
এজ ডিভাইসগুলিতে প্রায়শই সীমিত মেমোরি বা গণনা ক্ষমতা থাকে। মডেলগুলিতে বিভিন্ন অপ্টিমাইজেশন প্রয়োগ করা যেতে পারে যাতে সেগুলি এই সীমাবদ্ধতার মধ্যে চালানো যায়। এছাড়াও, কিছু অপ্টিমাইজেশন ত্বরিত অনুমানের জন্য বিশেষায়িত হার্ডওয়্যার ব্যবহারের অনুমতি দেয়।
LiterRT এবং TensorFlow মডেল অপ্টিমাইজেশন টুলকিট অনুমান অপ্টিমাইজ করার জটিলতা কমানোর জন্য সরঞ্জাম সরবরাহ করে।
আপনার অ্যাপ্লিকেশন ডেভেলপমেন্ট প্রক্রিয়ার সময় মডেল অপ্টিমাইজেশন বিবেচনা করার পরামর্শ দেওয়া হচ্ছে। এই নথিতে এজ হার্ডওয়্যারে স্থাপনের জন্য টেনসরফ্লো মডেলগুলি অপ্টিমাইজ করার জন্য কিছু সেরা অনুশীলনের রূপরেখা দেওয়া হয়েছে।
কেন মডেলগুলি অপ্টিমাইজ করা উচিত
অ্যাপ্লিকেশন ডেভেলপমেন্টে মডেল অপ্টিমাইজেশন সাহায্য করার বেশ কয়েকটি প্রধান উপায় রয়েছে।
আকার হ্রাস
একটি মডেলের আকার কমাতে কিছু ধরণের অপ্টিমাইজেশন ব্যবহার করা যেতে পারে। ছোট মডেলের নিম্নলিখিত সুবিধা রয়েছে:
- ছোট স্টোরেজ সাইজ: ছোট মডেলগুলি আপনার ব্যবহারকারীর ডিভাইসে কম স্টোরেজ স্পেস দখল করে। উদাহরণস্বরূপ, একটি ছোট মডেল ব্যবহার করে একটি অ্যান্ড্রয়েড অ্যাপ ব্যবহারকারীর মোবাইল ডিভাইসে কম স্টোরেজ স্পেস দখল করবে।
- ছোট ডাউনলোডের আকার: ছোট মডেলগুলি ব্যবহারকারীদের ডিভাইসে ডাউনলোড করতে কম সময় এবং ব্যান্ডউইথের প্রয়োজন হয়।
- কম মেমোরি ব্যবহার: ছোট মডেলগুলি চালানোর সময় কম RAM ব্যবহার করে, যা আপনার অ্যাপ্লিকেশনের অন্যান্য অংশ ব্যবহারের জন্য মেমোরি মুক্ত করে এবং আরও ভাল কর্মক্ষমতা এবং স্থিতিশীলতা অর্জন করতে পারে।
এই সমস্ত ক্ষেত্রেই কোয়ান্টাইজেশন একটি মডেলের আকার কমাতে পারে, সম্ভবত কিছুটা নির্ভুলতার বিনিময়ে। ছাঁটাই এবং ক্লাস্টারিং একটি মডেলকে আরও সহজে সংকোচনযোগ্য করে ডাউনলোডের জন্য আকার কমাতে পারে।
বিলম্ব হ্রাস
