
Gli operatori di machine learning (ML) utilizzati nel modello possono influire sul processo di conversione di un modello TensorFlow nel formato LiteRT. Il convertitore LiteRT supporta un numero limitato di operazioni TensorFlow utilizzate nei modelli di inferenza comuni, il che significa che non tutti i modelli sono convertibili direttamente. Lo strumento di conversione ti consente di includere operatori aggiuntivi, ma la conversione di un modello in questo modo richiede anche di modificare l'ambiente di runtime LiteRT che utilizzi per eseguire il modello, il che può limitare la tua capacità di utilizzare le opzioni di deployment del runtime standard, come i servizi Google Play.
LiteRT Converter è progettato per analizzare la struttura del modello e applicare ottimizzazioni per renderlo compatibile con gli operatori supportati direttamente. Ad esempio, a seconda degli operatori ML nel modello, il convertitore potrebbe elidere o unire questi operatori per mapparli alle loro controparti LiteRT.
Anche per le operazioni supportate, a volte sono previsti pattern di utilizzo specifici per motivi di rendimento. Il modo migliore per capire come creare un modello TensorFlow che può essere utilizzato con LiteRT è considerare attentamente come vengono convertite e ottimizzate le operazioni, nonché i limiti imposti da questo processo.
Operatori supportati
Gli operatori integrati di LiteRT sono un sottoinsieme degli operatori che fanno parte della libreria principale di TensorFlow. Il modello TensorFlow può includere anche operatori personalizzati sotto forma di operatori compositi o nuovi operatori definiti da te. Il diagramma seguente mostra le relazioni tra questi operatori.
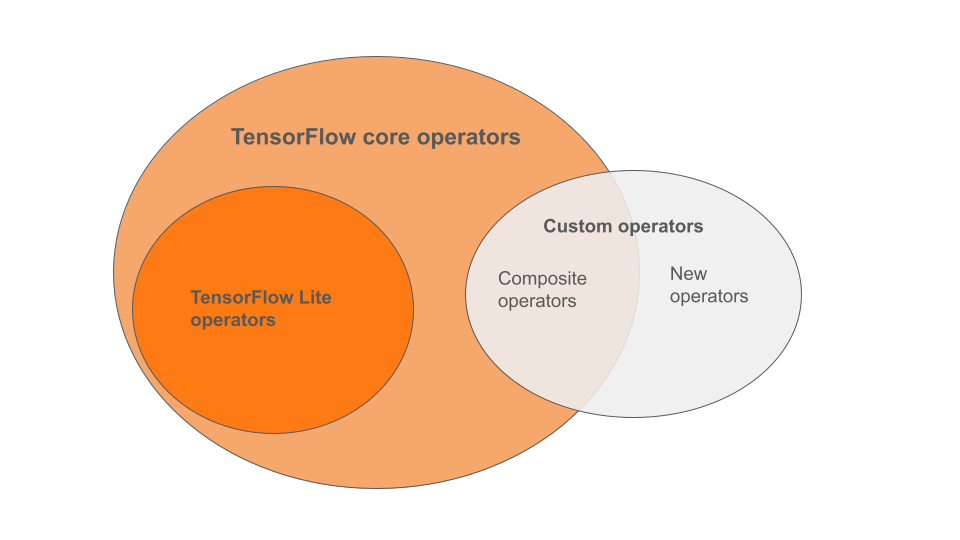
Da questa gamma di operatori di modelli ML, esistono tre tipi di modelli supportati dal processo di conversione:
- Modelli con solo operatore LiteRT integrato. (consigliato)
- Modelli con gli operatori integrati e seleziona gli operatori principali di TensorFlow.
- Modelli con operatori integrati, operatori TensorFlow Core e/o operatori personalizzati.
Se il modello contiene solo operazioni supportate in modo nativo da LiteRT, non sono necessari flag aggiuntivi per convertirlo. Questo è il percorso consigliato perché questo tipo di modello viene convertito senza problemi ed è più semplice da ottimizzare ed eseguire utilizzando il runtime LiteRT predefinito. Hai anche più opzioni di deployment per il tuo modello, ad esempio Google Play Services. Per iniziare, consulta la guida al convertitore LiteRT. Consulta la pagina LiteRT Ops per un elenco degli operatori integrati.
Se devi includere operazioni TensorFlow selezionate dalla libreria principale, devi specificarlo durante la conversione e assicurarti che il runtime includa queste operazioni. Per i passaggi dettagliati, consulta l'argomento Selezionare gli operatori TensorFlow.
Se possibile, evita l'ultima opzione di includere operatori personalizzati nel modello convertito. Gli operatori personalizzati sono operatori creati combinando più operatori primitivi di TensorFlow Core o definendone uno completamente nuovo. Quando gli operatori personalizzati vengono convertiti, possono aumentare le dimensioni del modello complessivo generando dipendenze al di fuori della libreria LiteRT integrata. Le operazioni personalizzate, se non create specificamente per il deployment su dispositivi mobili o dispositivi, possono comportarsi peggio se implementate su dispositivi con risorse limitate rispetto a un ambiente server. Infine, proprio come l'inclusione di operatori principali di TensorFlow selezionati, gli operatori personalizzati richiedono di modificare l'ambiente di runtime del modello, il che ti impedisce di sfruttare i servizi di runtime standard come i servizi Google Play.
Tipi supportati
La maggior parte delle operazioni LiteRT ha come target l'inferenza sia in virgola mobile (float32) sia quantizzata
(uint8, int8), ma molte operazioni non lo fanno ancora per altri tipi come
tf.float16 e stringhe.
Oltre a utilizzare versioni diverse delle operazioni, l'altra differenza tra i modelli in virgola mobile e quantizzati è il modo in cui vengono convertiti. La conversione quantizzata richiede informazioni sulla gamma dinamica per i tensori. Ciò richiede la "quantizzazione fittizia" durante l'addestramento del modello, l'ottenimento di informazioni sull'intervallo tramite un set di dati di calibrazione o l'esecuzione della stima dell'intervallo "al volo". Per ulteriori dettagli, consulta la sezione Quantizzazione.
Conversioni semplici, piegatura e fusione costanti
Un certo numero di operazioni TensorFlow può essere elaborato da LiteRT anche se non hanno un equivalente diretto. Questo vale per le operazioni che possono essere semplicemente
rimosse dal grafico (tf.identity), sostituite da tensori (tf.placeholder)
o unite in operazioni più complesse (tf.nn.bias_add). Anche alcune operazioni supportate
possono talvolta essere rimosse tramite uno di questi processi.
Di seguito è riportato un elenco non esaustivo delle operazioni TensorFlow che vengono in genere rimosse dal grafico:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
Operazioni sperimentali
Sono presenti le seguenti operazioni LiteRT, ma non sono pronte per i modelli personalizzati:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF