Generazione di immagini con Nano Banana
- Prova un'app Nano Banana 2
- Oppure crea il tuo da prompt:
-








-
Generato da Nano Banana 2 Prompt: "Una foto di una copertina di una rivista lucida. La copertina blu minimalista riporta le parole Nano Banana in grassetto e di grandi dimensioni. Il testo è in un carattere serif e riempie la visualizzazione. Nessun altro testo. Davanti al testo c'è il ritratto di una persona con un abito elegante e minimalista. Sta tenendo in mano in modo giocoso il numero 2, che è il punto focale.
Metti il numero del problema e la data "Feb 2026" nell'angolo insieme a un codice a barre. La rivista è su uno scaffale contro una parete intonacata di arancione, all'interno di un negozio di design." -
Generato da Nano Banana Pro Prompt: "Presenta una scena di cartoni animati 3D in miniatura chiara e isometrica dall'alto a 45° di Londra, con i suoi monumenti ed elementi architettonici più iconici. Utilizza texture morbide e raffinate con materiali PBR realistici e illuminazione e ombre delicate e realistiche. Integra le condizioni meteo attuali direttamente nell'ambiente della città per creare un'atmosfera immersiva. Utilizza una composizione pulita e minimalista con uno sfondo morbido e in tinta unita. Nella parte superiore centrale, inserisci il titolo "Londra" in grassetto grande, un'icona meteo in evidenza sotto, quindi la data (testo piccolo) e la temperatura (testo medio). Tutto il testo deve essere centrato con una spaziatura uniforme e può sovrapporsi leggermente alla parte superiore degli edifici."Scopri di più sul grounding della ricerca e provalo in AI Studio -
Generato da Nano Banana 2 Prompt: "Utilizza la ricerca immagini per trovare immagini accurate di un quetzal splendente. Crea un bellissimo sfondo 3:2 di questo uccello, con una sfumatura naturale dall'alto verso il basso e una composizione minimalista."Utilizza la funzionalità di grounding della Ricerca immagini di Google con Nano Banana 2. Prova in AI Studio -

Generato da Nano Banana Pro Prompt: "Inserisci questo logo in un annuncio di lusso per un profumo al profumo di banana. Il logo è perfettamente integrato nella bottiglia".Prova la conservazione dei dettagli ad alta fedeltà di Nano Banana in AI Studio -
Generato da Nano Banana Pro Prompt: "Una foto di una scena quotidiana in un caffè affollato che serve la colazione. In primo piano c'è un uomo anime con i capelli blu, una delle persone è un disegno a matita, un'altra è una persona in claymation"Sperimenta diversi stili artistici con Nano Banana in AI Studio -
Generato da Nano Banana Pro Prompt: "Usa la ricerca per scoprire come è stato accolto il lancio di Gemini 3 Flash. Utilizza queste informazioni per scrivere un breve articolo sull'argomento (con i titoli). Restituisci una foto dell'articolo così come appariva in una rivista patinata incentrata sul design. È una foto di una singola pagina piegata, che mostra l'articolo su Gemini 3 Flash. Una foto hero. Titolo in serif." -
Generato da Nano Banana Pro Prompt: "Un'icona che rappresenta un cane carino. Lo sfondo è bianco. Crea le icone in uno stile 3D colorato e tattile. Nessun testo."Crea icone, adesivi e asset con Nano Banana in AI Studio -
Generato da Nano Banana 2 Prompt: "Crea una foto perfettamente isometrica. Non è una miniatura, ma una foto acquisita che è risultata perfettamente isometrica. È la foto di un bellissimo giardino moderno. C'è una grande piscina a forma di 2 e le parole: Nano Banana 2."Prova la generazione di immagini fotorealistiche in AI Studio
Nano Banana è il nome delle funzionalità di generazione di immagini native di Gemini. Gemini può generare ed elaborare immagini in modo conversazionale con testo, immagini, video o una combinazione. In questo modo puoi creare, modificare e iterare le immagini con un controllo senza precedenti.
Nano Banana si riferisce a tre modelli distinti disponibili nell'API Gemini:
- Nano Banana 2: il modello Gemini 3.1 Flash Image (
gemini-3.1-flash-image). Questo modello è la controparte ad alta efficienza di Gemini 3 Pro Image, ottimizzato per la velocità e i casi d'uso degli sviluppatori con volumi elevati. - Nano Banana Pro: il modello Gemini 3 Pro Image
(
gemini-3-pro-image). Questo modello è progettato per la produzione di asset professionali, utilizza il ragionamento avanzato ("Thinking") per seguire istruzioni complesse e riprodurre testo ad alta fedeltà. - Nano Banana: il modello Gemini 2.5 Flash Image
(
gemini-2.5-flash-image). Questo modello è progettato per velocità ed efficienza, ottimizzato per attività a basso volume e bassa latenza.
Tutte le immagini generate includono una filigrana SynthID.
Generazione di immagini (da testo a immagine)
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
prompt = ("Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme")
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=[prompt],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("generated_image.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme";
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "gemini_generated_image.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class TextToImage {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image",
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("_01_generated_image.png"), blob.data().get());
}
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class TextToImage {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme" }
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("generated_image.png", imageBytes);
Console.WriteLine("Image saved as generated_image.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}]
}'
Modifica delle immagini (da testo e immagine a immagine)
Promemoria: assicurati di disporre dei diritti necessari per le immagini che carichi. Non generare contenuti che violano i diritti di altre persone, inclusi video o immagini che ingannano, molestano o danneggiano. L'utilizzo di questo servizio di AI generativa è soggetto alle nostre Norme relative all'uso vietato.
Fornisci un'immagine e utilizza prompt di testo per aggiungere, rimuovere o modificare elementi, cambiare lo stile o regolare la classificazione del colore.
Il seguente esempio mostra il caricamento di immagini codificate base64.
Per più immagini, payload più grandi e tipi MIME supportati, consulta la pagina Comprensione
delle immagini.
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
prompt = (
"Create a picture of my cat eating a nano-banana in a "
"fancy restaurant under the Gemini constellation",
)
image = Image.open("/path/to/cat_image.png")
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=[prompt, image],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("generated_image.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "path/to/cat_image.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ text: "Create a picture of my cat eating a nano-banana in a" +
"fancy restaurant under the Gemini constellation" },
{
inlineData: {
mimeType: "image/png",
data: base64Image,
},
},
];
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
imagePath := "/path/to/cat_image.png"
imgData, _ := os.ReadFile(imagePath)
parts := []*genai.Part{
genai.NewPartFromText("Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation"),
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/png",
Data: imgData,
},
},
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image",
contents,
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "gemini_generated_image.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class TextAndImageToImage {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image",
Content.fromParts(
Part.fromText("""
Create a picture of my cat eating a nano-banana in
a fancy restaurant under the Gemini constellation
"""),
Part.fromBytes(
Files.readAllBytes(
Path.of("src/main/resources/cat.jpg")),
"image/jpeg")),
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("gemini_generated_image.png"), blob.data().get());
}
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class TextAndImageToImage {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation" },
new Part
{
FileData = new FileData { FileUri = "file:///path/to/cat_image.png" }
}
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("gemini_generated_image.png", imageBytes);
Console.WriteLine("Image saved as gemini_generated_image.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{\"text\": \"'Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation\"},
{
\"inline_data\": {
\"mime_type\":\"image/jpeg\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
}
]
}]
}"
Modifica di immagini multi-turno
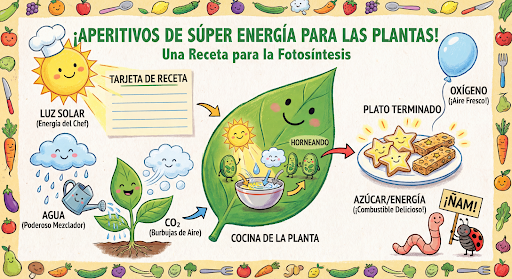
Continua a generare e modificare immagini in modo conversazionale. La chat o la conversazione multi-turno è il modo consigliato per iterare le immagini. L'esempio seguente mostra un prompt per generare un'infografica sulla fotosintesi.
Python
from google import genai
from google.genai import types
client = genai.Client()
chat = client.chats.create(
model="gemini-3.1-flash-image",
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
tools=[{"google_search": {}}]
)
)
message = "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader."
response = chat.send_message(message)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("photosynthesis.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const chat = ai.chats.create({
model: "gemini-3.1-flash-image",
config: {
responseModalities: ['TEXT', 'IMAGE'],
tools: [{googleSearch: {}}],
},
});
}
await main();
const message = "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader."
let response = await chat.sendMessage({message});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("photosynthesis.png", buffer);
console.log("Image saved as photosynthesis.png");
}
}
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
}
chat := model.StartChat()
message := "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader."
resp, err := chat.SendMessage(ctx, genai.Text(message))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("photosynthesis.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Chat;
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.RetrievalConfig;
import com.google.genai.types.Tool;
import com.google.genai.types.ToolConfig;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class MultiturnImageEditing {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.tools(Tool.builder()
.googleSearch(GoogleSearch.builder().build())
.build())
.build();
Chat chat = client.chats.create("gemini-3.1-flash-image", config);
GenerateContentResponse response = chat.sendMessage("""
Create a vibrant infographic that explains photosynthesis
as if it were a recipe for a plant's favorite food.
Show the "ingredients" (sunlight, water, CO2)
and the "finished dish" (sugar/energy).
The style should be like a page from a colorful
kids' cookbook, suitable for a 4th grader.
""");
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("photosynthesis.png"), blob.data().get());
}
}
}
// ...
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class MultiturnImageEditing {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader." }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "TEXT", "IMAGE" },
Tools = new List<Tool> { new Tool { GoogleSearch = new GoogleSearch() } }
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("photosynthesis.png", imageBytes);
Console.WriteLine("Image saved as photosynthesis.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"role": "user",
"parts": [
{"text": "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plants favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids cookbook, suitable for a 4th grader."}
]
}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'

Puoi quindi utilizzare la stessa chat per cambiare la lingua del grafico in spagnolo.
Python
message = "Update this infographic to be in Spanish. Do not change any other elements of the image."
aspect_ratio = "16:9" # "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
resolution = "2K" # "512", "1K", "2K", "4K"
response = chat.send_message(message,
config=types.GenerateContentConfig(
response_format={"image": {aspect_ratio: aspect_ratio, image_size: resolution}},
))
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("photosynthesis_spanish.png")
JavaScript
const message = 'Update this infographic to be in Spanish. Do not change any other elements of the image.';
const aspectRatio = '16:9';
const resolution = '2K';
let response = await chat.sendMessage({
message,
config: {
responseModalities: ['TEXT', 'IMAGE'],
responseFormat: {
image: {
aspectRatio: aspectRatio,
imageSize: resolution,
}
},
tools: [{googleSearch: {}}],
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("photosynthesis2.png", buffer);
console.log("Image saved as photosynthesis2.png");
}
}
Go
message = "Update this infographic to be in Spanish. Do not change any other elements of the image."
aspect_ratio = "16:9" // "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
resolution = "2K" // "512", "1K", "2K", "4K"
model.GenerationConfig.ImageConfig = &pb.ImageConfig{
AspectRatio: aspect_ratio,
ImageSize: resolution,
}
resp, err = chat.SendMessage(ctx, genai.Text(message))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("photosynthesis_spanish.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
Java
String aspectRatio = "16:9"; // "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
String resolution = "2K"; // "512", "1K", "2K", "4K"
config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio(aspectRatio)
.imageSize(resolution)
.build())
.build();
response = chat.sendMessage(
"Update this infographic to be in Spanish. " +
"Do not change any other elements of the image.",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("photosynthesis_spanish.png"), blob.data().get());
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class MultiturnImageEditingSpanish {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "Update this infographic to be in Spanish. Do not change any other elements of the image." }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "TEXT", "IMAGE" },
ImageConfig = new ImageConfig
{
AspectRatio = "16:9",
ImageSize = "2K"
}
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("photosynthesis_spanish.png", imageBytes);
Console.WriteLine("Image saved as photosynthesis_spanish.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [
{
"role": "user",
"parts": [{"text": "Create a vibrant infographic that explains photosynthesis..."}]
},
{
"role": "model",
"parts": [{"inline_data": {"mime_type": "image/png", "data": "<PREVIOUS_IMAGE_DATA>"}}]
},
{
"role": "user",
"parts": [{"text": "Update this infographic to be in Spanish. Do not change any other elements of the image."}]
}
],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"responseFormat": {
"image": {
"aspectRatio": "16:9",
"imageSize": "2K"
}
}
}
}'
Novità dei modelli Gemini 3 Image
Gemini 3 offre modelli allo stato dell'arte per la generazione e la modifica di immagini. Gemini 3.1 Flash Image è ottimizzato per la velocità e i casi d'uso ad alto volume, mentre Gemini 3 Pro Image è ottimizzato per la produzione di asset professionali. Progettati per affrontare i workflow più impegnativi grazie al ragionamento avanzato, sono ideali per attività di creazione e modifica complesse e multi-turno.
- Output ad alta risoluzione: funzionalità di generazione integrate per immagini 1K, 2K e 4K.
- Gemini 3.1 Flash Image aggiunge la risoluzione più piccola di 512 (0,5 K).
- Rendering avanzato del testo: in grado di generare testo leggibile e stilizzato per infografiche, menu, diagrammi e asset di marketing.
- Grounding con la Ricerca Google: il modello può utilizzare la Ricerca Google come strumento per
verificare i fatti e generare immagini basate su dati in tempo reale (ad es. mappe
meteo attuali, grafici azionari, eventi recenti).
- Gemini 3.1 Flash Image aggiunge l'integrazione di Grounding con la Ricerca Google per le immagini insieme alla Ricerca web.
- Modalità di pensiero: il modello utilizza un processo di "pensiero" per ragionare su prompt complessi. Genera "immagini di pensiero" provvisorie (visibili nel backend ma non addebitate) per perfezionare la composizione prima di produrre l'output finale di alta qualità.
- Fino a 14 immagini di riferimento: ora puoi combinare fino a 14 immagini di riferimento per produrre l'immagine finale.
- Nuove proporzioni: Gemini 3.1 Flash Image aggiunge le proporzioni 1:4, 4:1, 1:8 e 8:1.
Utilizza fino a 14 immagini di riferimento
I modelli di immagini Gemini 3 ti consentono di combinare fino a 14 immagini di riferimento. Queste 14 immagini possono includere:
| Gemini 3.1 Flash Image | Gemini 3 Pro Image |
|---|---|
| Fino a 10 immagini di oggetti ad alta fedeltà da includere nell'immagine finale | Fino a 6 immagini di oggetti ad alta fedeltà da includere nell'immagine finale |
| Fino a 4 immagini di personaggi per mantenere la coerenza | Fino a 5 immagini di personaggi per mantenere la coerenza |
| N/D | Fino a 3 immagini da utilizzare come riferimenti di stile |
Python
from google import genai
from google.genai import types
from PIL import Image
prompt = "An office group photo of these people, they are making funny faces."
