
استفاده از واحدهای پردازش گرافیکی (GPU) برای اجرای مدلهای یادگیری ماشینی (ML) میتواند عملکرد مدل شما و تجربه کاربری برنامههای دارای ML را به طور چشمگیری بهبود بخشد. در دستگاههای iOS، میتوانید استفاده از مدلهای خود را با سرعت GPU با استفاده از یک نماینده فعال کنید. نمایندگان به عنوان درایورهای سخت افزاری LiteRT عمل می کنند و به شما امکان می دهند کد مدل خود را روی پردازنده های گرافیکی اجرا کنید.
این صفحه نحوه فعال کردن شتاب GPU را برای مدلهای LiteRT در برنامههای iOS شرح میدهد. برای اطلاعات بیشتر در مورد استفاده از نماینده GPU برای LiteRT، از جمله بهترین شیوهها و تکنیکهای پیشرفته، به صفحه نمایندگان GPU مراجعه کنید.
از GPU با Interpreter API استفاده کنید
LiteRT Interpreter API مجموعهای از APIهای عمومی را برای ساخت برنامههای یادگیری ماشین ارائه میکند. دستورالعمل های زیر شما را از طریق افزودن پشتیبانی GPU به یک برنامه iOS راهنمایی می کند. این راهنما فرض می کند که شما قبلاً یک برنامه iOS دارید که می تواند یک مدل ML را با LiteRT با موفقیت اجرا کند.
فایل Podfile را طوری تغییر دهید که پشتیبانی از GPU را شامل شود
با شروع نسخه LiteRT 2.3.0، نماینده GPU از پاد حذف می شود تا اندازه باینری کاهش یابد. می توانید آنها را با تعیین یک زیرمجموعه برای غلاف TensorFlowLiteSwift وارد کنید:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
یا
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
همچنین اگر میخواهید از Objective-C که برای نسخههای 2.4.0 و بالاتر در دسترس است یا C API استفاده کنید، میتوانید از TensorFlowLiteObjC یا TensorFlowLiteC استفاده کنید.
راه اندازی و استفاده از نماینده GPU
شما می توانید از نماینده GPU با LiteRT Interpreter API با تعدادی از زبان های برنامه نویسی استفاده کنید. Swift و Objective-C توصیه می شوند، اما می توانید از C++ و C نیز استفاده کنید. اگر از نسخه LiteRT زودتر از 2.4 استفاده می کنید، استفاده از C ضروری است. مثالهای کد زیر نحوه استفاده از نماینده را با هر یک از این زبانها شرح میدهند.
سویفت
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
هدف-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (قبل از 2.4.0)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
یادداشت های استفاده از زبان GPU API
- نسخه های LiteRT قبل از 2.4.0 فقط می توانند از C API برای Objective-C استفاده کنند.
- C++ API فقط زمانی در دسترس است که از bazel استفاده میکنید یا خودتان TensorFlow Lite را میسازید. C++ API را نمی توان با CocoaPods استفاده کرد.
- هنگام استفاده از LiteRT با نماینده GPU با C++، نماینده GPU را از طریق تابع
TFLGpuDelegateCreate()دریافت کنید و سپس آن را بهInterpreter::ModifyGraphWithDelegate()ارسال کنید، به جای فراخوانیInterpreter::AllocateTensors().
ساخت و تست با حالت انتشار
برای دستیابی به عملکرد بهتر و برای آزمایش نهایی، به یک نسخه نسخه با تنظیمات شتاب دهنده مناسب Metal API تغییر دهید. این بخش نحوه فعال کردن ساخت نسخه و پیکربندی تنظیمات Metal Acceleration را توضیح میدهد.
برای تغییر به نسخه انتشار:
- با انتخاب Product > Scheme > Edit Scheme... و سپس انتخاب Run ، تنظیمات ساخت را ویرایش کنید.
- در تب اطلاعات ، Build Configuration را به Release تغییر دهید و تیک Debug executable را بردارید.
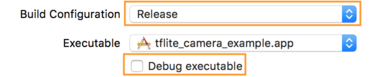
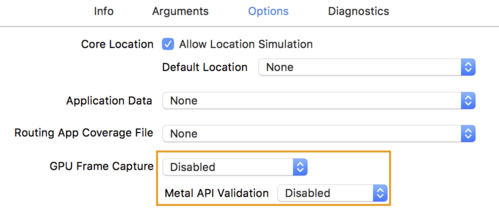
- روی تب Options کلیک کنید و GPU Frame Capture را به Disabled و Metal API Validation را به Disabled تغییر دهید.
