

MediaPipe Pose Landmarker 工作可讓您在圖片或影片中偵測人體地標。您可以使用這項工作來找出身體的重要位置、分析姿勢,以及分類動作。這項工作會使用機器學習 (ML) 模型,這些模型可處理單張圖片或影片。這項工作會以圖片座標和 3D 世界座標輸出人體姿勢地標。
開始使用
請按照目標平台的導入指南開始使用此工作。這些平台專屬指南將逐步引導您完成這項工作的基本實作方式,包括建議的模型,以及含有建議設定選項的程式碼範例:
任務詳細資料
本節說明此工作的功能、輸入內容、輸出內容和設定選項。
功能
- 輸入圖像處理:處理作業包括圖片旋轉、大小調整、標準化和色彩空間轉換。
- 分數門檻:根據預測分數篩選結果。
| 工作輸入內容 | 任務輸出 |
|---|---|
Pose Landmarker 接受下列任一資料類型的輸入:
|
Pose Landmarker 會輸出以下結果:
|
設定選項
此工作提供下列設定選項:
| 選項名稱 | 說明 | 值範圍 | 預設值 |
|---|---|---|---|
running_mode |
設定工作執行模式。共有三種模式: IMAGE:單一圖片輸入模式。 VIDEO:影片解碼影格模式。 LIVE_STREAM:輸入資料 (例如來自攝影機的資料) 的直播模式。 在這個模式中,必須呼叫 resultListener,才能設定事件監聽器,以非同步方式接收結果。 |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
Pose Landmarker 可偵測的姿勢數量上限。 | Integer > 0 |
1 |
min_pose_detection_confidence |
系統判定姿勢偵測成功的最低可信度分數。 | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
姿勢地標偵測中姿勢存在分數的最低可信度分數。 | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
系統判定姿勢追蹤成功的最低可信度分數。 | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
是否為偵測到的姿勢輸出區隔遮罩。 | Boolean |
False |
result_callback |
在 Pose Landmarker 處於即時串流模式時,將結果事件監聽器設為以非同步方式接收地標結果。只有在執行模式設為 LIVE_STREAM 時,才能使用 |
ResultListener |
N/A |
模型
姿勢地標會使用一系列模型來預測姿勢地標。第一個模型會偵測圖片框架內是否有人體,第二個模型則會找出人體上的地標。
下列模型會一起打包成可下載的模型套件:
- 姿勢偵測模型:偵測身體是否出現幾個關鍵姿勢地標。
- 姿勢地標模型:新增完整的姿勢對應項目。模型會輸出 33 個 3D 姿勢地標的預估值。
這個套件使用類似 MobileNetV2 的卷積神經網路,並針對裝置端即時健身應用程式進行最佳化。這個 BlazePose 模型的變化版本會使用 GHUM (一種 3D 人形模型管道),估算圖像或影片中人物的完整 3D 身體姿勢。
| 模型組合 | 輸入形狀 | 資料類型 | 模型資訊卡 | 版本 |
|---|---|---|---|---|
| Pose Landmarker (Lite) | 姿勢偵測器:224 x 224 x 3 姿勢標記:256 x 256 x 3 |
float 16 | info | 最新 |
| Pose 地標 (完整版) | 姿勢偵測器:224 x 224 x 3 姿勢標記:256 x 256 x 3 |
float 16 | info | 最新 |
| Pose 地標 (大量) | 姿勢偵測器:224 x 224 x 3 姿勢標記:256 x 256 x 3 |
float 16 | info | 最新 |
姿勢地標模型
姿勢地標模型會追蹤 33 個身體地標位置,代表下列身體部位的近似位置:
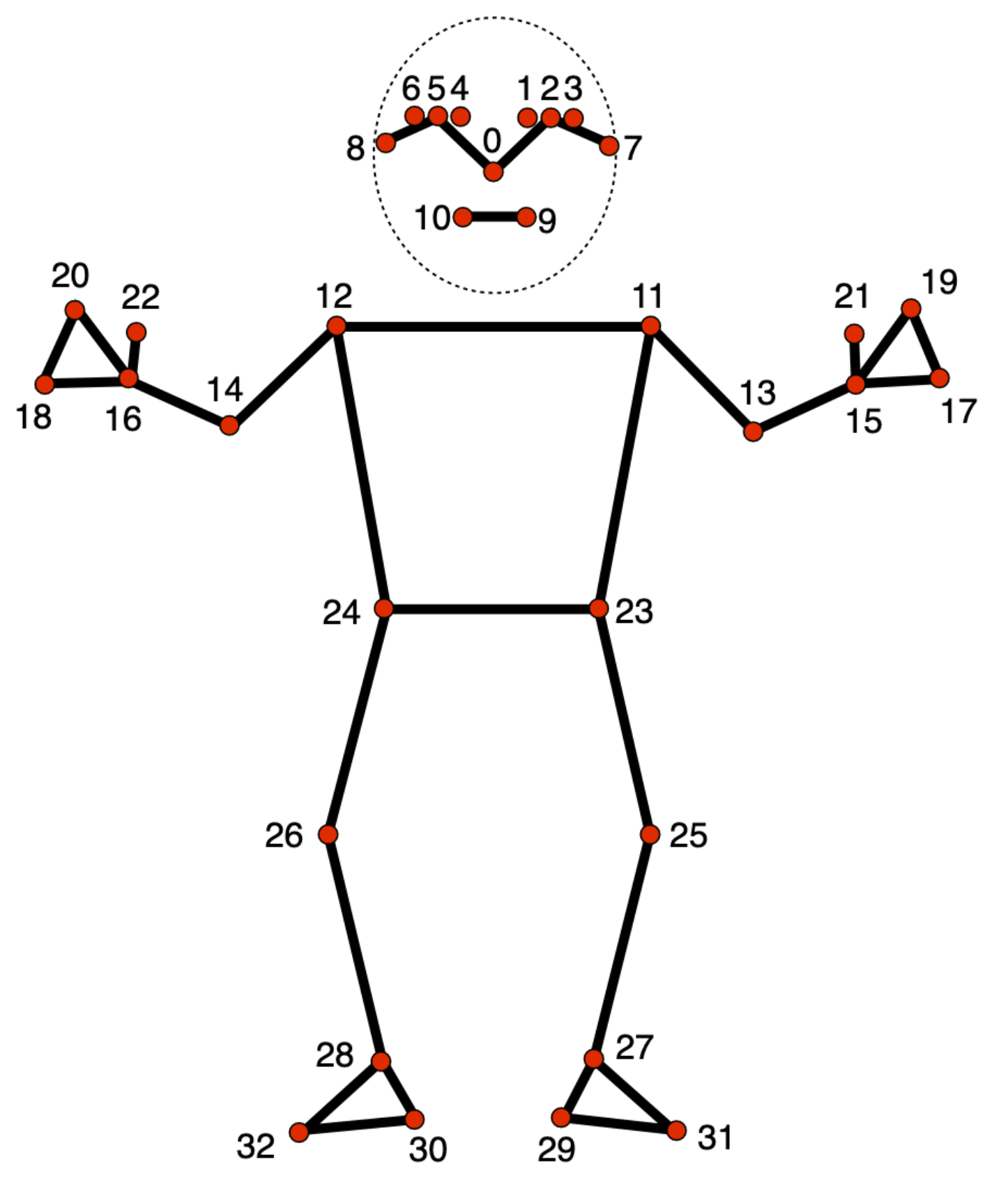
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
模型輸出內容包含每個地標的標準化座標 (Landmarks) 和世界座標 (WorldLandmarks)。