
Các thiết bị biên thường có bộ nhớ hoặc sức mạnh tính toán hạn chế. Bạn có thể áp dụng nhiều phương pháp tối ưu hoá cho các mô hình để có thể chạy trong những ràng buộc này. Ngoài ra, một số quy trình tối ưu hoá cho phép sử dụng phần cứng chuyên dụng để suy luận nhanh hơn.
LiteRT và Bộ công cụ tối ưu hoá mô hình TensorFlow cung cấp các công cụ để giảm thiểu độ phức tạp của việc tối ưu hoá suy luận.
Bạn nên cân nhắc việc tối ưu hoá mô hình trong quá trình phát triển ứng dụng. Tài liệu này trình bày một số phương pháp hay nhất để tối ưu hoá các mô hình TensorFlow nhằm triển khai cho phần cứng biên.
Lý do bạn nên tối ưu hoá các mô hình
Có một số cách chính để tối ưu hoá mô hình có thể giúp phát triển ứng dụng.
Giảm kích thước
Bạn có thể sử dụng một số hình thức tối ưu hoá để giảm kích thước của mô hình. Các mô hình nhỏ hơn có những lợi ích sau:
- Dung lượng lưu trữ nhỏ hơn: Các mô hình nhỏ hơn chiếm ít dung lượng lưu trữ hơn trên thiết bị của người dùng. Ví dụ: một ứng dụng Android sử dụng mô hình nhỏ hơn sẽ chiếm ít dung lượng lưu trữ hơn trên thiết bị di động của người dùng.
- Kích thước tải xuống nhỏ hơn: Các mô hình nhỏ hơn cần ít thời gian và băng thông hơn để tải xuống thiết bị của người dùng.
- Ít sử dụng bộ nhớ hơn: Các mô hình nhỏ hơn sử dụng ít RAM hơn khi chạy, giúp giải phóng bộ nhớ cho các phần khác của ứng dụng sử dụng và có thể mang lại hiệu suất cũng như độ ổn định cao hơn.
Lượng tử hoá có thể giảm kích thước của một mô hình trong tất cả các trường hợp này, có thể phải trả giá bằng độ chính xác. Việc cắt tỉa và phân cụm có thể giảm kích thước của một mô hình để tải xuống bằng cách giúp mô hình đó dễ nén hơn.
Giảm độ trễ
Độ trễ là khoảng thời gian cần thiết để chạy một quy trình suy luận duy nhất với một mô hình nhất định. Một số hình thức tối ưu hoá có thể giảm lượng tính toán cần thiết để chạy suy luận bằng mô hình, dẫn đến độ trễ thấp hơn. Độ trễ cũng có thể ảnh hưởng đến mức tiêu thụ điện.
Hiện tại, bạn có thể dùng phương pháp lượng tử hoá để giảm độ trễ bằng cách đơn giản hoá các phép tính xảy ra trong quá trình suy luận, có thể phải trả giá bằng độ chính xác.
Khả năng tương thích của bộ tăng tốc
Một số bộ tăng tốc phần cứng, chẳng hạn như Edge TPU, có thể chạy quy trình suy luận cực kỳ nhanh với các mô hình đã được tối ưu hoá đúng cách.
Nhìn chung, các loại thiết bị này yêu cầu các mô hình được lượng tử hoá theo một cách cụ thể. Hãy xem tài liệu của từng bộ tăng tốc phần cứng để tìm hiểu thêm về các yêu cầu của bộ tăng tốc đó.
Lựa chọn đánh đổi
Các hoạt động tối ưu hoá có thể dẫn đến những thay đổi về độ chính xác của mô hình. Bạn phải cân nhắc điều này trong quá trình phát triển ứng dụng.