একটি নির্দিষ্ট মডেলের সাথে একটি একক অনুমান চালানোর জন্য যে পরিমাণ সময় লাগে তা হল লেটেন্সি । কিছু ধরণের অপ্টিমাইজেশন একটি মডেল ব্যবহার করে অনুমান চালানোর জন্য প্রয়োজনীয় গণনার পরিমাণ কমাতে পারে, যার ফলে লেটেন্সি কম হয়। লেটেন্সি বিদ্যুৎ খরচের উপরও প্রভাব ফেলতে পারে।
বর্তমানে, অনুমানের সময় ঘটে যাওয়া গণনাগুলিকে সরলীকরণ করে বিলম্ব কমাতে কোয়ান্টাইজেশন ব্যবহার করা যেতে পারে, সম্ভবত কিছু নির্ভুলতার ব্যয়ে।
অ্যাক্সিলারেটরের সামঞ্জস্য
কিছু হার্ডওয়্যার অ্যাক্সিলারেটর, যেমন এজ টিপিইউ , সঠিকভাবে অপ্টিমাইজ করা মডেলগুলির সাথে অত্যন্ত দ্রুত অনুমান চালাতে পারে।
সাধারণত, এই ধরণের ডিভাইসগুলির জন্য মডেলগুলিকে একটি নির্দিষ্ট উপায়ে কোয়ান্টাইজ করতে হয়। প্রতিটি হার্ডওয়্যার অ্যাক্সিলারেটরের প্রয়োজনীয়তা সম্পর্কে আরও জানতে তাদের ডকুমেন্টেশন দেখুন।
বিনিময়
অপ্টিমাইজেশনের ফলে মডেলের নির্ভুলতার পরিবর্তন হতে পারে, যা অ্যাপ্লিকেশন ডেভেলপমেন্ট প্রক্রিয়ার সময় বিবেচনা করা আবশ্যক।
নির্ভুলতার পরিবর্তনগুলি পৃথক মডেলটি অপ্টিমাইজ করা হচ্ছে তার উপর নির্ভর করে এবং আগে থেকে ভবিষ্যদ্বাণী করা কঠিন। সাধারণত, আকার বা বিলম্বের জন্য অপ্টিমাইজ করা মডেলগুলি অল্প পরিমাণে নির্ভুলতা হারাবে। আপনার প্রয়োগের উপর নির্ভর করে, এটি আপনার ব্যবহারকারীর অভিজ্ঞতাকে প্রভাবিত করতে পারে বা নাও করতে পারে। বিরল ক্ষেত্রে, অপ্টিমাইজেশন প্রক্রিয়ার ফলে কিছু মডেল কিছুটা নির্ভুলতা অর্জন করতে পারে।
অপ্টিমাইজেশনের প্রকারভেদ
LiterRT বর্তমানে কোয়ান্টাইজেশন, প্রুনিং এবং ক্লাস্টারিংয়ের মাধ্যমে অপ্টিমাইজেশন সমর্থন করে।
এগুলো টেনসরফ্লো মডেল অপ্টিমাইজেশন টুলকিটের অংশ, যা টেনসরফ্লো লাইটের সাথে সামঞ্জস্যপূর্ণ মডেল অপ্টিমাইজেশন কৌশলগুলির জন্য সংস্থান সরবরাহ করে।
পরিমাণ নির্ধারণ
