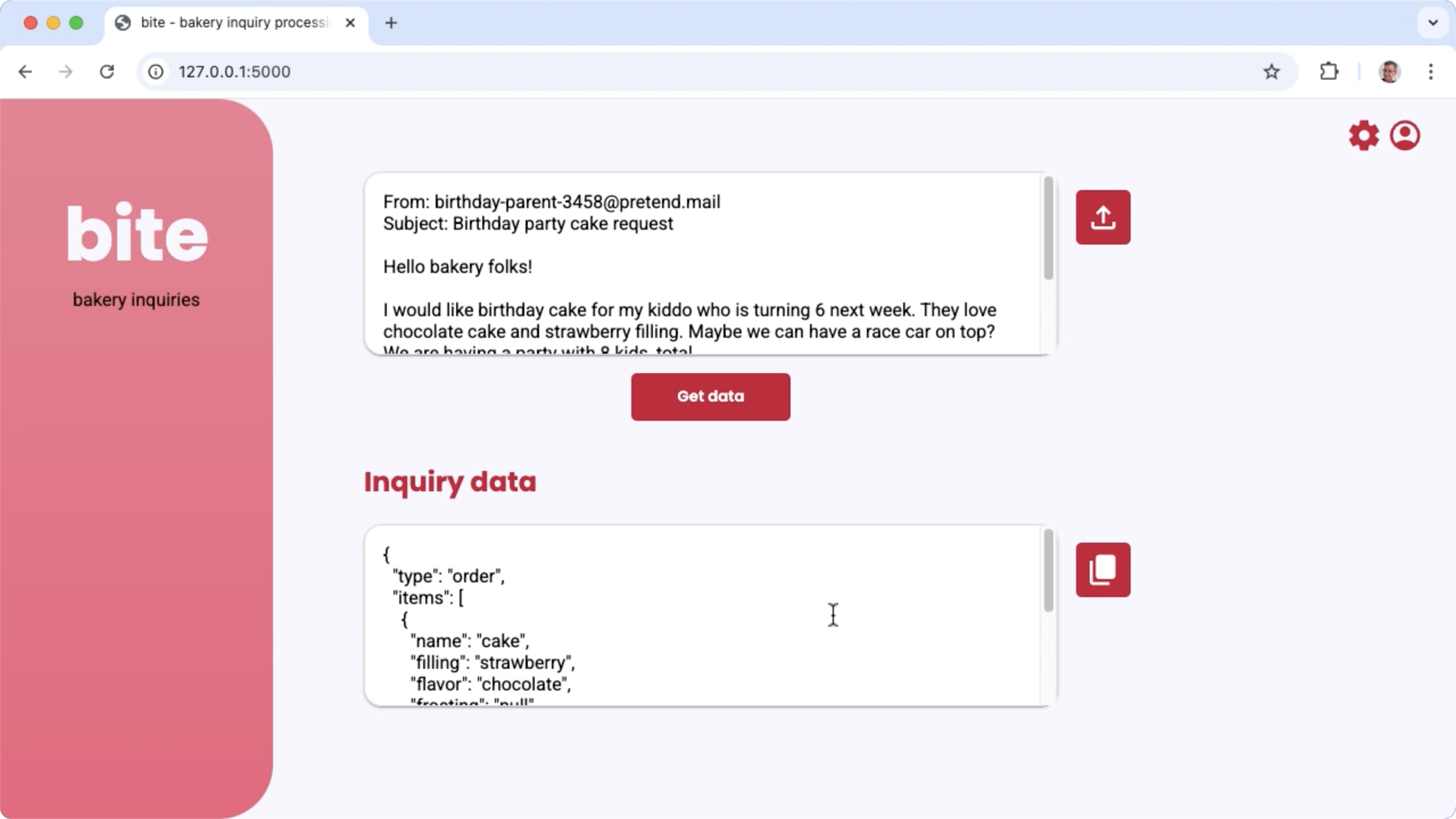
Figura 1. Interfaccia utente del progetto per l'elaborazione delle richieste via email della panetteria
Requisiti hardware
Esegui questo processo di ottimizzazione su un computer con un'unità di elaborazione grafica (GPU) o un'unità di elaborazione tensoriale (TPU) e una memoria GPU o TPU sufficiente per contenere il modello esistente, oltre ai dati di ottimizzazione. Per eseguire la configurazione di ottimizzazione in questo progetto, sono necessari circa 16 GB di memoria GPU, circa la stessa quantità di RAM normale e un minimo di 50 GB di spazio su disco.
Puoi eseguire la parte di ottimizzazione del modello Gemma di questo tutorial utilizzando un ambiente Colab con un runtime GPU T4. Se stai creando questo progetto su un'istanza VM di Google Cloud, configura l'istanza seguendo questi requisiti:
- Hardware GPU: per eseguire questo progetto è necessaria una NVIDIA T4 (consigliata NVIDIA L4 o versioni successive)
- Sistema operativo: scegli un'opzione Deep Learning su Linux, in particolare Deep Learning VM con CUDA 12.3 M124 con driver software GPU preinstallati.
- Dimensioni del disco di avvio: esegui il provisioning di almeno 50 GB di spazio su disco per dati, modelli e software di supporto.
Configurazione del progetto
Queste istruzioni ti guidano nella preparazione di questo progetto per lo sviluppo e il test. I passaggi di configurazione generali includono l'installazione del software prerequisito, la clonazione del progetto dal repository di codice, l'impostazione di alcune variabili di ambiente, l'installazione delle librerie Python e il test dell'applicazione web.
Installazione e configurazione
Questo progetto utilizza Python 3 e ambienti virtuali (venv) per gestire i pacchetti
ed eseguire l'applicazione. Le seguenti istruzioni di installazione sono per una macchina
host Linux.
Per installare il software richiesto:
Installa Python 3 e il pacchetto di ambiente virtuale
venvper Python:sudo apt update sudo apt install git pip python3-venv
Clona il progetto
Scarica il codice del progetto sul computer di sviluppo. Per recuperare il codice sorgente del progetto, devi disporre del software di controllo del codice sorgente git.
Per scaricare il codice del progetto:
Clona il repository Git utilizzando il seguente comando:
git clone https://github.com/google-gemini/gemma-cookbook.git(Facoltativo) Configura il repository Git locale in modo che utilizzi lo sparse checkout, in modo da avere solo i file per il progetto:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Installa le librerie Python
Installa le librerie Python con l'ambiente virtuale Python venv
attivato per gestire i pacchetti e le dipendenze Python. Assicurati di attivare l'ambiente virtuale Python prima di installare le librerie Python con il programma di installazione pip. Per ulteriori informazioni sull'utilizzo degli ambienti virtuali Python, consulta la documentazione
Python venv.
Per installare le librerie Python:
In una finestra del terminale, vai alla directory
business-email-assistant:cd Demos/business-email-assistant/Configura e attiva l'ambiente virtuale Python (venv) per questo progetto:
python3 -m venv venv source venv/bin/activateInstalla le librerie Python richieste per questo progetto utilizzando lo script
setup_python:./setup_python.sh
Imposta le variabili di ambiente
Per l'esecuzione di questo progetto sono necessarie alcune variabili di ambiente,
tra cui un nome utente Kaggle e un token API Kaggle. Per scaricarli, devi avere un account Kaggle e richiedere l'accesso ai modelli Gemma. Per
questo progetto, aggiungi il tuo nome utente Kaggle e il token API Kaggle a due file .env,
che vengono letti rispettivamente dall'applicazione web e dal programma di ottimizzazione.
Per impostare le variabili di ambiente:
- Ottieni il nome utente Kaggle e la chiave token seguendo le istruzioni riportate nella documentazione di Kaggle.
- Accedi al modello Gemma seguendo le istruzioni riportate nella pagina Configurazione di Gemma della sezione Accedere a Gemma.
