
دستگاههای لبهای اغلب حافظه یا قدرت محاسباتی محدودی دارند. بهینهسازیهای مختلفی را میتوان روی مدلها اعمال کرد تا بتوان آنها را در این محدودیتها اجرا کرد. علاوه بر این، برخی بهینهسازیها امکان استفاده از سختافزار تخصصی را برای استنتاج تسریعشده فراهم میکنند.
LiteRT و جعبه ابزار بهینهسازی مدل TensorFlow ابزارهایی را برای به حداقل رساندن پیچیدگی استنتاج بهینهسازی ارائه میدهند.
توصیه میشود که بهینهسازی مدل را در طول فرآیند توسعه برنامه خود در نظر بگیرید. این سند برخی از بهترین شیوهها را برای بهینهسازی مدلهای TensorFlow برای استقرار در سختافزار لبهای تشریح میکند.
چرا مدلها باید بهینه شوند؟
بهینهسازی مدل از چندین طریق اصلی میتواند به توسعه برنامه کمک کند.
کاهش اندازه
برخی از اشکال بهینهسازی را میتوان برای کاهش اندازه مدل استفاده کرد. مدلهای کوچکتر مزایای زیر را دارند:
- حجم ذخیرهسازی کمتر: مدلهای کوچکتر فضای ذخیرهسازی کمتری را در دستگاههای کاربران شما اشغال میکنند. به عنوان مثال، یک برنامه اندروید که از مدل کوچکتری استفاده میکند، فضای ذخیرهسازی کمتری را در دستگاه تلفن همراه کاربر اشغال خواهد کرد.
- حجم دانلود کمتر: مدلهای کوچکتر برای دانلود به دستگاههای کاربران به زمان و پهنای باند کمتری نیاز دارند.
- استفاده کمتر از حافظه: مدلهای کوچکتر هنگام اجرا از رم کمتری استفاده میکنند، که این امر باعث آزاد شدن حافظه برای استفاده سایر بخشهای برنامه شما میشود و میتواند به عملکرد و پایداری بهتر منجر شود.
کوانتیزاسیون میتواند در تمام این موارد، اندازه مدل را کاهش دهد، که احتمالاً به قیمت از دست رفتن مقداری از دقت تمام میشود. هرس کردن و خوشهبندی میتوانند با آسانتر کردن فشردهسازی مدل، اندازه آن را برای دانلود کاهش دهند.
کاهش تأخیر
تأخیر، مدت زمانی است که برای اجرای یک استنتاج واحد با یک مدل معین لازم است. برخی از اشکال بهینهسازی میتوانند میزان محاسبات مورد نیاز برای اجرای استنتاج با استفاده از یک مدل را کاهش دهند و در نتیجه تأخیر کمتری داشته باشند. تأخیر همچنین میتواند بر مصرف برق تأثیر بگذارد.
در حال حاضر، میتوان از کوانتیزاسیون برای کاهش تأخیر با سادهسازی محاسباتی که در طول استنتاج رخ میدهند، استفاده کرد، که احتمالاً به قیمت از دست رفتن مقداری از دقت تمام میشود.
سازگاری با شتابدهنده
برخی از شتابدهندههای سختافزاری، مانند Edge TPU ، میتوانند استنتاج را با مدلهایی که به درستی بهینهسازی شدهاند، بسیار سریع اجرا کنند.
بهطورکلی، این نوع دستگاهها نیاز دارند که مدلها به روش خاصی کوانتیزه شوند. برای کسب اطلاعات بیشتر در مورد الزامات هر شتابدهنده سختافزاری، به مستندات آن مراجعه کنید.
بدهبستانها
بهینهسازیها میتوانند به طور بالقوه منجر به تغییراتی در دقت مدل شوند که باید در طول فرآیند توسعه برنامه در نظر گرفته شوند.
تغییرات دقت به مدلی که بهینهسازی میشود بستگی دارد و پیشبینی آن از قبل دشوار است. بهطورکلی، مدلهایی که از نظر اندازه یا تأخیر بهینه شدهاند، مقدار کمی از دقت خود را از دست میدهند. بسته به کاربرد شما، این ممکن است بر تجربه کاربران شما تأثیر بگذارد یا نگذارد. در موارد نادر، مدلهای خاصی ممکن است در نتیجه فرآیند بهینهسازی، مقداری دقت به دست آورند.
