
並列評估已成為評估 大型語言模型 (LLM) 的回覆品質和安全性並排 我們會透過比較基準,選擇兩種不同的模式 就會產生提示不過 手動分析並排比較結果,可能相當耗時 真枯燥乏味。
LLM 比較工具是網路應用程式,搭配Python 程式庫,可透過互動式視覺化效果,更有效地分析並排評估。LLM 比較工具可協助您:
查看模型成效差異的「位置」:您可以分割回應 找出產生有意義的輸出內容評估資料子集 兩個模型的差異
瞭解差異的原因:通常會設有政策,針對模型成效和合規性進行評估。並列評估機制,協助自動遵循政策 並提出合理解釋 確保符合規定LLM 比較工具會將這些原因歸納為幾個主題,並標示出哪些模型與各主題較為吻合。
檢查模型輸出內容的差異:您可以進一步透過內建和使用者定義的比較函式,瞭解兩個模型的輸出內容有何差異。這項工具可在模型產生的文字中標示特定模式,提供明確的錨點,讓您瞭解兩者的差異。
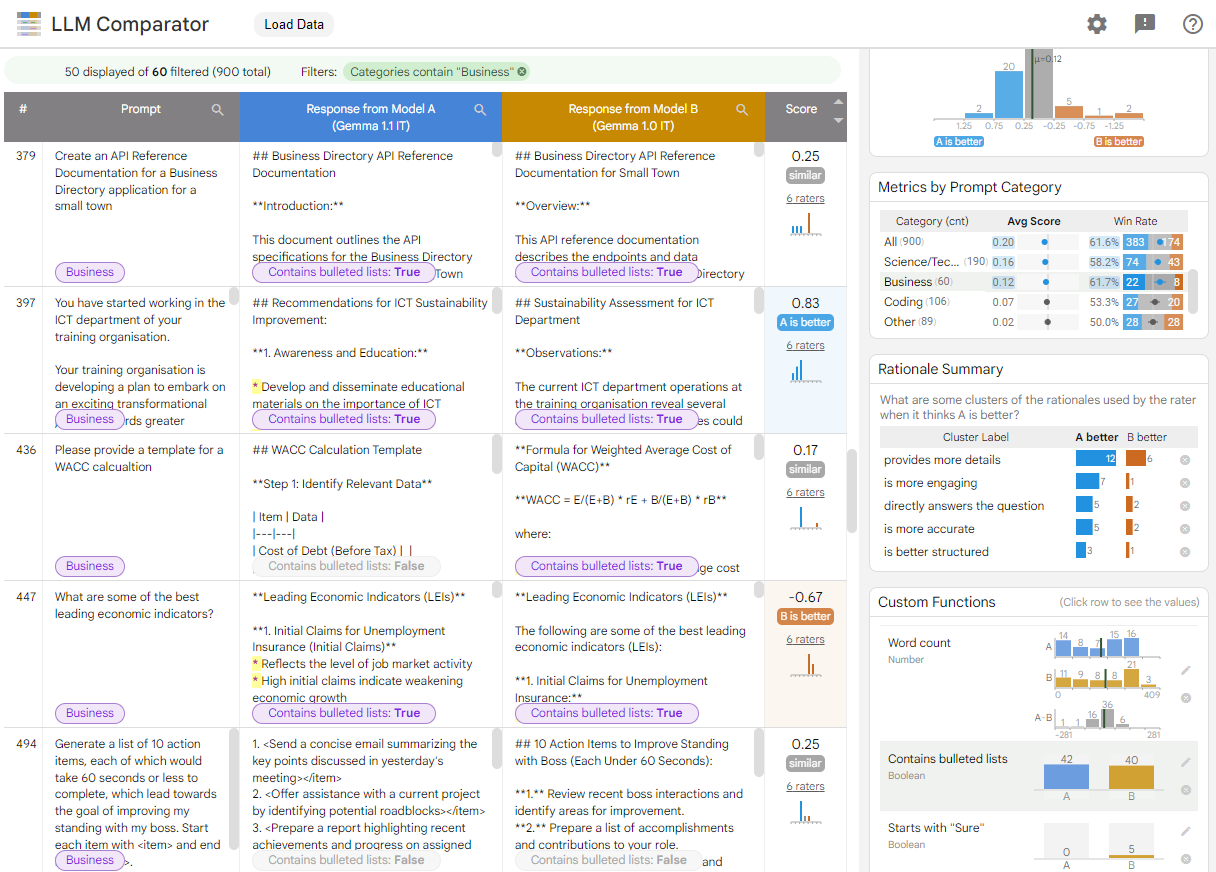
圖 1. 顯示 Gemma 比較結果的 LLM 比較工具介面 指示 7B v1.1 模型針對 v1.0
LLM 比較工具可協助您分析並排的評估結果。這項服務 從多個角度以圖表呈現模型成效,同時 並以互動方式檢查個別模型輸出內容,深入瞭解相關細節。
親自探索 LLM 比較工具:
- 這個示範比較 Gemma Instruct 7B 1.1 版和 Gemma Instruct 7B 1.0 版在Chatbot Arena Conversations 資料集上的效能。
- 這個 Colab 筆記本會使用 Python 程式庫執行 使用 Vertex AI API 並列評估,然後載入 結果轉換為儲存格中的 LLM Comparator 應用程式
如要進一步瞭解 LLM Comparator,請參閱研究論文和 GitHub 存放區。