aspect_ratio = "5:4" # "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
resolution = "2K" # "512", "1K", "2K", "4K"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=[
prompt,
Image.open('person1.png'),
Image.open('person2.png'),
Image.open('person3.png'),
Image.open('person4.png'),
Image.open('person5.png'),
],
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
response_format={"image": {aspect_ratio: aspect_ratio, image_size: resolution}},
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("office.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
'An office group photo of these people, they are making funny faces.';
const aspectRatio = '5:4';
const resolution = '2K';
const contents = [
{ text: prompt },
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile1,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile2,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile3,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile4,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile5,
},
}
];
const response = await ai.models.generateContent({
model: 'gemini-3.1-flash-image',
contents: contents,
config: {
responseModalities: ['TEXT', 'IMAGE'],
responseFormat: {
image: {
aspectRatio: aspectRatio,
imageSize: resolution,
}
},
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
ImageConfig: &pb.ImageConfig{
AspectRatio: "5:4",
ImageSize: "2K",
},
}
img1, err := os.ReadFile("person1.png")
if err != nil { log.Fatal(err) }
img2, err := os.ReadFile("person2.png")
if err != nil { log.Fatal(err) }
img3, err := os.ReadFile("person3.png")
if err != nil { log.Fatal(err) }
img4, err := os.ReadFile("person4.png")
if err != nil { log.Fatal(err) }
img5, err := os.ReadFile("person5.png")
if err != nil { log.Fatal(err) }
parts := []genai.Part{
genai.Text("An office group photo of these people, they are making funny faces."),
genai.ImageData{MIMEType: "image/png", Data: img1},
genai.ImageData{MIMEType: "image/png", Data: img2},
genai.ImageData{MIMEType: "image/png", Data: img3},
genai.ImageData{MIMEType: "image/png", Data: img4},
genai.ImageData{MIMEType: "image/png", Data: img5},
}
resp, err := model.GenerateContent(ctx, parts...)
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("office.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class GroupPhoto {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("5:4")
.imageSize("2K")
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image",
Content.fromParts(
Part.fromText("An office group photo of these people, they are making funny faces."),
Part.fromBytes(Files.readAllBytes(Path.of("person1.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person2.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person3.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person4.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person5.png")), "image/png")
), config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("office.png"), blob.data().get());
}
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class GroupPhoto {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "An office group photo of these people, they are making funny faces." },
new Part { FileData = new FileData { FileUri = "file:///person1.png" } },
new Part { FileData = new FileData { FileUri = "file:///person2.png" } },
new Part { FileData = new FileData { FileUri = "file:///person3.png" } },
new Part { FileData = new FileData { FileUri = "file:///person4.png" } },
new Part { FileData = new FileData { FileUri = "file:///person5.png" } }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "TEXT", "IMAGE" },
ImageConfig = new ImageConfig
{
AspectRatio = "5:4",
ImageSize = "2K"
}
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("office.png", imageBytes);
Console.WriteLine("Image saved as office.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{\"text\": \"An office group photo of these people, they are making funny faces.\"},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_1>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_2>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_3>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_4>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_5>\"}}
]
}],
\"generationConfig\": {
\"responseModalities\": [\"TEXT\", \"IMAGE\"],
\"responseFormat\": {
\"image\": {
\"aspectRatio\": \"5:4\",
\"imageSize\": \"2K\"
}
}
}
}"

Grounding con la Ricerca Google
Utilizza lo strumento Ricerca Google per generare immagini basate su informazioni in tempo reale, come previsioni meteo, grafici azionari o eventi recenti.
Tieni presente che quando utilizzi il grounding con la Ricerca Google con la generazione di immagini, i risultati di ricerca basati su immagini non vengono passati al modello di generazione e sono esclusi dalla risposta (vedi Grounding con la Ricerca Google per le immagini)
Python
from google import genai
prompt = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"
aspect_ratio = "16:9" # "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['Text', 'Image'],
response_format={"image": {aspect_ratio: aspect_ratio,}},
tools=[{"google_search": {}}]
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("weather.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt = 'Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day';
const aspectRatio = '16:9';
const resolution = '2K';
const response = await ai.models.generateContent({
model: 'gemini-3.1-flash-image',
contents: prompt,
config: {
responseModalities: ['TEXT', 'IMAGE'],
responseFormat: {
image: {
aspectRatio: aspectRatio,
imageSize: resolution,
}
},
tools: [{ googleSearch: {} }]
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.Tool;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class SearchGrounding {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.build())
.tools(Tool.builder()
.googleSearch(GoogleSearch.builder().build())
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image", """
Visualize the current weather forecast for the next 5 days
in San Francisco as a clean, modern weather chart.