انواع بهینهسازی
LiteRT در حال حاضر از بهینهسازی از طریق کوانتیزاسیون، هرس و خوشهبندی پشتیبانی میکند.
اینها بخشی از جعبه ابزار بهینهسازی مدل TensorFlow هستند که منابعی را برای تکنیکهای بهینهسازی مدل سازگار با TensorFlow Lite فراهم میکند.
کوانتیزاسیون
کوانتیزاسیون با کاهش دقت اعداد مورد استفاده برای نمایش پارامترهای یک مدل، که به طور پیشفرض اعداد اعشاری ۳۲ بیتی هستند، عمل میکند. این امر منجر به کاهش اندازه مدل و افزایش سرعت محاسبات میشود.
انواع کوانتیزاسیون زیر در LiteRT موجود است:
| تکنیک | الزامات داده | کاهش اندازه | دقت | سختافزار پشتیبانیشده |
|---|---|---|---|---|
| کوانتیزاسیون float16 پس از آموزش | بدون داده | تا ۵۰٪ | افت دقت ناچیز | پردازنده مرکزی، پردازنده گرافیکی |
| کوانتیزاسیون محدوده دینامیکی پس از آموزش | بدون داده | تا ۷۵٪ | کوچکترین افت دقت | پردازنده مرکزی، پردازنده گرافیکی (اندروید) |
| کوانتیزاسیون عدد صحیح پس از آموزش | نمونه نماینده بدون برچسب | تا ۷۵٪ | از دست دادن دقت کم | پردازنده مرکزی، پردازنده گرافیکی (اندروید)، EdgeTPU |
| آموزش آگاه از کوانتیزاسیون | دادههای آموزشی برچسبگذاری شده | تا ۷۵٪ | کوچکترین افت دقت | پردازنده مرکزی، پردازنده گرافیکی (اندروید)، EdgeTPU |
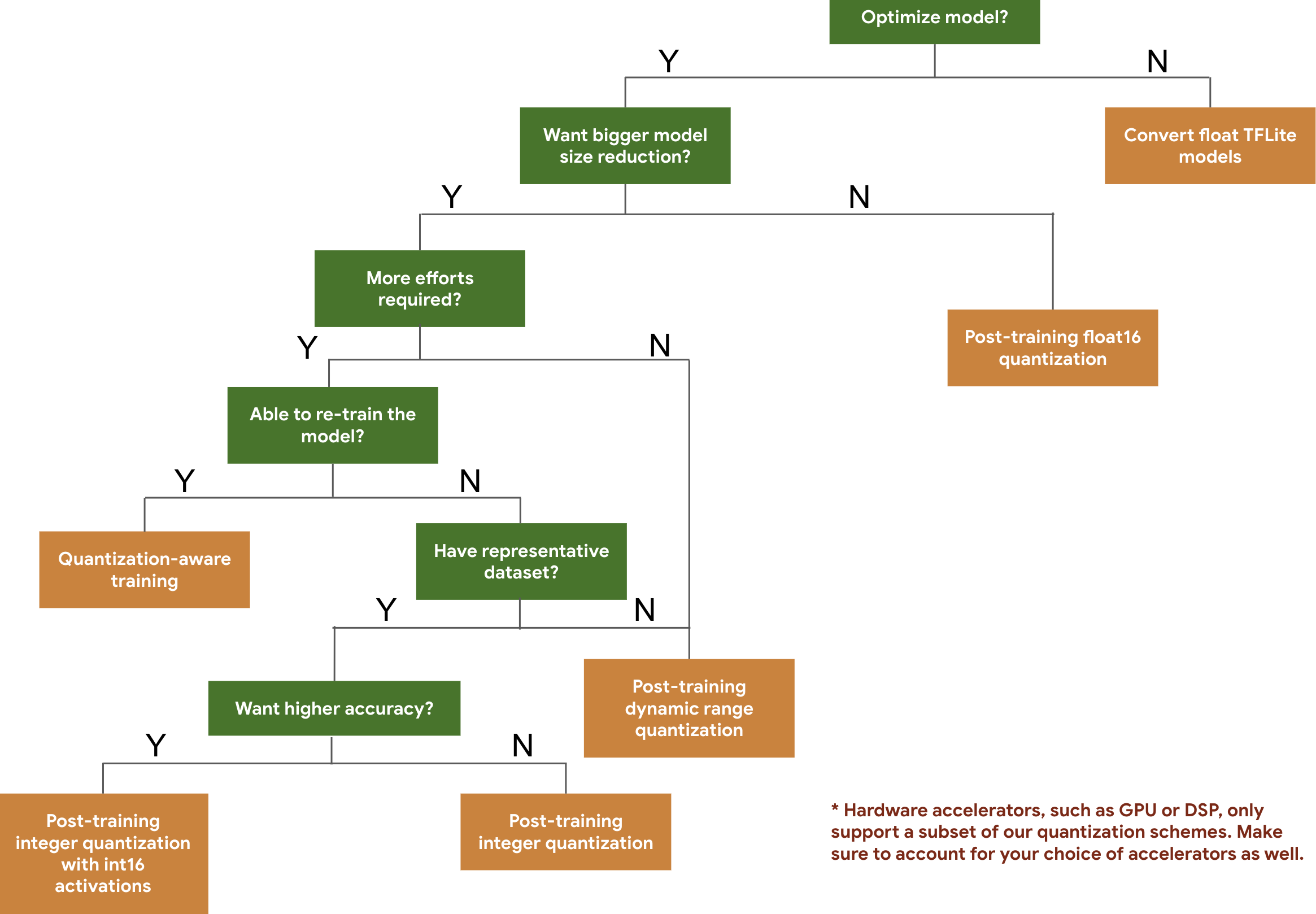
درخت تصمیم زیر به شما کمک میکند تا طرحهای کوانتیزاسیونی را که ممکن است بخواهید برای مدل خود استفاده کنید، صرفاً بر اساس اندازه و دقت مدل مورد انتظار، انتخاب کنید.
