
LiteRT è il framework on-device di Google per il deployment di ML e AI generativa ad alte prestazioni su piattaforme edge.
Conversione, runtime e ottimizzazione efficienti per il machine learning sul dispositivo.
Basato sulle fondamenta collaudate di TensorFlow Lite
LiteRT non è solo una novità, ma la nuova generazione del runtime di machine learning più ampiamente implementato al mondo. Alimenta le app che usi tutti i giorni, offrendo bassa latenza e alta privacy su miliardi di dispositivi.
Considerato attendibile dalle app Google più importanti
Oltre 100.000 applicazioni, miliardi di utenti in tutto il mondo
Punti salienti di LiteRT

Cross Platform Ready

Sfruttare l'AI generativa
Accelerazione hardware semplificata

Supporto di più framework
Deployment tramite LiteRT
Semplifica il flusso di lavoro di deep learning dall'addestramento al deployment sul dispositivo.

1.Ottieni un modello
Utilizza modelli preaddestrati .tflite o converti modelli PyTorch, JAX o TensorFlow in .tflite.

2.Ottimizza
Utilizza il toolkit di ottimizzazione LiteRT per quantizzare i modelli dopo l'addestramento.

3.Corsa
Esegui il deployment del modello con LiteRT e scegli l'acceleratore ottimale per la tua app.
Scegliere il percorso di sviluppo
Utilizza LiteRT per eseguire il deployment dell'AI ovunque, dalle app mobile ad alte prestazioni ai dispositivi IoT con risorse limitate.
Utente TFLite esistente
Passaggio a LiteRT per sfruttare prestazioni migliorate e API unificate su tutte le piattaforme (Android, desktop, web).
BYOM : Bring your own Models
Avere un modello PyTorch e voler implementare esperienze audio o di visione sul dispositivo.
Deployment di modelli di AI generativa
Creare chatbot sofisticati sul dispositivo utilizzando modelli di AI generativa open-weight ottimizzati come Gemma o un altro modello open-weight.
[Avanzato] Esperto di modelli
Creazione di modelli personalizzati o esecuzione di ottimizzazioni specifiche dell'hardware per CPU/GPU/NPU per ottenere le massime prestazioni.
Esempi, modelli e demo

Visualizza l'app di esempio LiteRT su GitHub
App di esempio complete e end-to-end.

Visualizza i modelli di AI generativa
Modelli di AI generativa preaddestrati e pronti all'uso.

Guarda le demo - App galleria Google AI Edge
Una galleria che mostra casi d'uso di ML/AI generativa sul dispositivo utilizzando LiteRT.
Blog e annunci
Tieniti al corrente sugli ultimi annunci, sugli approfondimenti tecnici e sui benchmark delle prestazioni del team LiteRT.

Creare AI sul dispositivo per il mondo reale con LiteRT e NPU
Scopri come i leader del settore creano applicazioni di AI on-device ad alte prestazioni e reali utilizzando LiteRT e NPU.
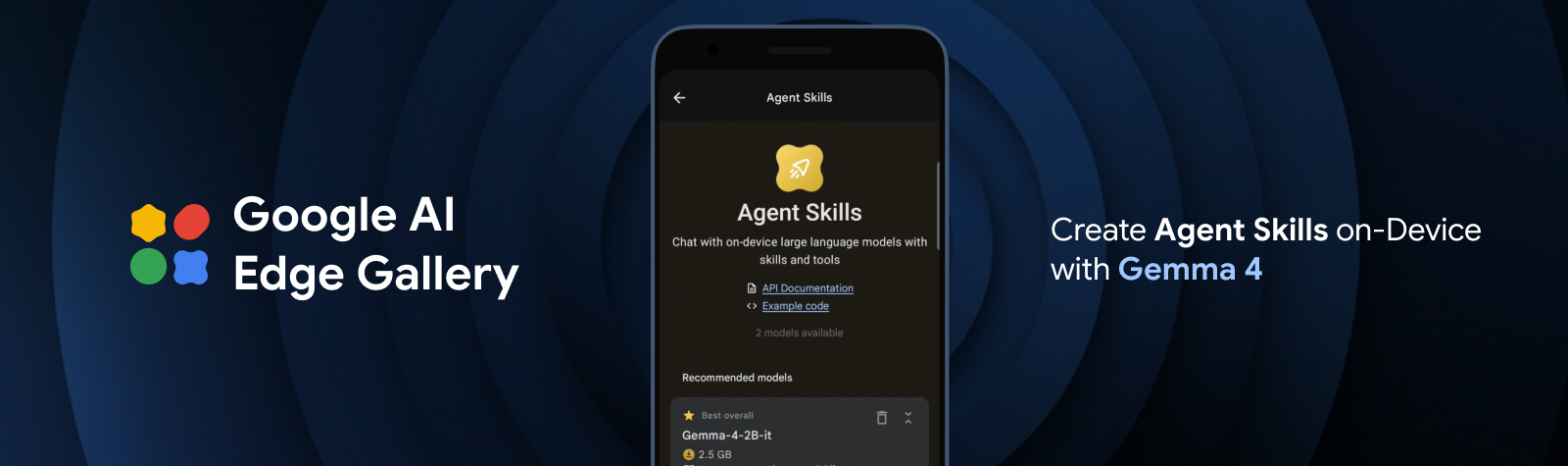
Porta competenze di agenti all'avanguardia sull'edge con Gemma 4
Esegui il deployment di funzionalità di pianificazione agentica e multi-step interamente sul dispositivo con la nuova famiglia Gemma 4 e LiteRT.

LiteRT: il framework universale per l'AI on-device
Il framework ML on-device unificato di Google, in evoluzione da TFLite per un deployment ad alte prestazioni.
NPU e LiteRT di MediaTek: potenziare la prossima generazione di AI on-device
Estensione del supporto dell'accelerazione della NPU ai chipset MediaTek per un'AI ad alta efficienza.
Massimizzare le prestazioni della NPU Qualcomm con LiteRT
Prestazioni rivoluzionarie per l'AI generativa sulle unità di elaborazione neurale Qualcomm.

LiteRT: prestazioni massime, semplificate
Ti presentiamo l'API CompiledModel per la selezione automatica dell'hardware e l'esecuzione asincrona.
GenAI on-device in Chrome, Chromebook Plus e Pixel Watch con LiteRT-LM
Esegui il deployment di modelli linguistici su dispositivi indossabili e piattaforme basate su browser utilizzando LiteRT-LM.

Modelli linguistici di piccole dimensioni, multimodalità e chiamate di funzione di Google AI Edge
Approfondimenti più recenti su RAG, multimodalità e chiamata di funzione per i modelli linguistici edge
Unisciti alla Community
Community GitHub di LiteRT
Contribuire direttamente al progetto e collaborare con gli sviluppatori principali.

Hugging Face Hub
Accedi a modelli open-weight ottimizzati su Hugging Face Hub.