L'API Gemini fornisce impostazioni di sicurezza che puoi regolare durante la fase di prototipazione per determinare se la tua applicazione richiede una configurazione di sicurezza più o meno restrittiva. Puoi regolare queste impostazioni in quattro categorie di filtri per limitare o consentire determinati tipi di contenuti.
Questa guida spiega come l'API Gemini gestisce le impostazioni di sicurezza e il filtraggio e come puoi modificare le impostazioni di sicurezza per la tua applicazione.
Filtri di sicurezza
I filtri di sicurezza regolabili dell'API Gemini coprono le seguenti categorie:
| Categoria | Descrizione |
|---|---|
| Molestie | Commenti negativi o dannosi che prendono di mira l'identità e/o gli attributi protetti |
| Incitamento all'odio | Contenuti scortesi, irrispettosi o blasfemi. |
| Contenuti sessualmente espliciti | Contiene riferimenti ad atti sessuali o altri contenuti osceni. |
| Contenuti pericolosi | Promuove, facilita o incoraggia atti dannosi. |
Queste categorie sono definite in HarmCategory. Puoi utilizzare questi filtri per regolare ciò che è appropriato per il tuo caso d'uso. Ad esempio, se stai creando dialoghi di videogiochi, potresti ritenere accettabile consentire più contenuti classificati come Contenuti pericolosi per via della natura del gioco.
Oltre ai filtri di sicurezza regolabili, l'API Gemini dispone di protezioni integrate contro i danni principali, come i contenuti che mettono a repentaglio la sicurezza dei bambini. Questi tipi di danni vengono sempre bloccati e non possono essere regolati.
Livello di filtraggio della sicurezza dei contenuti
L'API Gemini classifica il livello di probabilità che i contenuti non siano sicuri come HIGH, MEDIUM, LOW o NEGLIGIBLE.
L'API Gemini blocca i contenuti in base alla probabilità che non siano sicuri e non alla gravità. È importante tenerlo presente perché alcuni contenuti possono avere una bassa probabilità di non essere sicuri, anche se la gravità del danno potrebbe essere elevata. Ad esempio, confronta le seguenti frasi:
- Il robot mi ha dato un pugno.
- Il robot mi ha tagliato.
La prima frase potrebbe avere una probabilità maggiore di non essere sicura, ma potresti considerare la seconda frase più grave in termini di violenza. Per questo motivo, è importante testare attentamente e valutare il livello di blocco appropriato necessario per supportare i casi d'uso principali, riducendo al minimo i danni agli utenti finali.
Filtraggio di sicurezza per richiesta
Puoi regolare le impostazioni di sicurezza per ogni richiesta che invii all'API. Quando invii una richiesta, i contenuti vengono analizzati e viene assegnata una valutazione di sicurezza. La valutazione di sicurezza include la categoria e la probabilità della classificazione del danno. Ad esempio, se i contenuti sono stati bloccati perché la categoria delle molestie ha una probabilità elevata, la valutazione di sicurezza restituita avrà la categoria uguale a HARASSMENT e la probabilità di danno impostata su HIGH.
A causa della sicurezza intrinseca del modello, i filtri aggiuntivi sono disattivati per impostazione predefinita. Se scegli di attivarli, puoi configurare il sistema in modo che blocchi i contenuti in base alla probabilità che non siano sicuri. Il comportamento predefinito del modello copre la maggior parte dei casi d'uso, quindi dovresti regolare queste impostazioni solo se è un requisito costante per la tua applicazione.
La tabella seguente descrive le impostazioni di blocco che puoi regolare per ogni categoria. Ad esempio, se imposti l'impostazione di blocco su Blocco ridotto per la categoria Incitamento all'odio, tutto ciò che ha un'alta probabilità di essere un contenuto di incitamento all'odio viene bloccato. Tuttavia, tutto ciò che ha una probabilità inferiore è consentito.
| Soglia (Google AI Studio) | Soglia (API) | Descrizione |
|---|---|---|
| Off | OFF |
Disattiva il filtro di sicurezza |
| Nessun blocco | BLOCK_NONE |
Mostra sempre, indipendentemente dalla probabilità che i contenuti non siano sicuri |
| Blocco ridotto | BLOCK_ONLY_HIGH |
Blocca quando c'è un'alta probabilità che i contenuti non siano sicuri |
| Blocco limitato | BLOCK_MEDIUM_AND_ABOVE |
Blocca quando c'è una probabilità media o alta che i contenuti non siano sicuri |
| Blocco esteso | BLOCK_LOW_AND_ABOVE |
Blocca quando c'è una probabilità bassa, media o alta che i contenuti non siano sicuri |
| N/D | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
La soglia non è specificata, blocca utilizzando la soglia predefinita |
Se la soglia non è impostata, la soglia di blocco predefinita è Off per i modelli Gemini 2.5 e 3.
Puoi impostare queste impostazioni per ogni richiesta che invii al servizio generativo.
Per maggiori dettagli, consulta il riferimento API HarmBlockThreshold.
Feedback sulla sicurezza
generateContent
restituisce un
GenerateContentResponse che
include il feedback sulla sicurezza.