- مطمئن شوید که ساختهای Release-Only بر اساس معماری 64 بیتی را انتخاب کنید. در Project Navigator > tflite_camera_example > PROJECT > your_project_name > Build Settings را تنظیم کنید Build Active Architecture Only > Release را روی Yes قرار دهید.

پشتیبانی از GPU پیشرفته
این بخش کاربردهای پیشرفته نماینده GPU برای iOS، از جمله گزینههای نمایندگی، بافرهای ورودی و خروجی و استفاده از مدلهای کوانتیزه را پوشش میدهد.
Delegate Options برای iOS
سازنده برای نماینده GPU struct از گزینهها را در Swift API ، Objective-C API ، و C API میپذیرد. ارسال nullptr (C API) یا هیچ (Objective-C و API Swift) به مقداردهی اولیه، گزینه های پیش فرض را تنظیم می کند (که در مثال استفاده پایه در بالا توضیح داده شده است).
سویفت
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
هدف-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
سی
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
بافرهای ورودی/خروجی با استفاده از C++ API
محاسبات روی GPU مستلزم آن است که داده ها در دسترس GPU باشد. این نیاز اغلب به این معنی است که باید یک کپی حافظه انجام دهید. در صورت امکان باید از عبور داده های خود از مرز حافظه CPU/GPU اجتناب کنید، زیرا این کار زمان زیادی را می گیرد. معمولاً چنین عبوری اجتناب ناپذیر است، اما در برخی موارد خاص می توان از یکی یا دیگری صرف نظر کرد.
اگر ورودی شبکه تصویری باشد که قبلاً در حافظه GPU بارگذاری شده است (به عنوان مثال، یک بافت GPU حاوی تغذیه دوربین) می تواند بدون اینکه هرگز وارد حافظه CPU شود در حافظه GPU باقی بماند. به طور مشابه، اگر خروجی شبکه به شکل یک تصویر قابل رندر باشد، مانند عملیات انتقال سبک تصویر ، می توانید نتیجه را مستقیماً روی صفحه نمایش دهید.
برای دستیابی به بهترین عملکرد، LiteRT این امکان را برای کاربران فراهم میکند که مستقیماً از بافر سختافزاری TensorFlow بخوانند و روی آن بنویسند و نسخههای حافظه قابل اجتناب را دور بزنند.
با فرض اینکه ورودی تصویر در حافظه GPU است، ابتدا باید آن را به یک شی MTLBuffer برای Metal تبدیل کنید. می توانید یک TfLiteTensor به یک MTLBuffer آماده شده توسط کاربر با تابع TFLGpuDelegateBindMetalBufferToTensor() مرتبط کنید. توجه داشته باشید که این تابع باید بعد از Interpreter::ModifyGraphWithDelegate() فراخوانی شود. علاوه بر این، خروجی استنتاج به طور پیش فرض از حافظه GPU به حافظه CPU کپی می شود. می توانید این رفتار را با فراخوانی Interpreter::SetAllowBufferHandleOutput(true) در حین مقداردهی اولیه خاموش کنید.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
هنگامی که رفتار پیشفرض خاموش شد، کپی کردن خروجی استنتاج از حافظه GPU به حافظه CPU نیاز به فراخوانی صریح به Interpreter::EnsureTensorDataIsReadable() . این رویکرد برای مدلهای کوانتیزهشده نیز کار میکند، اما همچنان باید از یک بافر با اندازه float32 با دادههای float32 استفاده کنید، زیرا بافر به بافر کوانتیزه داخلی محدود شده است.
مدل های کوانتیزه شده
کتابخانههای نمایندگی پردازندههای گرافیکی iOS بهطور پیشفرض از مدلهای کوانتیزهشده پشتیبانی میکنند . برای استفاده از مدل های کوانتیزه شده با نماینده GPU نیازی به تغییر کد ندارید. بخش زیر نحوه غیرفعال کردن پشتیبانی کوانتیزه را برای اهداف آزمایشی یا آزمایشی توضیح می دهد.
پشتیبانی از مدل کوانتیزه را غیرفعال کنید
کد زیر نحوه غیرفعال کردن پشتیبانی از مدل های کوانتیزه را نشان می دهد.
سویفت
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
هدف-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
سی
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
برای اطلاعات بیشتر در مورد اجرای مدل های کوانتیزه شده با شتاب GPU، به نمای کلی نماینده GPU مراجعه کنید.