Mức độ thay đổi về độ chính xác phụ thuộc vào từng mô hình được tối ưu hoá và rất khó dự đoán trước. Nhìn chung, những mô hình được tối ưu hoá về kích thước hoặc độ trễ sẽ giảm một chút độ chính xác. Tuỳ thuộc vào ứng dụng của bạn, việc này có thể ảnh hưởng hoặc không ảnh hưởng đến trải nghiệm của người dùng. Trong một số ít trường hợp, một số mô hình nhất định có thể đạt được độ chính xác cao hơn nhờ quá trình tối ưu hoá.
Các loại tối ưu hoá
LiteRT hiện hỗ trợ hoạt động tối ưu hoá thông qua việc lượng tử hoá, cắt tỉa và phân cụm.
Đây là một phần của Bộ công cụ tối ưu hoá mô hình TensorFlow, cung cấp các tài nguyên cho những kỹ thuật tối ưu hoá mô hình tương thích với TensorFlow Lite.
Lượng tử hoá
Lượng tử hoá hoạt động bằng cách giảm độ chính xác của các số được dùng để biểu thị các tham số của mô hình. Theo mặc định, các tham số này là số thực 32 bit. Điều này giúp giảm kích thước mô hình và tăng tốc độ tính toán.
LiteRT cung cấp các loại lượng tử hoá sau:
| Kỹ thuật | Yêu cầu dữ liệu | Giảm kích thước | Độ chính xác | Phần cứng được hỗ trợ |
|---|---|---|---|---|
| Lượng tử hoá float16 sau huấn luyện | Không có dữ liệu | Lên đến 50% | Mất độ chính xác không đáng kể | CPU, GPU |
| Lượng tử hoá dải tương phản động sau huấn luyện | Không có dữ liệu | Tối đa 75% | Mất độ chính xác ít nhất | CPU, GPU (Android) |
| Lượng tử hoá số nguyên sau huấn luyện | Mẫu đại diện không được gắn nhãn | Tối đa 75% | Mất độ chính xác không đáng kể | CPU, GPU (Android), EdgeTPU |
| Huấn luyện có tính đến việc lượng tử hoá | Dữ liệu huấn luyện được gắn nhãn | Tối đa 75% | Mất độ chính xác ít nhất | CPU, GPU (Android), EdgeTPU |