Il feedback sui prompt è incluso in
promptFeedback. Se promptFeedback.blockReason è impostato, i contenuti del prompt sono stati bloccati.
Il feedback sui candidati di risposta è incluso in
Candidate.finishReason e
Candidate.safetyRatings. Se i contenuti della risposta sono stati bloccati e finishReason era SAFETY, puoi esaminare safetyRatings per maggiori dettagli. I contenuti bloccati non vengono restituiti.
Regolare le impostazioni di sicurezza
Questa sezione spiega come regolare le impostazioni di sicurezza in Google AI Studio e nel codice.
Google AI Studio
Puoi regolare le impostazioni di sicurezza in Google AI Studio.
Fai clic su Impostazioni di sicurezza in Impostazioni avanzate nel riquadro Impostazioni di esecuzione per aprire la finestra modale Esegui impostazioni di sicurezza. Nella finestra modale, puoi utilizzare i cursori per regolare il livello di filtraggio dei contenuti per categoria di sicurezza:
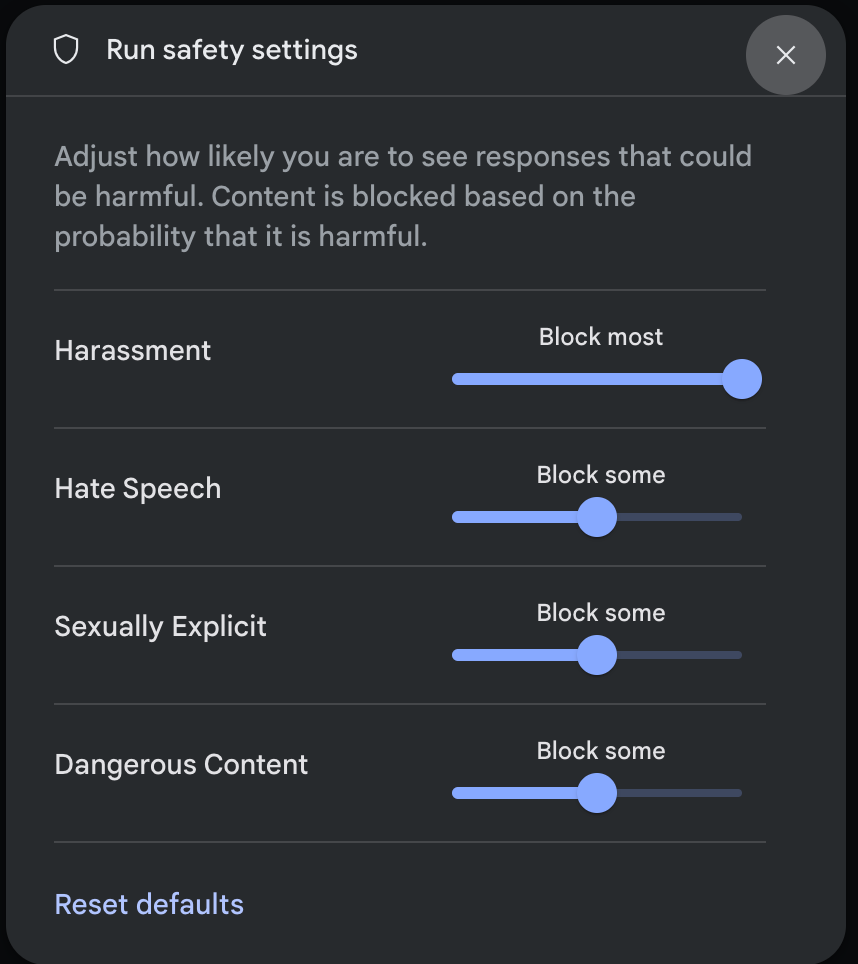
Quando invii una richiesta (ad esempio, ponendo una domanda al modello), viene visualizzato un messaggio Contenuti bloccati se i contenuti della richiesta vengono bloccati. Per visualizzare maggiori dettagli, tieni il puntatore sopra il testo Contenuti bloccati per visualizzare la categoria e la probabilità della classificazione del danno.
Esempi di codice
Il seguente snippet di codice mostra come impostare le impostazioni di sicurezza nella chiamata GenerateContent. Imposta la soglia per la categoria di incitamento all'odio (HARM_CATEGORY_HATE_SPEECH). Se imposti questa categoria su BLOCK_LOW_AND_ABOVE, vengono bloccati tutti i contenuti che hanno una probabilità bassa o superiore di essere di incitamento all'odio. Per comprendere le impostazioni della soglia, consulta Filtraggio di sicurezza
per richiesta.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Vai
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
Passaggi successivi
- Consulta il riferimento API per scoprire di più sull'API completa.
- Consulta le linee guida sulla sicurezza per una panoramica generale delle considerazioni sulla sicurezza durante lo sviluppo con i LLM.
- Scopri di più sulla valutazione della probabilità rispetto alla gravità dal team Jigsaw
- Scopri di più sui prodotti che contribuiscono alle soluzioni di sicurezza, come l' API Perspective. * Puoi utilizzare queste impostazioni di sicurezza per creare un classificatore di tossicità Per iniziare, consulta l'esempio di classificazione esempio per iniziare.