در زیر نتایج تأخیر و دقت برای کوانتیزاسیون پس از آموزش و آموزش آگاه از کوانتیزاسیون در چند مدل آمده است. تمام اعداد تأخیر در دستگاههای Pixel 2 با استفاده از یک پردازنده بزرگ هستهای اندازهگیری شدهاند. با بهبود ابزار، اعداد اینجا نیز بهبود خواهند یافت:
| مدل | دقت بالا (اصلی) | دقت بالا (کوانتیزه شده پس از آموزش) | دقت بالا (آموزش مبتنی بر کوانتیزاسیون) | تأخیر (اصلی) (میلیثانیه) | تأخیر (کوانتیزه شده پس از آموزش) (میلیثانیه) | تأخیر (آموزش مبتنی بر کوانتیزاسیون) (میلیثانیه) | حجم (اصلی) (مگابایت) | حجم (بهینهشده) (مگابایت) |
|---|---|---|---|---|---|---|---|---|
| موبایلنت-نسخه ۱-۱-۲۲۴ | ۰.۷۰۹ | ۰.۶۵۷ | ۰.۷۰ | ۱۲۴ | ۱۱۲ | ۶۴ | ۱۶.۹ | ۴.۳ |
| موبایلنت-نسخه ۲-۱-۲۲۴ | ۰.۷۱۹ | ۰.۶۳۷ | ۰.۷۰۹ | ۸۹ | ۹۸ | ۵۴ | ۱۴ | ۳.۶ |
| اینسپشن_نسخه ۳ | ۰.۷۸ | ۰.۷۷۲ | ۰.۷۷۵ | ۱۱۳۰ | ۸۴۵ عدد | ۵۴۳ | ۹۵.۷ | ۲۳.۹ |
| Resnet_v2_101 | ۰.۷۷۰ | ۰.۷۶۸ | ناموجود | ۳۹۷۳ عدد | ۲۸۶۸ عدد | ناموجود | ۱۷۸.۳ | ۴۴.۹ |
کوانتیزاسیون کامل عدد صحیح با فعالسازیهای int16 و وزنهای int8
کوانتیزاسیون با فعالسازیهای int16 یک طرح کوانتیزاسیون عدد صحیح کامل است که فعالسازیها در int16 و وزنها در int8 قرار دارند. این حالت میتواند دقت مدل کوانتیزه شده را در مقایسه با طرح کوانتیزاسیون عدد صحیح کامل که هم فعالسازیها و هم وزنها در int8 قرار دارند و اندازه مدل مشابهی را حفظ میکنند، بهبود بخشد. این روش زمانی توصیه میشود که فعالسازیها به کوانتیزاسیون حساس باشند.