Cây quyết định sau đây giúp bạn chọn các lược đồ lượng tử hoá mà bạn có thể muốn sử dụng cho mô hình của mình, chỉ dựa trên kích thước và độ chính xác dự kiến của mô hình.
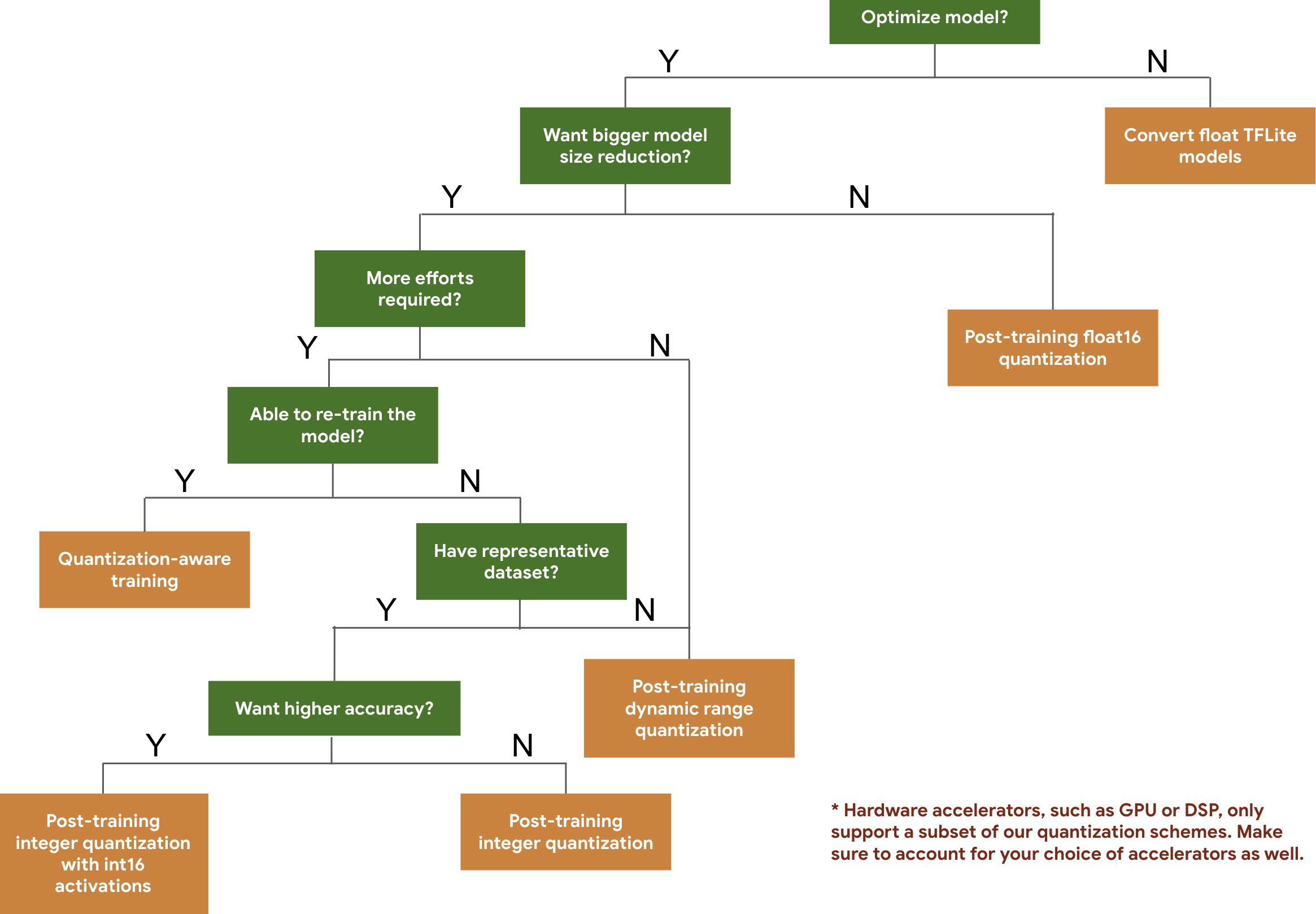
Dưới đây là kết quả về độ trễ và độ chính xác cho quá trình định lượng sau huấn luyện và huấn luyện có nhận biết định lượng trên một số mô hình. Tất cả các số liệu về độ trễ đều được đo trên thiết bị Pixel 2 bằng một CPU lõi lớn duy nhất. Khi bộ công cụ được cải thiện, các số liệu ở đây cũng sẽ được cải thiện:
| Mô hình | Độ chính xác Top-1 (Bản gốc) | Độ chính xác hàng đầu (Sau khi huấn luyện định lượng) | Độ chính xác hàng đầu (Huấn luyện nhận biết lượng tử hoá) | Độ trễ (Ban đầu) (mili giây) | Độ trễ (Định lượng sau huấn luyện) (mili giây) | Độ trễ (Huấn luyện nhận biết lượng tử hoá) (mili giây) | Kích thước (Bản gốc) (MB) | Kích thước (Đã tối ưu hoá) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0,709 | 0,657 | 0,70 | 124 | 112 | 64 | 16,9 | 4,3 |
| Mobilenet-v2-1-224 | 0,719 | 0,637 | 0,709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0,78 | 0,772 | 0,775 | 1130 | 845 | 543 | 95,7 | 23,9 |
| Resnet_v2_101 | 0,770 | 0,768 | Không áp dụng | 3973 | 2868 | Không áp dụng | 178,3 | 44,9 |
Lượng tử hoá số nguyên đầy đủ với các lượt kích hoạt int16 và trọng số int8
Lượng tử hoá bằng các lượt kích hoạt int16 là một lược đồ lượng tử hoá số nguyên đầy đủ với các lượt kích hoạt ở int16 và trọng số ở int8. Chế độ này có thể cải thiện độ chính xác của mô hình được lượng tử hoá so với lược đồ lượng tử hoá số nguyên đầy đủ với cả lượt kích hoạt và trọng số trong int8, đồng thời duy trì kích thước mô hình tương tự. Bạn nên dùng khi các lượt kích hoạt nhạy cảm với việc lượng tử hoá.