Add a visual on what I should wear each day
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("weather.png"), blob.data().get());
}
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class SearchGrounding {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day" }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "TEXT", "IMAGE" },
ImageConfig = new ImageConfig
{
AspectRatio = "16:9"
},
Tools = new List<Tool> { new Tool { GoogleSearch = new GoogleSearch() } }
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("weather.png", imageBytes);
Console.WriteLine("Image saved as weather.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"}]}],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"responseFormat": {
"image": {"aspectRatio": "16:9"}
}
}
}'

La risposta include groundingMetadata, che contiene i seguenti campi obbligatori:
searchEntryPoint: contiene HTML e CSS per il rendering dei suggerimenti di ricerca richiesti.groundingChunks: restituisce le prime tre fonti web utilizzate per basare l'immagine generata
Grounding con la Ricerca Google per immagini (3.1 Flash)
Il grounding con la Ricerca Google per le immagini consente ai modelli di utilizzare le immagini web recuperate tramite la Ricerca Google come contesto visivo per la generazione di immagini. La ricerca di immagini è un nuovo tipo di ricerca all'interno dello strumento esistente Grounding con la Ricerca Google, che funziona insieme alla Ricerca web standard.
Per attivare la ricerca di immagini, configura lo strumento googleSearch nella richiesta API
e specifica imageSearch all'interno dell'oggetto searchTypes. La ricerca immagini può essere
utilizzata in modo indipendente o insieme alla ricerca web.
Tieni presente che la funzionalità di grounding con la Ricerca Google per le immagini non può essere utilizzata per cercare persone.
Python
from google import genai
prompt = "A detailed painting of a Timareta butterfly resting on a flower"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
tools=[
types.Tool(google_search=types.GoogleSearch(
search_types=types.SearchTypes(
web_search=types.WebSearch(),
image_search=types.ImageSearch()
)
))
]
)
)
# Display grounding sources if available
if response.candidates and response.candidates[0].grounding_metadata and response.candidates[0].grounding_metadata.search_entry_point:
display(HTML(response.candidates[0].grounding_metadata.search_entry_point.rendered_content))
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const ai = new GoogleGenAI({});
const prompt = "A detailed painting of a Timareta butterfly resting on a flower";
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: prompt,
config: {
responseModalities: ["IMAGE"],
tools: [
{
googleSearch: {
searchTypes: {
webSearch: {},
imageSearch: {}
}
}
}
]
}
});
// Display grounding sources if available
if (response.candidates && response.candidates[0].groundingMetadata && response.candidates[0].groundingMetadata.searchEntryPoint) {
console.log(response.candidates[0].groundingMetadata.searchEntryPoint.renderedContent);
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
pb "google.golang.org/genai/schema"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image")
model.Tools = []*pb.Tool{
{
GoogleSearch: &pb.GoogleSearch{
SearchTypes: &pb.SearchTypes{
WebSearch: &pb.WebSearch{},
ImageSearch: &pb.ImageSearch{},
},
},
},
}
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Image},
}
prompt := "A detailed painting of a Timareta butterfly resting on a flower"
resp, err := model.GenerateContent(ctx, genai.Text(prompt))
if err != nil {
log.Fatal(err)
}
if resp.Candidates[0].GroundingMetadata != nil && resp.Candidates[0].GroundingMetadata.SearchEntryPoint != nil {
fmt.Println(resp.Candidates[0].GroundingMetadata.SearchEntryPoint.RenderedContent)
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageSearch;
import com.google.genai.types.SearchTypes;
import com.google.genai.types.Tool;
import com.google.genai.types.WebSearch;
import java.io.IOException;
public class ImageSearchGrounding {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("IMAGE")
.tools(Tool.builder()
.googleSearch(GoogleSearch.builder()
.searchTypes(SearchTypes.builder()
.webSearch(WebSearch.builder().build())
.imageSearch(ImageSearch.builder().build())
.build())
.build())
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image",
"A detailed painting of a Timareta butterfly resting on a flower",
config);
if (response.candidates().isPresent() && !response.candidates().get().isEmpty()) {
var candidate = response.candidates().get().get(0);
if (candidate.groundingMetadata().isPresent() && candidate.groundingMetadata().get().searchEntryPoint().isPresent()) {
System.out.println(candidate.groundingMetadata().get().searchEntryPoint().get().renderedContent().orElse(""));
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.Threading.Tasks;
public class ImageSearchGrounding {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "A detailed painting of a Timareta butterfly resting on a flower" }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "IMAGE" },
Tools = new List<Tool>
{
new Tool
{
GoogleSearch = new GoogleSearch
{
SearchTypes = new SearchTypes
{
WebSearch = new WebSearch(),
ImageSearch = new ImageSearch()
}
}
}
}
}
);
foreach (var candidate in response.Candidates) {
if (candidate.GroundingMetadata != null && candidate.GroundingMetadata.SearchEntryPoint != null) {
Console.WriteLine(candidate.GroundingMetadata.SearchEntryPoint.RenderedContent);
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "A detailed painting of a Timareta butterfly resting on a flower"}]}],
"tools": [{"google_search": {"searchTypes": {"webSearch": {}, "imageSearch": {}}}}],
"generationConfig": {
"responseModalities": ["IMAGE"]
}
}'
Requisiti di visualizzazione
Quando utilizzi la ricerca immagini in Grounding con la Ricerca Google, devi rispettare le seguenti condizioni:
- Attribuzione della fonte: devi fornire un link alla pagina web contenente l'immagine di origine (la "pagina contenente", non il file immagine stesso) in un modo che l'utente riconoscerà come link.