- Crea file di variabili di ambiente per il progetto creando un file di testo
.envin ciascuna di queste posizioni nel clone del progetto:email-processing-webapp/.env model-tuning/.env
Dopo aver creato i file di testo
.env, aggiungi le seguenti impostazioni a entrambi i file:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Esegui e testa l'applicazione
Una volta completata l'installazione e la configurazione del progetto, esegui l'applicazione web per verificare di averla configurata correttamente. Ti consigliamo di eseguire questo controllo di base prima di modificare il progetto per il tuo utilizzo.
Per eseguire e testare il progetto:
In una finestra del terminale, vai alla directory
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Esegui l'applicazione utilizzando lo script
run_app:./run_app.shDopo aver avviato l'applicazione web, il codice del programma elenca un URL in cui puoi navigare ed eseguire test. In genere, questo indirizzo è:
http://127.0.0.1:5000/Nell'interfaccia web, premi il pulsante Ottieni dati sotto il primo campo di input per generare una risposta dal modello.
La prima risposta del modello dopo l'esecuzione dell'applicazione richiede più tempo perché deve completare i passaggi di inizializzazione alla prima esecuzione della generazione. Le richieste e la generazione di prompt successive su un'applicazione web già in esecuzione vengono completate in meno tempo.
Estendere l'applicazione
Una volta eseguita l'applicazione, puoi estenderla modificando l'interfaccia utente e la logica di business per adattarla alle attività pertinenti per te o per la tua attività. Puoi anche modificare il comportamento del modello Gemma utilizzando il codice dell'applicazione modificando i componenti del prompt che l'app invia al modello di AI generativa.
L'applicazione fornisce al modello le istruzioni insieme ai dati di input dell'utente un prompt completo del modello. Puoi modificare queste istruzioni per cambiare il comportamento del modello, ad esempio specificando i nomi dei parametri e la struttura del JSON da generare. Un modo più semplice per modificare il comportamento del modello è fornire istruzioni o indicazioni aggiuntive per la risposta del modello, ad esempio specificando che le risposte generate non devono includere la formattazione Markdown.
Per modificare le istruzioni del prompt:
- Nel progetto di sviluppo, apri il file di codice
business-email-assistant/email-processing-webapp/app.py. Nel codice
app.py, aggiungi istruzioni aggiuntive alla funzioneget_prompt()::def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
Questo esempio aggiunge la frase "senza ulteriore formattazione markdown" alle istruzioni.
Fornire istruzioni aggiuntive per il prompt può influenzare notevolmente l'output generato e richiede molto meno sforzo per l'implementazione. Ti consigliamo di provare prima questo metodo per vedere se riesci a ottenere il comportamento desiderato dal modello. Tuttavia, l'utilizzo di istruzioni del prompt per modificare il comportamento di un modello Gemma ha i suoi limiti. In particolare, il limite complessivo di token di input del modello, pari a 8192 token per Gemma 2, richiede di bilanciare le istruzioni dettagliate del prompt con le dimensioni dei nuovi dati forniti in modo da rimanere al di sotto di questo limite.
Ottimizza il modello
L'esecuzione del fine-tuning di un modello Gemma è il modo consigliato per ottenere risposte più affidabili per attività specifiche. In particolare, se vuoi che il modello generi JSON con una struttura specifica, inclusi parametri denominati in modo specifico, devi valutare la possibilità di ottimizzare il modello per questo comportamento. A seconda dell'attività che vuoi che il modello completi, puoi ottenere funzionalità di base con 10-20 esempi. Questa sezione del tutorial spiega come configurare ed eseguire l'ottimizzazione di un modello Gemma per un'attività specifica.
Le seguenti istruzioni spiegano come eseguire l'operazione di perfezionamento in un ambiente VM. Tuttavia, puoi eseguire questa operazione di ottimizzazione anche utilizzando il notebook Colab associato a questo progetto.
Requisiti hardware
I requisiti di calcolo per il fine-tuning sono gli stessi dei requisiti hardware per il resto del progetto. Puoi eseguire l'operazione di ottimizzazione in un ambiente Colab con un runtime GPU T4 se limiti i token di input a 256 e la dimensione del batch a 1.