কোয়ান্টাইজেশন একটি মডেলের প্যারামিটার উপস্থাপন করতে ব্যবহৃত সংখ্যার নির্ভুলতা হ্রাস করে কাজ করে, যা ডিফল্টরূপে 32-বিট ফ্লোটিং পয়েন্ট সংখ্যা। এর ফলে মডেলের আকার ছোট হয় এবং গণনা দ্রুত হয়।
LiterRT-তে নিম্নলিখিত ধরণের কোয়ান্টাইজেশন পাওয়া যায়:
| কৌশল | ডেটার প্রয়োজনীয়তা | আকার হ্রাস | সঠিকতা | সমর্থিত হার্ডওয়্যার |
|---|---|---|---|---|
| প্রশিক্ষণ-পরবর্তী ভাসমান ১৬ কোয়ান্টাইজেশন | কোন তথ্য নেই | ৫০% পর্যন্ত | নির্ভুলতার অভাব | সিপিইউ, জিপিইউ |
| প্রশিক্ষণ-পরবর্তী গতিশীল পরিসরের পরিমাণ নির্ধারণ | কোন তথ্য নেই | ৭৫% পর্যন্ত | সবচেয়ে কম নির্ভুলতা ক্ষতি | সিপিইউ, জিপিইউ (অ্যান্ড্রয়েড) |
| প্রশিক্ষণ-পরবর্তী পূর্ণসংখ্যার পরিমাণ নির্ধারণ | লেবেলবিহীন প্রতিনিধি নমুনা | ৭৫% পর্যন্ত | ছোট নির্ভুলতা ক্ষতি | সিপিইউ, জিপিইউ (অ্যান্ড্রয়েড), এজটিপিইউ |
| পরিমাণ নির্ধারণ-সচেতন প্রশিক্ষণ | লেবেলযুক্ত প্রশিক্ষণ তথ্য | ৭৫% পর্যন্ত | সবচেয়ে কম নির্ভুলতা ক্ষতি | সিপিইউ, জিপিইউ (অ্যান্ড্রয়েড), এজটিপিইউ |
নিম্নলিখিত ডিসিশন ট্রি আপনাকে আপনার মডেলের জন্য যে কোয়ান্টাইজেশন স্কিমগুলি ব্যবহার করতে চান তা নির্বাচন করতে সাহায্য করবে, কেবল প্রত্যাশিত মডেলের আকার এবং নির্ভুলতার উপর ভিত্তি করে।
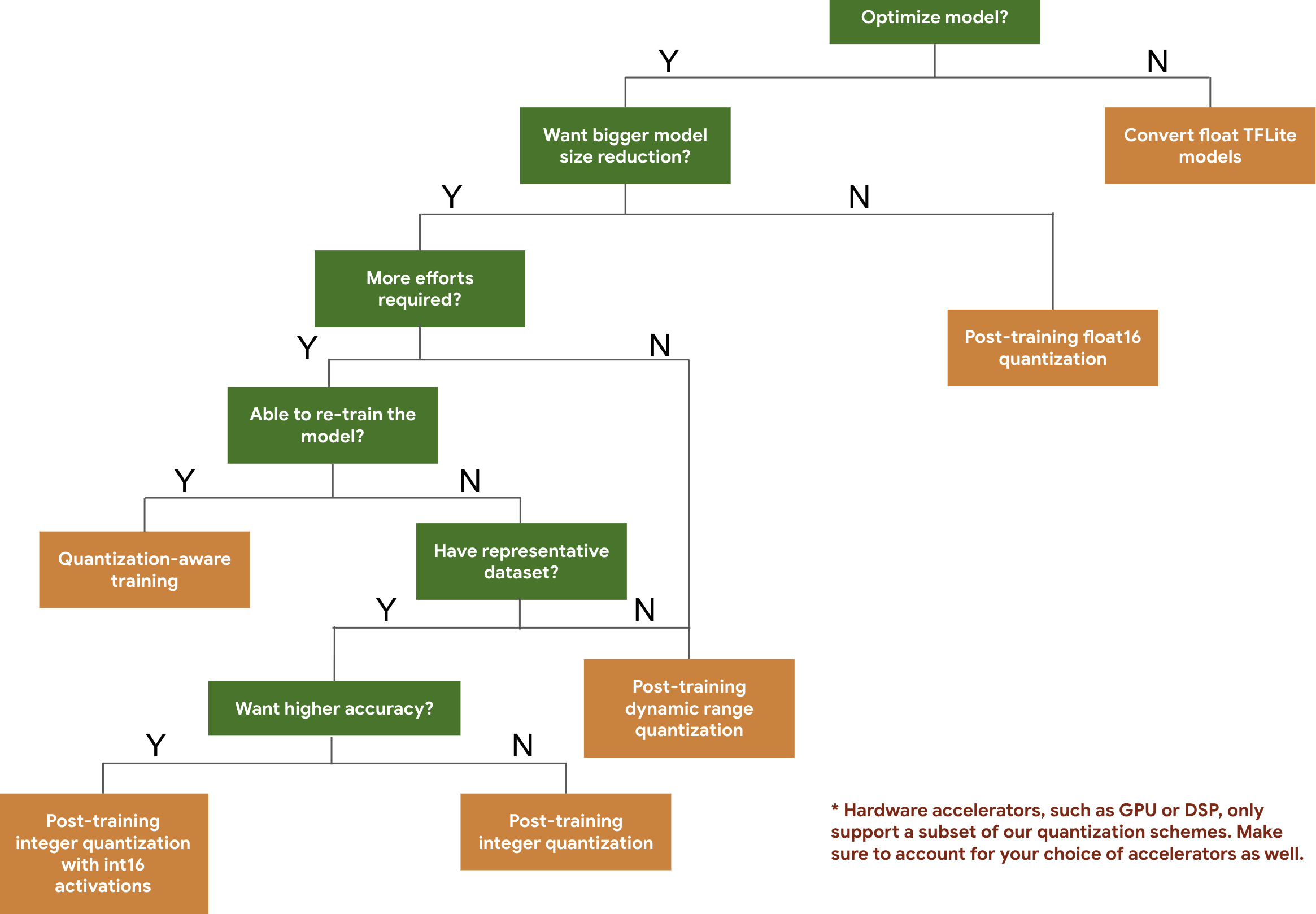
কয়েকটি মডেলের প্রশিক্ষণ-পরবর্তী কোয়ান্টাইজেশন এবং কোয়ান্টাইজেশন-সচেতন প্রশিক্ষণের জন্য লেটেন্সি এবং নির্ভুলতার ফলাফল নীচে দেওয়া হল। Pixel 2 ডিভাইসে একটি বড় কোর CPU ব্যবহার করে সমস্ত লেটেন্সি সংখ্যা পরিমাপ করা হয়। টুলকিটের উন্নতির সাথে সাথে, এখানে সংখ্যাগুলিও উন্নত হবে:
| মডেল | শীর্ষ-১ নির্ভুলতা (মূল) | শীর্ষ-১ নির্ভুলতা (প্রশিক্ষণ পরবর্তী পরিমাণগত) | শীর্ষ-১ নির্ভুলতা (পরিমাণ সচেতন প্রশিক্ষণ) | বিলম্ব (মূল) (মিলিসেকেন্ড) | লেটেন্সি (প্রশিক্ষণ পরবর্তী পরিমাণগত) (ms) | বিলম্ব (পরিমাণ সচেতন প্রশিক্ষণ) (ms) | আকার (মূল) (এমবি) | আকার (অপ্টিমাইজড) (এমবি) |