- Navigazione diretta: se scegli anche di mostrare le immagini di origine, devi fornire un percorso diretto con un solo clic dalle immagini di origine alla pagina web di origine che le contiene. Non è consentita qualsiasi altra implementazione che ritardi o astragga l'accesso dell'utente finale alla pagina web di origine, inclusi, a titolo esemplificativo ma non esaustivo, qualsiasi percorso a più clic o l'utilizzo di un visualizzatore di immagini intermedio.
Risposta
Per le risposte basate sulla ricerca immagini, l'API fornisce un'attribuzione chiara
e metadati per collegare il suo output a fonti verificate. I campi chiave nell'oggetto
groundingMetadata includono:
imageSearchQueries: le query specifiche utilizzate dal modello per il contesto visivo (ricerca immagini).groundingChunks: contiene le informazioni sull'origine dei risultati recuperati. Per le origini immagini, questi verranno restituiti come URL di reindirizzamento utilizzando un nuovo tipo di chunk immagine. Questo blocco include:uri: l'URL della pagina web per l'attribuzione (la pagina di destinazione).image_uri: l'URL diretto dell'immagine.
groundingSupports: fornisce mappature specifiche che collegano i contenuti generati alla relativa fonte di citazione nei blocchi.searchEntryPoint: include il chip "Ricerca Google" contenente HTML e CSS conformi per il rendering dei suggerimenti di ricerca.
Generazione di immagini da video (3.1 Flash)
La generazione di immagini a partire da video ti consente di creare nuove immagini utilizzando il contesto di un video come riferimento multimodale. Questa funzionalità è utile per creare miniature video di alta qualità, poster cinematografici, infografiche riassuntive o nuove opere d'arte ispirate a una scena di un video.
Durante la generazione, il modello analizza i frame video nel contesto (fino al limite di token di input del modello di 131.072 token) per estrarre temi visivi ed eventi chiave, quindi li utilizza insieme al prompt di testo per sintetizzare l'immagine di output.
Puoi trasmettere URL di YouTube pubblici direttamente nella richiesta API o caricare file video locali utilizzando l'API Files.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Pass a public YouTube video URL as part of the contents
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=[
types.Part(
file_data=types.FileData(file_uri="https://www.youtube.com/watch?v=UTdfxFyOQTI"),
video_metadata=types.VideoMetadata(fps=0.5)
),
"Generate a poster image that captures the key themes of this video."
],
config=types.GenerateContentConfig(
response_modalities=["TEXT", "IMAGE"]
)
)
# Save the generated image part
for part in response.parts:
if part.inline_data is not None:
image = part.as_image()
image.save("video_poster.png")
print("Image saved as video_poster.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: [
{
fileData: {
fileUri: "https://www.youtube.com/watch?v=UTdfxFyOQTI",
},
videoMetadata: {
fps: 0.5
}
},
{ text: "Generate a poster image that captures the key themes of this video." }
],
config: {
responseModalities: ["TEXT", "IMAGE"]
}
});
for (const part of response.candidates[0].content.parts) {
if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("video_poster.png", buffer);
console.log("Image saved as video_poster.png");
}
}
}
main();
Go
package main
import (
"context"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
videoPart := genai.NewPartFromURI("https://www.youtube.com/watch?v=UTdfxFyOQTI", "video/mp4")
videoPart.VideoMetadata = &genai.VideoMetadata{FPS: genai.Ptr(0.5)}
parts := []*genai.Part{
videoPart,
genai.NewPartFromText("Generate a poster image that captures the key themes of this video."),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, err := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image",
contents,
&genai.GenerateContentConfig{
ResponseModalities: []string{"TEXT", "IMAGE"},
},
)
if err != nil {
log.Fatal(err)
}
for _, part := range result.Candidates[0].Content.Parts {
if part.InlineData != nil {
imageBytes := part.InlineData.Data
_ = os.WriteFile("video_poster.png", imageBytes, 0644)
log.Println("Image saved as video_poster.png")
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.FileData;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import com.google.genai.types.VideoMetadata;
import com.google.common.collect.ImmutableList;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class VideoToImage {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
Part videoPart = Part.builder()
.fileData(FileData.builder()
.fileUri("https://www.youtube.com/watch?v=UTdfxFyOQTI")
.build())
.videoMetadata(VideoMetadata.builder()
.fps(0.5)
.build())
.build();
Part textPart = Part.builder()
.text("Generate a poster image that captures the key themes of this video.")
.build();
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image",
Content.builder()
.role("user")
.parts(ImmutableList.of(videoPart, textPart))
.build(),
config);
for (Part part : response.parts()) {
if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("video_poster.png"), blob.data().get());
System.out.println("Image saved as video_poster.png");
}
}
}
}
}
}
C#
using Google.GenAI;
using Google.GenAI.Types;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class VideoToImage {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part
{
FileData = new FileData { FileUri = "https://www.youtube.com/watch?v=UTdfxFyOQTI" },
VideoMetadata = new VideoMetadata { Fps = 0.5 }
},
new Part { Text = "Generate a poster image that captures the key themes of this video." }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "TEXT", "IMAGE" }
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("video_poster.png", imageBytes);
Console.WriteLine("Image saved as video_poster.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{
"file_data": {
"file_uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI"
},
"video_metadata": {
"fps": 0.5
}
},
{"text": "Generate a poster image that captures the key themes of this video."}
]
}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'

Generare immagini con una risoluzione fino a 4K
I modelli di immagini Gemini 3 generano per impostazione predefinita 1000 immagini, ma possono anche produrre immagini a 2000, 4000 e 512 (0,5 K) (solo Gemini 3.1 Flash Image). Per generare asset a risoluzione più elevata, specifica image_size in generation_config.
