Imagen è il modello di generazione di immagini ad alta fedeltà di Google, in grado di generare immagini realistiche e di alta qualità da prompt di testo. Tutte le immagini generate includono una filigrana SynthID. Per saperne di più sulle varianti del modello Imagen disponibili, consulta la sezione Versioni del modello.
Migrazione a Nano Banana
I modelli Imagen sono ritirati e verranno disattivati il 17 agosto 2026. Ti consigliamo di eseguire la migrazione a Nano Banana per le tue esigenze di generazione di immagini.
La migrazione comporta le seguenti modifiche:
- Nome modello: utilizza
gemini-2.5-flash-imageanziché i nomi dei modelli Imagen. - Metodo: utilizza
client.models.generate_contental posto diclient.models.generate_images. - Gestione delle risposte: Nano Banana restituisce parti di contenuti, che possono includere dati immagine, anziché un oggetto di risposta immagine specifico.
Per ulteriori dettagli ed esempi, consulta la guida alla generazione di immagini.
Genera immagini utilizzando i modelli Imagen
Questo esempio mostra la generazione di immagini con un modello Imagen:
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
REST
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

Configurazione di Imagen
Al momento Imagen supporta solo i prompt in inglese e i seguenti parametri:
numberOfImages: il numero di immagini da generare, da 1 a 4 (incluso). Il valore predefinito è 4.imageSize: la dimensione dell'immagine generata. Questa funzionalità è supportata solo per i modelli Standard e Ultra. I valori supportati sono1Ke2K. Il valore predefinito è1K.aspectRatio: modifica le proporzioni dell'immagine generata. I valori supportati sono"1:1","3:4","4:3","9:16"e"16:9". Il valore predefinito è"1:1".personGeneration: Consente al modello di generare immagini di persone. Sono supportati i seguenti valori:"dont_allow": Blocca la generazione di immagini di persone."allow_adult": genera immagini di adulti, ma non di bambini. Questa è l'impostazione predefinita."allow_all": Genera immagini che includono adulti e bambini.
Guida ai prompt di Imagen
Questa sezione della guida di Imagen mostra come la modifica di un prompt da testo a immagine possa produrre risultati diversi, insieme a esempi di immagini che puoi creare.
Nozioni di base sulla scrittura di prompt
Un buon prompt è descrittivo e chiaro e utilizza parole chiave e modificatori significativi. Inizia pensando al soggetto, al contesto e allo stile.

Soggetto: la prima cosa a cui pensare con qualsiasi prompt è il soggetto: l'oggetto, la persona, l'animale o il paesaggio di cui vuoi un'immagine.
Contesto e sfondo: altrettanto importante è lo sfondo o il contesto in cui verrà inserito il soggetto. Prova a posizionare il soggetto in una varietà di sfondi. Ad esempio, uno studio con sfondo bianco, all'aperto o in ambienti interni.
Stile:infine, aggiungi lo stile dell'immagine che vuoi. Gli stili possono essere generali (pittura, fotografia, schizzi) o molto specifici (pittura a pastello, disegno a carboncino, 3D isometrico). Puoi anche combinare gli stili.
Dopo aver scritto una prima versione del prompt, perfezionalo aggiungendo più dettagli finché non ottieni l'immagine che desideri. L'iterazione è importante. Inizia definendo l'idea principale, poi perfezionala ed espandila finché l'immagine generata non si avvicina alla tua visione.

|

|

|
I modelli Imagen possono trasformare le tue idee in immagini dettagliate, indipendentemente dalla lunghezza e dal livello di dettaglio dei prompt. Perfeziona la tua visione attraverso prompt iterativi, aggiungendo dettagli finché non ottieni il risultato perfetto.
|
I prompt brevi ti consentono di generare rapidamente un'immagine. 
|
I prompt più lunghi ti consentono di aggiungere dettagli specifici e creare l'immagine. 
|
Altri suggerimenti per la scrittura di prompt per Imagen:
- Utilizza un linguaggio descrittivo: impiega aggettivi e avverbi dettagliati per delineare un quadro chiaro per Imagen.
- Fornisci il contesto: se necessario, includi informazioni di base per aiutare l'AI a comprendere.
- Fai riferimento ad artisti o stili specifici: se hai in mente un'estetica particolare, fare riferimento ad artisti o movimenti artistici specifici può essere utile.
- Utilizza strumenti di prompt engineering: valuta la possibilità di esplorare strumenti o risorse di prompt engineering per perfezionare i prompt e ottenere risultati ottimali.
- Migliorare i dettagli del viso nelle immagini personali e di gruppo: specifica i dettagli del viso come punto focale della foto (ad esempio, utilizza la parola "ritratto" nel prompt).
Generare testo nelle immagini
I modelli Imagen possono aggiungere testo alle immagini, aprendo nuove possibilità di generazione di immagini creative. Segui queste indicazioni per sfruttare al meglio questa funzionalità:
- Itera con sicurezza: potresti dover rigenerare le immagini finché non ottieni l'aspetto che desideri. L'integrazione del testo di Imagen è ancora in fase di sviluppo e a volte più tentativi danno i risultati migliori.
- Mantienilo breve: limita il testo a un massimo di 25 caratteri per una generazione ottimale.
Più frasi: prova due o tre frasi distinte per fornire informazioni aggiuntive. Evita di superare le tre frasi per composizioni più pulite.