|---|---|---|---|---|---|---|---|---|
| মোবাইলনেট-v1-1-224 | ০.৭০৯ | ০.৬৫৭ | ০.৭০ | ১২৪ | ১১২ | ৬৪ | ১৬.৯ | ৪.৩ |
| মোবাইলনেট-v2-1-224 | ০.৭১৯ | ০.৬৩৭ | ০.৭০৯ | ৮৯ | ৯৮ | ৫৪ | ১৪ | ৩.৬ |
| ইনসেপশন_ভি৩ | ০.৭৮ | ০.৭৭২ | ০.৭৭৫ | ১১৩০ | ৮৪৫ | ৫৪৩ | ৯৫.৭ | ২৩.৯ |
| রেসনেট_ভি২_১০১ | ০.৭৭০ | ০.৭৬৮ | নিষিদ্ধ | ৩৯৭৩ | ২৮৬৮ | নিষিদ্ধ | ১৭৮.৩ | ৪৪.৯ |
int16 অ্যাক্টিভেশন এবং int8 ওজন সহ সম্পূর্ণ পূর্ণসংখ্যা কোয়ান্টাইজেশন
int16 অ্যাক্টিভেশন সহ কোয়ান্টাইজেশন হল একটি পূর্ণ পূর্ণসংখ্যা কোয়ান্টাইজেশন স্কিম যেখানে int16 তে অ্যাক্টিভেশন এবং int8 তে ওয়েট থাকে। এই মোডটি কোয়ান্টাইজড মডেলের নির্ভুলতা উন্নত করতে পারে, যেখানে int8 তে অ্যাক্টিভেশন এবং ওয়েট উভয়ই একই মডেলের আকার রাখে। যখন অ্যাক্টিভেশনগুলি কোয়ান্টাইজেশনের প্রতি সংবেদনশীল হয় তখন এটি সুপারিশ করা হয়।
দ্রষ্টব্য: বর্তমানে এই কোয়ান্টাইজেশন স্কিমের জন্য TFLite-এ শুধুমাত্র অ-অপ্টিমাইজড রেফারেন্স কার্নেল বাস্তবায়ন উপলব্ধ, তাই ডিফল্টরূপে int8 কার্নেলের তুলনায় কর্মক্ষমতা ধীর হবে। এই মোডের সম্পূর্ণ সুবিধা বর্তমানে বিশেষায়িত হার্ডওয়্যার বা কাস্টম সফ্টওয়্যারের মাধ্যমে অ্যাক্সেস করা যেতে পারে।
এই মোড থেকে উপকৃত কিছু মডেলের নির্ভুলতার ফলাফল নীচে দেওয়া হল। মডেল নির্ভুলতা মেট্রিকের ধরণ নির্ভুলতা (float32 সক্রিয়করণ) নির্ভুলতা (int8 অ্যাক্টিভেশন) নির্ভুলতা (int16 অ্যাক্টিভেশন) Wav2letter সম্পর্কে WER সম্পর্কে ৬.৭% ৭.৭% ৭.২% ডিপস্পিচ ০.৫.১ (আনরোল করা হয়নি) সিইআর ৬.১৩% ৪৩.৬৭% ৬.৫২% YoloV3 সম্পর্কে mAP(IOU=0.5) ০.৫৭৭ ০.৫৬৩ ০.৫৭৪ মোবাইলনেটভি১ শীর্ষ-১ নির্ভুলতা ০.৭০৬২ ০.৬৯৪ ০.৬৯৩৬ মোবাইলনেটভি২ শীর্ষ-১ নির্ভুলতা ০.৭১৮ ০.৭১২৬ ০.৭১৩৭ মোবাইলবার্ট F1 (হুবহু মিল) ৮৮.৮১(৮১.২৩) ২.০৮(০) ৮৮.৭৩(৮১.১৫)
