Gemini API menyediakan setelan keamanan yang dapat Anda sesuaikan selama tahap pembuatan prototipe untuk menentukan apakah aplikasi Anda memerlukan konfigurasi keamanan yang lebih ketat atau longgar. Anda dapat menyesuaikan setelan ini di empat kategori filter untuk membatasi atau mengizinkan jenis konten tertentu.
Panduan ini membahas cara Gemini API menangani setelan keamanan dan pemfilteran serta cara Anda dapat mengubah setelan keamanan untuk aplikasi Anda.
Filter keamanan
Filter keamanan Gemini API yang dapat disesuaikan mencakup kategori berikut:
| Kategori | Deskripsi |
|---|---|
| Pelecehan | Komentar negatif atau berbahaya yang menargetkan identitas dan/atau atribut yang dilindungi. |
| Ujaran kebencian | Konten yang kasar, tidak sopan, atau tidak senonoh. |
| Seksual vulgar | Berisi referensi ke tindakan seksual atau konten cabul lainnya. |
| Berbahaya | Mempromosikan, memfasilitasi, atau mendorong tindakan berbahaya. |
Kategori ini ditentukan dalam HarmCategory. Anda dapat menggunakan filter ini untuk menyesuaikan konten yang sesuai untuk kasus penggunaan Anda. Misalnya, jika Anda membuat dialog video game, Anda mungkin menganggapnya dapat diterima untuk mengizinkan lebih banyak konten yang diberi rating Berbahaya karena sifat game.
Selain filter keamanan yang dapat disesuaikan, Gemini API memiliki perlindungan bawaan terhadap bahaya inti, seperti konten yang membahayakan keselamatan anak. Jenis bahaya ini selalu diblokir dan tidak dapat disesuaikan.
Tingkat pemfilteran keamanan konten
Gemini API mengategorikan tingkat probabilitas konten yang tidak aman sebagai HIGH, MEDIUM, LOW, atau NEGLIGIBLE.
Gemini API memblokir konten berdasarkan probabilitas konten yang tidak aman, bukan tingkat keparahannya. Hal ini penting untuk dipertimbangkan karena beberapa konten memiliki kemungkinan rendah untuk dianggap tidak aman, meskipun tingkat keparahan bahayanya masih tinggi. Misalnya, membandingkan kalimat:
- Robot itu memukul saya.
- Robot itu menebas saya.
Kalimat pertama dapat menghasilkan probabilitas yang lebih tinggi untuk dianggap tidak aman, tetapi Anda dapat menganggap kalimat kedua sebagai tingkat keparahan yang lebih tinggi dalam hal kekerasan. Oleh karena itu, penting bagi Anda untuk menguji dengan cermat dan mempertimbangkan tingkat pemblokiran yang sesuai yang diperlukan untuk mendukung kasus penggunaan utama Anda sekaligus meminimalkan bahaya bagi pengguna akhir.
Pemfilteran keamanan per permintaan
Anda dapat menyesuaikan setelan keamanan untuk setiap permintaan yang Anda buat ke API. Saat Anda membuat permintaan, konten akan dianalisis dan diberi rating keamanan. Rating keamanan mencakup kategori dan probabilitas klasifikasi bahaya. Misalnya, jika konten diblokir karena kategori pelecehan memiliki probabilitas tinggi, rating keamanan yang ditampilkan akan memiliki kategori yang sama dengan HARASSMENT dan probabilitas bahaya yang ditetapkan ke HIGH.
Karena keamanan bawaan model, filter tambahan Nonaktif secara default. Jika memilih untuk mengaktifkannya, Anda dapat mengonfigurasi sistem untuk memblokir konten berdasarkan probabilitasnya yang tidak aman. Perilaku model default mencakup sebagian besar kasus penggunaan, sehingga Anda hanya perlu menyesuaikan setelan ini jika secara konsisten diperlukan untuk aplikasi Anda.
Tabel berikut menjelaskan setelan blokir yang dapat Anda sesuaikan untuk setiap kategori. Misalnya, jika Anda menetapkan setelan blokir ke Block few untuk kategori Hate speech, semua konten yang memiliki probabilitas tinggi sebagai konten ujaran kebencian akan diblokir. Namun, konten dengan probabilitas yang lebih rendah akan diizinkan.
| Batas (Google AI Studio) | Batas (API) | Deskripsi |
|---|---|---|
| Nonaktif | OFF |
Menonaktifkan filter keamanan |
| Block none | BLOCK_NONE |
Selalu tampilkan, terlepas dari probabilitas konten yang tidak aman |
| Block few | BLOCK_ONLY_HIGH |
Blokir jika probabilitas konten yang tidak aman tinggi |
| Block some | BLOCK_MEDIUM_AND_ABOVE |
Blokir jika probabilitas konten yang tidak aman sedang atau tinggi |
| Block most | BLOCK_LOW_AND_ABOVE |
Blokir jika probabilitas konten yang tidak aman rendah, sedang, atau tinggi |
| T/A | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
Batas tidak ditentukan, blokir menggunakan batas default |
Jika batas tidak ditetapkan, batas blokir default adalah Nonaktif untuk model Gemini 2.5 dan 3.
Anda dapat menetapkan setelan ini untuk setiap permintaan yang Anda buat ke layanan generatif.
Lihat referensi API HarmBlockThreshold
untuk mengetahui detailnya.
Masukan keamanan
generateContent
menampilkan
GenerateContentResponse yang
menyertakan masukan keamanan.
Masukan perintah disertakan dalam
promptFeedback. Jika promptFeedback.blockReason ditetapkan, konten perintah akan diblokir.
Masukan kandidat respons disertakan dalam
Candidate.finishReason dan
Candidate.safetyRatings. Jika konten respons diblokir dan finishReason adalah SAFETY, Anda dapat memeriksa safetyRatings untuk mengetahui detail selengkapnya. Konten yang diblokir tidak akan ditampilkan.
Menyesuaikan setelan keamanan
Bagian ini membahas cara menyesuaikan setelan keamanan di Google AI Studio dan dalam kode Anda.
Google AI Studio
Anda dapat menyesuaikan setelan keamanan di Google AI Studio.
Klik Safety settings di bagian Advanced settings di panel Run settings untuk membuka modal Run safety settings. Dalam modal, Anda dapat menggunakan penggeser untuk menyesuaikan tingkat pemfilteran konten per kategori keamanan:
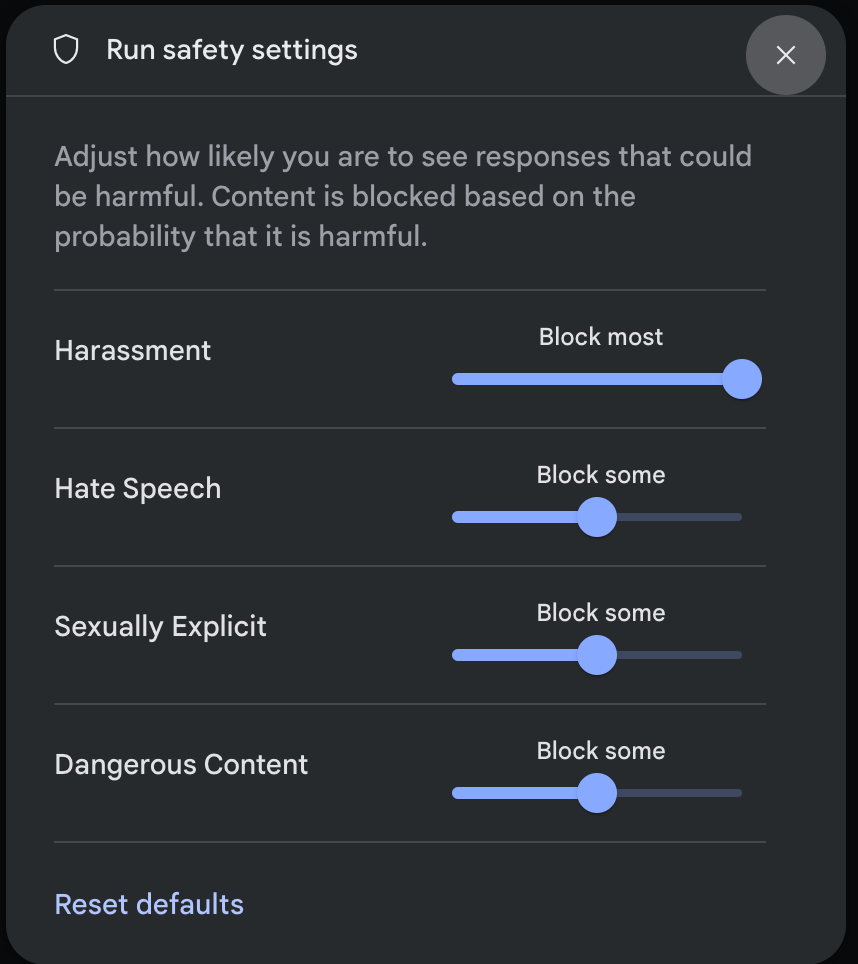
Saat Anda mengirim permintaan (misalnya, dengan mengajukan pertanyaan kepada model), pesan Content blocked akan muncul jika konten permintaan diblokir. Untuk melihat detail selengkapnya, tahan kursor di teks Content blocked untuk melihat kategori dan probabilitas klasifikasi bahaya.
Contoh kode
Cuplikan kode berikut menunjukkan cara menetapkan setelan keamanan dalam panggilan GenerateContent. Tindakan ini menetapkan batas untuk kategori ujaran kebencian (HARM_CATEGORY_HATE_SPEECH). Menetapkan kategori ini ke BLOCK_LOW_AND_ABOVE akan memblokir konten apa pun yang memiliki probabilitas rendah atau lebih tinggi sebagai ujaran kebencian. Untuk memahami setelan batas, lihat Pemfilteran keamanan
per permintaan.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
Langkah berikutnya
- Lihat referensi API untuk mempelajari API lengkap lebih lanjut.
- Tinjau panduan keamanan untuk melihat pertimbangan keamanan secara umum saat mengembangkan dengan LLM.
- Pelajari lebih lanjut cara menilai probabilitas versus tingkat keparahan dari tim Jigsaw
- Pelajari lebih lanjut produk yang berkontribusi pada solusi keamanan seperti Perspective API. * Anda dapat menggunakan setelan keamanan ini untuk membuat pengklasifikasi toksisitas. Lihat contoh klasifikasi untuk memulai.