توجه: در حال حاضر فقط پیادهسازیهای هسته مرجع بهینهسازی نشده در TFLite برای این طرح کوانتیزاسیون موجود است، بنابراین به طور پیشفرض عملکرد در مقایسه با هستههای int8 کند خواهد بود. در حال حاضر میتوان از طریق سختافزار تخصصی یا نرمافزار سفارشی به مزایای کامل این حالت دسترسی پیدا کرد.
در زیر نتایج دقت برخی از مدلهایی که از این حالت بهره میبرند، آمده است. مدل نوع معیار دقت دقت (فعالسازیهای float32) دقت (فعالسازیهای int8) دقت (فعالسازیهای int16) Wav2letter ور ۶.۷٪ ۷.۷٪ ۷.۲٪ DeepSpeech 0.5.1 (نسخه باز شده) سی ای آر ۶.۱۳٪ ۴۳.۶۷٪ ۶.۵۲٪ یولو وی۳ mAP (IOU=0.5) ۰.۵۷۷ ۰.۵۶۳ ۰.۵۷۴ موبایلنتوی۱ دقت بالا ۰.۷۰۶۲ ۰.۶۹۴ ۰.۶۹۳۶ موبایلنتوی۲ دقت بالا ۰.۷۱۸ ۰.۷۱۲۶ ۰.۷۱۳۷ موبایل برت F1 (تطابق دقیق) ۸۸.۸۱(۸۱.۲۳) ۲.۰۸(۰) ۸۸.۷۳(۸۱.۱۵)
هرس کردن
هرس کردن با حذف پارامترهایی در یک مدل که تأثیر کمی بر پیشبینیهای آن دارند، عمل میکند. مدلهای هرس شده اندازه یکسانی روی دیسک دارند و تأخیر زمان اجرا یکسانی دارند، اما میتوانند به طور مؤثرتری فشرده شوند. این امر هرس کردن را به یک تکنیک مفید برای کاهش حجم دانلود مدل تبدیل میکند.
در آینده، LiteRT کاهش تأخیر را برای مدلهای هرسشده فراهم خواهد کرد.
خوشهبندی
خوشهبندی با گروهبندی وزنهای هر لایه در یک مدل به تعداد از پیش تعریفشدهای از خوشهها، و سپس به اشتراک گذاشتن مقادیر مرکز ثقل برای وزنهای متعلق به هر خوشه جداگانه، کار میکند. این کار تعداد مقادیر وزنی منحصر به فرد در یک مدل را کاهش میدهد و در نتیجه پیچیدگی آن را کاهش میدهد.
در نتیجه، مدلهای خوشهای میتوانند به طور مؤثرتری فشرده شوند و مزایای استقرار مشابه هرس کردن را ارائه دهند.
گردش کار توسعه
به عنوان نقطه شروع، بررسی کنید که آیا مدلهای موجود در مدلهای میزبانیشده میتوانند برای برنامه شما کار کنند یا خیر. در غیر این صورت، توصیه میکنیم کاربران با ابزار کوانتیزاسیون پس از آموزش شروع کنند زیرا این ابزار به طور گسترده قابل اجرا است و نیازی به دادههای آموزشی ندارد.
برای مواردی که اهداف دقت و تأخیر برآورده نمیشوند، یا پشتیبانی از شتابدهنده سختافزاری مهم است، آموزش مبتنی بر کوانتیزاسیون گزینه بهتری است. برای تکنیکهای بهینهسازی بیشتر به جعبه ابزار بهینهسازی مدل TensorFlow مراجعه کنید.
اگر میخواهید اندازه مدل خود را بیشتر کاهش دهید، میتوانید قبل از کوانتیزه کردن مدلها ، هرس کردن و/یا خوشهبندی را امتحان کنید.