ছাঁটাই
ছাঁটাই একটি মডেলের মধ্যে এমন প্যারামিটারগুলি সরিয়ে দিয়ে কাজ করে যা এর পূর্বাভাসের উপর সামান্য প্রভাব ফেলে। ছাঁটাই করা মডেলগুলি ডিস্কে একই আকারের হয় এবং একই রানটাইম ল্যাটেন্সি থাকে, তবে আরও কার্যকরভাবে সংকুচিত করা যায়। এটি ছাঁটাইকে মডেল ডাউনলোডের আকার হ্রাস করার জন্য একটি কার্যকর কৌশল করে তোলে।
ভবিষ্যতে, LiterRT ছাঁটাই করা মডেলগুলির জন্য ল্যাটেন্সি হ্রাস প্রদান করবে।
ক্লাস্টারিং
ক্লাস্টারিং একটি মডেলের প্রতিটি স্তরের ওজনকে পূর্বনির্ধারিত সংখ্যক ক্লাস্টারে ভাগ করে কাজ করে, তারপর প্রতিটি ক্লাস্টারের ওজনের জন্য সেন্ট্রয়েড মান ভাগ করে নেয়। এটি একটি মডেলে অনন্য ওজন মানের সংখ্যা হ্রাস করে, ফলে এর জটিলতা হ্রাস পায়।
ফলস্বরূপ, ক্লাস্টারড মডেলগুলিকে আরও কার্যকরভাবে সংকুচিত করা যেতে পারে, যা ছাঁটাইয়ের মতো স্থাপনার সুবিধা প্রদান করে।
উন্নয়ন কর্মপ্রবাহ
শুরু করার জন্য, হোস্ট করা মডেলগুলির মডেলগুলি আপনার অ্যাপ্লিকেশনের জন্য কাজ করতে পারে কিনা তা পরীক্ষা করুন। যদি না হয়, তাহলে আমরা ব্যবহারকারীদের প্রশিক্ষণ-পরবর্তী কোয়ান্টাইজেশন টুল দিয়ে শুরু করার পরামর্শ দিচ্ছি কারণ এটি ব্যাপকভাবে প্রযোজ্য এবং প্রশিক্ষণের ডেটার প্রয়োজন হয় না।
যেসব ক্ষেত্রে নির্ভুলতা এবং ল্যাটেন্সি লক্ষ্যমাত্রা পূরণ করা হয় না, অথবা হার্ডওয়্যার অ্যাক্সিলারেটর সমর্থন গুরুত্বপূর্ণ, সেখানে কোয়ান্টাইজেশন-সচেতন প্রশিক্ষণই ভালো বিকল্প। TensorFlow মডেল অপ্টিমাইজেশন টুলকিটের অধীনে অতিরিক্ত অপ্টিমাইজেশন কৌশলগুলি দেখুন।
আপনি যদি আপনার মডেলের আকার আরও কমাতে চান, তাহলে আপনার মডেলগুলির পরিমাণ নির্ধারণের আগে ছাঁটাই এবং/অথবা ক্লাস্টারিং করার চেষ্টা করতে পারেন।