LƯU Ý: Hiện tại, chỉ có các triển khai hạt nhân tham chiếu không được tối ưu hoá trong TFLite cho lược đồ định lượng này, vì vậy theo mặc định, hiệu suất sẽ chậm hơn so với các hạt nhân int8. Bạn có thể khai thác toàn bộ lợi thế của chế độ này thông qua phần cứng chuyên dụng hoặc phần mềm tuỳ chỉnh.
Dưới đây là kết quả về độ chính xác của một số mô hình được hưởng lợi từ chế độ này.
| Mô hình | Loại chỉ số về độ chính xác | Độ chính xác (các lượt kích hoạt float32) | Độ chính xác (hoạt động int8) | Độ chính xác (hoạt động int16) |
|---|---|---|---|---|
| Wav2letter | WER | 6,7% | 7,7% | 7,2% |
| DeepSpeech 0.5.1 (chưa được triển khai) | CER | 6,13% | 43,67% | 6,52% |
| YoloV3 | mAP(IOU=0,5) | 0,577 | 0,563 | 0,574 |
| MobileNetV1 | Độ chính xác Top-1 | 0,7062 | 0,694 | 0,6936 |
| MobileNetV2 | Độ chính xác hàng đầu | 0,718 | 0,7126 | 0,7137 |
| MobileBert | F1(Khớp chính xác) | 88,81(81,23) | 2,08(0) | 88,73(81,15) |
Tỉa cành
Cắt tỉa hoạt động bằng cách xoá các tham số trong một mô hình chỉ có tác động nhỏ đến các dự đoán của mô hình đó. Các mô hình được cắt tỉa có cùng kích thước trên đĩa và có cùng độ trễ thời gian chạy, nhưng có thể được nén hiệu quả hơn. Điều này khiến việc cắt tỉa trở thành một kỹ thuật hữu ích để giảm kích thước tải xuống của mô hình.
Trong tương lai, LiteRT sẽ giảm độ trễ cho các mô hình được cắt tỉa.
Tạo cụm
Phân cụm hoạt động bằng cách nhóm trọng số của từng lớp trong một mô hình thành một số lượng cụm được xác định trước, sau đó chia sẻ các giá trị tâm cụm cho các trọng số thuộc về từng cụm riêng lẻ. Điều này làm giảm số lượng giá trị trọng số riêng biệt trong một mô hình, do đó làm giảm độ phức tạp của mô hình.
Do đó, các mô hình được phân cụm có thể được nén hiệu quả hơn, mang lại những lợi ích khi triển khai tương tự như việc cắt tỉa.
Quy trình phát triển
Để bắt đầu, hãy kiểm tra xem các mô hình trong mô hình được lưu trữ có thể hoạt động cho ứng dụng của bạn hay không. Nếu không, người dùng nên bắt đầu bằng công cụ định lượng sau huấn luyện vì công cụ này có thể áp dụng rộng rãi và không yêu cầu dữ liệu huấn luyện.
Đối với những trường hợp không đáp ứng được mục tiêu về độ chính xác và độ trễ hoặc khi cần có sự hỗ trợ của bộ tăng tốc phần cứng, thì huấn luyện có nhận thức về lượng tử hoá là lựa chọn phù hợp hơn. Xem thêm các kỹ thuật tối ưu hoá trong Bộ công cụ tối ưu hoá mô hình TensorFlow.
Nếu muốn giảm thêm kích thước mô hình, bạn có thể thử cắt tỉa và/hoặc phân cụm trước khi lượng tử hoá mô hình.