Preparazione dei dati
Prima di iniziare a ottimizzare un modello Gemma, devi preparare i dati per l'ottimizzazione. Quando ottimizzi un modello per un'attività specifica, hai bisogno di un insieme di esempi di richieste e risposte. Questi esempi devono mostrare il testo della richiesta, senza alcuna istruzione, e il testo della risposta previsto. Per iniziare, devi preparare un set di dati con circa 10 esempi. Questi esempi devono rappresentare una gamma completa di richieste e le risposte ideali. Assicurati che le richieste e le risposte non siano ripetitive, in quanto ciò può causare risposte ripetitive da parte dei modelli e non adattarsi in modo appropriato alle variazioni delle richieste. Se stai ottimizzando il modello per produrre un formato di dati strutturati, assicurati che tutte le risposte fornite siano strettamente conformi al formato di output dei dati che desideri. La seguente tabella mostra alcuni record campione del set di dati di questo esempio di codice:
| Richiesta | Risposta |
|---|---|
| Gentile Indian Bakery Central,\nAvete per caso 10 penda e 30 bundi ladoo a portata di mano? Inoltre, vendete una glassa alla vaniglia e torte al cioccolato? Sto cercando una taglia da 15 cm. | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| Ho visto la tua attività su Google Maps. Vendi jellabi e gulab jamun? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
Tabella 1. Elenco parziale del set di dati di ottimizzazione per l'estrattore dei dati email della panetteria.
Formato e caricamento dei dati
Puoi archiviare i dati di ottimizzazione in qualsiasi formato conveniente, inclusi
record di database, file JSON, CSV o file di testo normale, purché tu abbia i
mezzi per recuperare i record con il codice Python. Questo progetto legge i file JSON
da una directory data in un array di oggetti dizionario.
In questo programma di ottimizzazione di esempio, il set di dati di ottimizzazione viene caricato nel modulo model-tuning/main.py utilizzando la funzione prepare_tuning_dataset():
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
Come accennato in precedenza, puoi archiviare il set di dati in un formato conveniente, a condizione che tu possa recuperare le richieste con le risposte associate e assemblarle in una stringa di testo che viene utilizzata come record di ottimizzazione.
Assemblare i record di ottimizzazione
Per il processo di ottimizzazione vero e proprio, il programma assembla ogni richiesta e risposta
in un'unica stringa con le istruzioni del prompt e il contenuto della
risposta. Il programma di ottimizzazione tokenizza quindi la stringa per l'utilizzo da parte del modello. Puoi visualizzare il codice per assemblare un record di ottimizzazione nella funzione
model-tuning/main.py del modulo prepare_tuning_dataset(), come segue:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
Questa funzione accetta i dati come input e li formatta aggiungendo un'interruzione di riga tra l'istruzione e la risposta.
Genera i pesi del modello
Una volta caricati i dati di ottimizzazione, puoi eseguire il programma di ottimizzazione. Il processo di ottimizzazione per questa applicazione di esempio utilizza la libreria Keras NLP per ottimizzare il modello con una tecnica di adattamento a basso rango o LoRA, per generare nuovi pesi del modello. Rispetto alla messa a punto a precisione completa, l'utilizzo di LoRA è molto più efficiente in termini di memoria perché approssima le modifiche ai pesi del modello. Puoi quindi sovrapporre queste ponderazioni approssimative alle ponderazioni del modello esistente per modificarne il comportamento.