Devi utilizzare una "K" maiuscola (ad es. 1K, 2K, 4K). Il valore 512 non utilizza il suffisso "K". I parametri in minuscolo (ad es. 1k) verranno rifiutati.
Python
from google import genai
from google.genai import types
prompt = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
aspect_ratio = "1:1" # "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
resolution = "1K" # "512", "1K", "2K", "4K"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
response_format={"image": {aspect_ratio: aspect_ratio, image_size: resolution}},
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("butterfly.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
'Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.';
const aspectRatio = '1:1';
const resolution = '1K';
const response = await ai.models.generateContent({
model: 'gemini-3.1-flash-image',
contents: prompt,
config: {
responseModalities: ['TEXT', 'IMAGE'],
responseFormat: {
image: {
aspectRatio: aspectRatio,
imageSize: resolution,
}
},
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
ImageConfig: &pb.ImageConfig{
AspectRatio: "1:1",
ImageSize: "1K",
},
}
prompt := "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
resp, err := model.GenerateContent(ctx, genai.Text(prompt))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("butterfly.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.Tool;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class HiRes {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.imageSize("4K")
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image", """
Da Vinci style anatomical sketch of a dissected Monarch butterfly.
Detailed drawings of the head, wings, and legs on textured
parchment with notes in English.
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("butterfly.png"), blob.data().get());
}
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class HiRes {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English." }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "TEXT", "IMAGE" },
ImageConfig = new ImageConfig
{
AspectRatio = "1:1",
ImageSize = "1K"
}
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("butterfly.png", imageBytes);
Console.WriteLine("Image saved as butterfly.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."}]}],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"responseFormat": {
"image": {"aspectRatio": "1:1", "imageSize": "1K"}
}
}
}'
Di seguito è riportata un'immagine di esempio generata da questo prompt:

Procedura di ragionamento
I modelli di immagine Gemini 3 sono modelli di ragionamento che utilizzano un processo di ragionamento ("Ragionamento") per i prompt complessi. Questa funzionalità è abilitata per impostazione predefinita e non può essere disattivata nell'API. Per saperne di più sul processo di pensiero, consulta la guida Il pensiero di Gemini.
Il modello genera fino a due immagini provvisorie per testare la composizione e la logica. L'ultima immagine all'interno di Pensiero è anche l'immagine finale renderizzata.
Puoi controllare i pensieri che hanno portato alla produzione dell'immagine finale.
Python
for part in response.parts:
if part.thought:
if part.text:
print(part.text)
elif image:= part.as_image():
image.show()
JavaScript
for (const part of response.candidates[0].content.parts) {
if (part.thought) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, 'base64');
fs.writeFileSync('image.png', buffer);
console.log('Image saved as image.png');
}
}
}
Java
for (Part part : response.parts()) {
if (part.thought().orElse(false)) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("image.png"), blob.data().get());
System.out.println("Image saved as image.png");
}
}
}
}
C#
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Thought) {
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("image.png", imageBytes);
Console.WriteLine("Image saved as image.png");
}
}
}
}
Controllare i livelli di pensiero
Con Gemini 3.1 Flash Image, puoi controllare la quantità di ragionamento che il modello
utilizza per bilanciare qualità e latenza. Il valore predefinito di thinkingLevel è minimal,
mentre i livelli supportati sono minimal e high. L'impostazione di
thinkingLevel su minimal fornisce le risposte con la latenza più bassa. Tieni presente che
il pensiero minimo non significa che il modello non utilizzi alcun pensiero.
Puoi aggiungere il valore booleano includeThoughts per determinare se i pensieri generati dal modello vengono restituiti nella risposta o rimangono nascosti.