Prompt: un poster con il testo "Summerland" in grassetto come titolo, sotto il quale si trova lo slogan "L'estate non è mai stata così bella" Posizionamento guidato: anche se Imagen può tentare di posizionare il testo come indicato, prevedi variazioni occasionali. Questa funzionalità è in continuo miglioramento.
Stile del carattere di ispirazione: specifica uno stile del carattere generale per influenzare in modo sottile le scelte di Imagen. Non fare affidamento sulla replica precisa del carattere, ma prevedi interpretazioni creative.
Dimensioni carattere: specifica le dimensioni del carattere o un'indicazione generale delle dimensioni (ad esempio piccole, medie, grandi) per influire sulla generazione delle dimensioni del carattere.
Parametrizzazione dei prompt
Per controllare meglio i risultati dell'output, potrebbe essere utile parametrizzare gli input in Imagen. Ad esempio, supponiamo che tu voglia che i tuoi clienti possano generare loghi per la loro attività e che venga sempre generato un logo su uno sfondo a tinta unita. Vuoi anche limitare le opzioni che il cliente può selezionare da un menu.
In questo esempio, puoi creare un prompt con parametri simile al seguente:
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.Nell'interfaccia utente personalizzata, il cliente può inserire i parametri utilizzando un menu e il valore scelto viene inserito nel prompt ricevuto da Imagen.
Ad esempio:
Prompt:
A minimalist logo for a health care company on a solid color background. Include the text Journey.
Prompt:
A modern logo for a software company on a solid color background. Include the text Silo.
Prompt:
A traditional logo for a baking company on a solid color background. Include the text Seed.
Tecniche avanzate di scrittura dei prompt
Utilizza i seguenti esempi per creare prompt più specifici in base ad attributi come descrittori di fotografia, forme e materiali, movimenti artistici storici e modificatori della qualità dell'immagine.
Fotografia
- Il prompt include: "Una foto di…"
Per utilizzare questo stile, inizia con parole chiave che indichino chiaramente a Imagen che stai cercando una fotografia. Inizia i prompt con "Una foto di…" . .". Ad esempio:

|

|

|
Origine immagine: ogni immagine è stata generata utilizzando il prompt di testo corrispondente con il modello Imagen 4.
Modificatori di fotografia
Negli esempi seguenti puoi vedere diversi modificatori e parametri specifici per la fotografia. Puoi combinare più modificatori per un controllo più preciso.
Prossimità della fotocamera - Primo piano, scattato da lontano

Prompt: una foto in primo piano di chicchi di caffè 
Prompt: una foto con lo zoom diminuito di un piccolo sacchetto di
chicchi di caffè in una cucina disordinataPosizione della videocamera: aerea, dal basso

Prompt: foto aerea di una città urbana con grattacieli 
Prompt: una foto della chioma di una foresta con cielo azzurro dal basso Illuminazione: naturale, suggestiva, calda, fredda

Prompt: foto di una poltrona moderna in studio, luce naturale 
Prompt: foto di una poltrona moderna in studio, illuminazione drammatica Impostazioni della fotocamera - sfocatura movimento, sfocatura diffusa, bokeh, ritratto

Prompt: foto di una città con grattacieli dall'interno di un'auto con sfocatura del movimento 
Prompt: fotografia con sfocatura diffusa di un ponte in una città di notte Tipi di obiettivi: 35 mm, 50 mm, fisheye, grandangolare, macro

Prompt: foto di una foglia, obiettivo macro 
Prompt: street photography, new york city, fisheye lens Tipi di pellicola: bianco e nero, polaroid

Prompt: un ritratto in stile polaroid di un cane che indossa occhiali da sole 
Prompt: foto in bianco e nero di un cane che indossa occhiali da sole
Origine immagine: ogni immagine è stata generata utilizzando il prompt di testo corrispondente con il modello Imagen 4.
Illustrazione e arte
- Il prompt include: "Un painting di…", "Un sketch di…"
Gli stili artistici variano dagli stili monocromatici come gli schizzi a matita all'arte digitale iperrealistica. Ad esempio, le seguenti immagini utilizzano lo stesso prompt con stili diversi:
"Un [art style or creation technique] di una berlina elettrica sportiva angolare con grattacieli sullo sfondo"

|

|

|

|

|

|
Origine immagine: ogni immagine è stata generata utilizzando il prompt di testo corrispondente con il modello Imagen 2.
Forme e materiali
- Il prompt include: "...fatto di...", "...a forma di..."
Uno dei punti di forza di questa tecnologia è la possibilità di creare immagini che altrimenti sarebbero difficili o impossibili. Ad esempio, puoi ricreare il logo della tua azienda con materiali e trame diversi.

|

|

|
Origine immagine: ogni immagine è stata generata utilizzando il prompt di testo corrispondente con il modello Imagen 4.
Riferimenti all'arte storica
- Il prompt include: "...nello stile di..."
Nel corso degli anni, alcuni stili sono diventati iconici. Di seguito sono riportate alcune idee di stili di pittura o artistici storici che puoi provare.
"genera un'immagine nello stile di [art period or movement] : un parco eolico"

|

|

|
Origine immagine: ogni immagine è stata generata utilizzando il prompt di testo corrispondente con il modello Imagen 4.
Modificatori della qualità delle immagini
Determinate parole chiave possono indicare al modello che stai cercando un asset di alta qualità. Ecco alcuni esempi di modificatori della qualità:
- Modificatori generali: di alta qualità, bellissimo, stilizzato
- Foto - 4K, HDR, Studio Photo
- Arte, illustrazione - di un professionista, dettagliata
Di seguito sono riportati alcuni esempi di prompt senza modificatori di qualità e lo stesso prompt con modificatori di qualità.

|

photo of a corn stalk taken by a professional photographer |
Origine immagine: ogni immagine è stata generata utilizzando il prompt di testo corrispondente con il modello Imagen 4.
Proporzioni
La generazione di immagini con Imagen ti consente di impostare cinque proporzioni distinte per le immagini.
- Quadrato (1:1, predefinito): una foto quadrata standard. Gli utilizzi comuni di questo formato includono i post sui social media.
Schermo intero (4:3): queste proporzioni sono di uso comune nei media o nei film. Sono anche le dimensioni della maggior parte delle vecchie TV (non widescreen) e delle fotocamere di medio formato. Acquisisce una porzione più ampia della scena in orizzontale (rispetto a 1:1), il che la rende una proporzione preferita per la fotografia.

Prompt: primo piano delle dita di un musicista che suona il pianoforte, film in bianco e nero, vintage (proporzioni 4:3) 
Prompt: una foto professionale di patatine fritte per un ristorante di lusso, nello stile di una rivista di cucina (proporzioni 4:3) Verticale a schermo intero (3:4): si tratta delle proporzioni a schermo intero ruotate di 90 gradi. Ciò consente di catturare più scena in verticale rispetto alle proporzioni 1:1.

Prompt: una donna che fa un'escursione, primo piano dei suoi scarponi riflessi in una pozzanghera, grandi montagne sullo sfondo, nello stile di una pubblicità, angolazioni drammatiche (proporzioni 3:4) 
Prompt: scatto aereo di un fiume che scorre in una valle mistica (proporzioni 3:4) Widescreen (16:9): questo formato ha sostituito il 4:3 ed è ora il più comune per TV, monitor e schermi di cellulari (orizzontale). Utilizza questo formato quando vuoi catturare una porzione più ampia dello sfondo (ad esempio, paesaggi panoramici).

Prompt: un uomo vestito di bianco seduto sulla spiaggia, primo piano, luce dell'ora d'oro (proporzioni 16:9) Verticale (9:16): queste proporzioni sono widescreen, ma ruotate. Si tratta di un formato relativamente nuovo, reso popolare dalle app di video nel formato breve (ad esempio, YouTube Shorts). Utilizza questa opzione per oggetti alti con orientamenti verticali forti, come edifici, alberi, cascate o altri oggetti simili.

Prompt: rendering digitale di un enorme grattacielo moderno, grandioso, epico con un bellissimo tramonto sullo sfondo (proporzioni 9:16)
Immagini fotorealistiche
Versioni diverse del modello di generazione di immagini potrebbero offrire un mix di output artistici e fotorealistici. Utilizza le seguenti formule nei prompt per generare output più fotorealistici, in base al soggetto che vuoi generare.
| Caso d'uso | Tipo di obiettivo | Lunghezze focali | Ulteriori dettagli |
|---|---|---|---|
| Persone (ritratti) | Prime, zoom | 24-35mm | film in bianco e nero, film noir, profondità di campo, duotone (menziona due colori) |
| Cibo, insetti, piante (oggetti, natura morta) | Macro | 60-105mm | Dettagli elevati, messa a fuoco precisa, illuminazione controllata |
| Sport, fauna selvatica (movimento) | Zoom con teleobiettivo | 100-400mm | Tempo di esposizione rapido, tracciamento di azioni o movimenti |
| Astronomica, orizzontale (grandangolo) | Grandangolare | 10-24mm | Tempi di esposizione lunghi, messa a fuoco nitida, esposizione lunga, acqua o nuvole uniformi |
Ritratti
| Caso d'uso | Tipo di obiettivo | Lunghezze focali | Ulteriori dettagli |
|---|---|---|---|
| Persone (ritratti) | Prime, zoom | 24-35mm | film in bianco e nero, film noir, profondità di campo, duotone (menziona due colori) |
Utilizzando diverse parole chiave della tabella, Imagen può generare i seguenti ritratti:

|

|

|

|
Prompt: Una donna, ritratto 35 mm, duotoni blu e grigi
Modello: imagen-4.0-generate-001

|

|

|

|
Prompt: Una donna, ritratto 35 mm, film noir
Modello: imagen-4.0-generate-001
Oggetti
| Caso d'uso | Tipo di obiettivo | Lunghezze focali | Ulteriori dettagli |
|---|---|---|---|
| Cibo, insetti, piante (oggetti, natura morta) | Macro | 60-105mm | Dettagli elevati, messa a fuoco precisa, illuminazione controllata |
Utilizzando diverse parole chiave della tabella, Imagen può generare le seguenti immagini di oggetti:

|

|

|

|
Prompt: foglia di una pianta della preghiera, obiettivo macro, 60 mm
Modello: imagen-4.0-generate-001

|

|

|

|
Prompt: un piatto di pasta, obiettivo macro da 100 mm
Modello: imagen-4.0-generate-001
Movimento
| Caso d'uso | Tipo di obiettivo | Lunghezze focali | Ulteriori dettagli |
|---|---|---|---|
| Sport, fauna selvatica (movimento) | Zoom con teleobiettivo | 100-400mm | Tempo di esposizione rapido, tracciamento di azioni o movimenti |
Utilizzando diverse parole chiave della tabella, Imagen può generare le seguenti immagini in movimento:

|

|
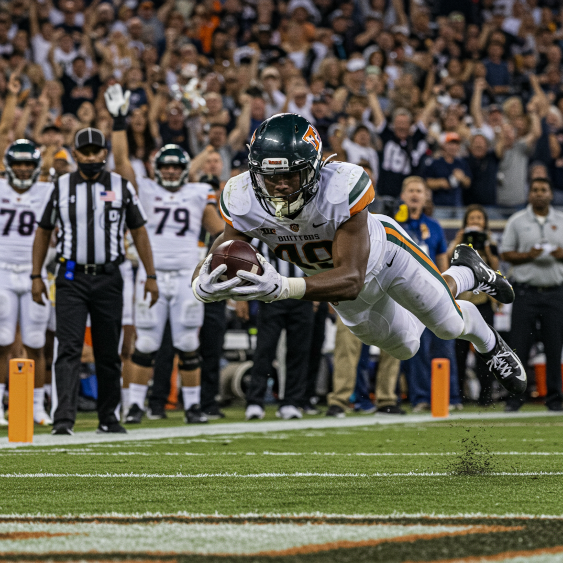
|

|
Prompt: un touchdown vincente, tempo di esposizione elevato, rilevamento del movimento
Modello: imagen-4.0-generate-001

|

|

|

|
Prompt: Un cervo che corre nella foresta, tempo di esposizione rapido, rilevamento del movimento
Modello: imagen-4.0-generate-001
Grandangolare
| Caso d'uso | Tipo di obiettivo | Lunghezze focali | Ulteriori dettagli |
|---|---|---|---|
| Astronomica, orizzontale (grandangolo) | Grandangolare | 10-24mm | Tempi di esposizione lunghi, messa a fuoco nitida, esposizione lunga, acqua o nuvole uniformi |
Utilizzando diverse parole chiave della tabella, Imagen può generare le seguenti immagini grandangolari:

|

|

|

|
Prompt: an expansive mountain range, landscape wide angle 10mm
Modello: imagen-4.0-generate-001

|

|

|

|
Prompt: una foto della luna, astrofotografia, grandangolo 10 mm
Modello: imagen-4.0-generate-001
Versioni modello
Imagen 4 (obsoleto)
| Proprietà | Descrizione |
|---|---|
| Codice modello |
API Gemini
|
| Tipi di dati supportati |
Ingresso Testo Output Immagini |
| Limiti dei token[*] |
Limite di token di input 480 token (testo) Immagini di output Da 1 a 4 (Ultra/Standard/Veloce) |
| Ultimo aggiornamento | Giugno 2025 |
Imagen 3
Il modello Imagen 3 è stato arrestato.