Per eseguire l'ottimizzazione e calcolare i nuovi pesi:
In una finestra del terminale, vai alla directory
model-tuning/.cd business-email-assistant/model-tuning/Esegui la procedura di ottimizzazione utilizzando lo script
tune_model:./tune_model.sh
La procedura di ottimizzazione richiede diversi minuti a seconda delle risorse di calcolo disponibili. Al termine, il programma di ottimizzazione scrive nuovi file di pesi *.h5
nella directory model-tuning/weights nel seguente formato:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
Risoluzione dei problemi
Se la messa a punto non viene completata correttamente, i motivi sono due:
- Esaurimento della memoria o delle risorse: questi errori si verificano quando la procedura di ottimizzazione richiede una memoria che supera la memoria GPU o CPU disponibile. Assicurati di non eseguire l'applicazione web durante l'esecuzione
della procedura di ottimizzazione. Se esegui l'ottimizzazione su un dispositivo con 16 GB di memoria GPU, assicurati che
token_limitsia impostato su 256 e chebatch_sizesia impostato su 1. - Driver GPU non installati o incompatibili con JAX: la procedura di ottimizzazione richiede che sul dispositivo di calcolo siano installati driver hardware compatibili con la versione delle librerie JAX. Per maggiori dettagli, consulta la documentazione sull'installazione di JAX.
Esegui il deployment del modello ottimizzato
Il processo di ottimizzazione genera più pesi in base ai dati di ottimizzazione e al numero totale di epoche impostato nell'applicazione di ottimizzazione. Per impostazione predefinita, il programma di ottimizzazione genera tre file di pesi del modello, uno per ogni epoca di ottimizzazione. Ogni epoca di ottimizzazione successiva produce pesi che riproducono in modo più accurato i risultati dei dati di ottimizzazione. Puoi visualizzare i tassi di accuratezza per ogni epoca nell'output del terminale del processo di ottimizzazione, come segue:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
Anche se vuoi che il tasso di precisione sia relativamente alto, intorno a 0,80, non vuoi che sia troppo alto o molto vicino a 1,00, perché ciò significa che i pesi si sono avvicinati troppo all'overfitting dei dati di ottimizzazione. In questo caso, il modello non funziona bene con le richieste significativamente diverse dagli esempi di ottimizzazione. Per impostazione predefinita, lo script di deployment sceglie i pesi dell'epoca 3, che in genere hanno un tasso di precisione intorno a 0,80.
Per eseguire il deployment dei pesi generati nell'applicazione web:
In una finestra del terminale, vai alla directory
model-tuning:cd business-email-assistant/model-tuning/Esegui la procedura di ottimizzazione utilizzando lo script
deploy_weights:./deploy_weights.sh
Dopo aver eseguito questo script, dovresti visualizzare un nuovo file *.h5 nella directory email-processing-webapp/weights/.
Testare il nuovo modello
Dopo aver eseguito il deployment dei nuovi pesi nell'applicazione, è il momento di provare il modello appena ottimizzato. Per farlo, esegui di nuovo l'applicazione web e genera una risposta.
Per eseguire e testare il progetto:
In una finestra del terminale, vai alla directory
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Esegui l'applicazione utilizzando lo script
run_app:./run_app.shDopo aver avviato l'applicazione web, il codice del programma elenca un URL in cui puoi navigare ed eseguire test. In genere, questo indirizzo è:
http://127.0.0.1:5000/Nell'interfaccia web, premi il pulsante Ottieni dati sotto il primo campo di input per generare una risposta dal modello.
Ora hai eseguito l'addestramento e il deployment di un modello Gemma in un'applicazione. Sperimenta con l'applicazione e cerca di determinare i limiti della capacità di generazione del modello ottimizzato per la tua attività. Se trovi scenari in cui il modello non funziona bene, valuta la possibilità di aggiungere alcune di queste richieste all'elenco di dati di esempio per l'ottimizzazione aggiungendo la richiesta e fornendo una risposta ideale. Quindi, esegui nuovamente la procedura di ottimizzazione, esegui nuovamente il deployment dei nuovi pesi e testa l'output.
Risorse aggiuntive
Per saperne di più su questo progetto, consulta il repository di codice di Gemma Cookbook. Se hai bisogno di aiuto per creare l'applicazione o vuoi collaborare con altri sviluppatori, consulta il server Discord della community di Google Developers. Per altri progetti di Build with Google AI, consulta la playlist di video.