Python
from google import genai
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents="A futuristic city built inside a giant glass bottle floating in space",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
thinking_level="High",
include_thoughts=True
),
)
)
for part in response.parts:
if part.thought: # Skip outputting thoughts
continue
if part.text:
display(Markdown(part.text))
elif image:= part.as_image():
image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: "A futuristic city built inside a giant glass bottle floating in space",
config: {
responseModalities: ["IMAGE"],
thinkingConfig: {
thinkingLevel: "High",
includeThoughts: true
},
},
});
for (const part of response.candidates[0].content.parts) {
if (part.thought) { // Skip outputting thoughts
continue;
}
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
pb "google.golang.org/genai/schema"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Image},
ThinkingConfig: &pb.ThinkingConfig{
ThinkingLevel: "High",
IncludeThoughts: true,
},
}
prompt := "A futuristic city built inside a giant glass bottle floating in space"
resp, err := model.GenerateContent(ctx, genai.Text(prompt))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if part.Thought { // Skip outputting thoughts
continue
}
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("image.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import com.google.genai.types.ThinkingConfig;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class ThinkingLevels {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("IMAGE")
.thinkingConfig(ThinkingConfig.builder()
.thinkingLevel("High")
.includeThoughts(true)
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image",
"A futuristic city built inside a giant glass bottle floating in space",
config);
for (Part part : response.parts()) {
if (part.thought().orElse(false)) {
// Skip outputting thoughts
continue;
}
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("image.png"), blob.data().get());
System.out.println("Image saved as image.png");
}
}
}
}
}
}
C#
using Google.GenAI;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
public class ThinkingLevels {
public static async Task Main(string[] args) {
var client = new Client();
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part>
{
new Part { Text = "A futuristic city built inside a giant glass bottle floating in space" }
},
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "IMAGE" },
ThinkingConfig = new ThinkingConfig
{
ThinkingLevel = "High",
IncludeThoughts = true
}
}
);
foreach (var candidate in response.Candidates) {
foreach (var part in candidate.Content.Parts) {
if (part.Thought) {
// Skip outputting thoughts
continue;
}
if (part.Text != null) {
Console.WriteLine(part.Text);
} else if (part.InlineData != null) {
var imageBytes = Convert.FromBase64String(part.InlineData.Data);
await File.WriteAllBytesAsync("image.png", imageBytes);
Console.WriteLine("Image saved as image.png");
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "A futuristic city built inside a giant glass bottle floating in space"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "High",
"includeThoughts": true
}
}
}'
Tieni presente che i token di pensiero vengono fatturati indipendentemente dal fatto che includeThoughts sia
impostato su true o false, poiché il processo di pensiero avviene sempre
per impostazione predefinita, indipendentemente dal fatto che tu lo visualizzi o meno.
Firme del pensiero
Le firme del pensiero sono rappresentazioni criptate del
processo di pensiero interno del modello e vengono utilizzate per preservare il contesto del ragionamento
nelle interazioni multi-turno. Tutte le risposte includono un campo thought_signature. Come regola generale, se ricevi una firma del pensiero nella risposta di un modello, devi restituirla esattamente come l'hai ricevuta quando invii la cronologia della conversazione nel turno successivo. La mancata circolazione delle firme del pensiero
potrebbe causare l'esito negativo della risposta. Per ulteriori spiegazioni sulle firme in generale, consulta la documentazione relativa alla firma del pensiero.
Ecco come funzionano le firme del pensiero:
- Tutte le parti
inline_datacon l'immaginemimetypeche fanno parte della risposta devono avere una firma. - Se all'inizio (prima di qualsiasi immagine) sono presenti alcune parti di testo subito dopo i pensieri, anche la prima parte di testo deve avere una firma.
- Se le parti
inline_datacon l'immaginemimetypefanno parte dei pensieri, non avranno firme.
Il seguente codice mostra un esempio di dove sono incluse le firme dei pensieri:
[
{
"inline_data": {
"data": "<base64_image_data_0>",
"mime_type": "image/png"
},
"thought": true // Thoughts don't have signatures
},
{
"inline_data": {
"data": "<base64_image_data_1>",
"mime_type": "image/png"
},
"thought": true // Thoughts don't have signatures
},
{
"inline_data": {
"data": "<base64_image_data_2>",
"mime_type": "image/png"
},
"thought": true // Thoughts don't have signatures
},
{
"text": "Here is a step-by-step guide to baking macarons, presented in three separate images.\n\n### Step 1: Piping the Batter\n\nThe first step after making your macaron batter is to pipe it onto a baking sheet. This requires a steady hand to create uniform circles.\n\n",
"thought_signature": "<Signature_A>" // The first non-thought part always has a signature
},
{
"inline_data": {
"data": "<base64_image_data_3>",
"mime_type": "image/png"
},
"thought_signature": "<Signature_B>" // All image parts have a signatures
},
{
"text": "\n\n### Step 2: Baking and Developing Feet\n\nOnce piped, the macarons are baked in the oven. A key sign of a successful bake is the development of \"feet\"—the ruffled edge at the base of each macaron shell.\n\n"
// Follow-up text parts don't have signatures
},
{
"inline_data": {
"data": "<base64_image_data_4>",
"mime_type": "image/png"
},
"thought_signature": "<Signature_C>" // All image parts have a signatures
},
{
"text": "\n\n### Step 3: Assembling the Macaron\n\nThe final step is to pair the cooled macaron shells by size and sandwich them together with your desired filling, creating the classic macaron dessert.\n\n"
},
{
"inline_data": {
"data": "<base64_image_data_5>",
"mime_type": "image/png"
},
"thought_signature": "<Signature_D>" // All image parts have a signatures
}
]
Altre modalità di generazione delle immagini
Gemini supporta altre modalità di interazione con le immagini in base alla struttura del prompt e al contesto, tra cui:
- Testo in immagini e testo (interleaved): restituisce immagini con testo correlato.
- Prompt di esempio: "Genera una ricetta illustrata per una paella".
- Immagini e testo in immagini e testo (interleaved): utilizza immagini e testo di input per creare nuove immagini e testo correlati.
- Prompt di esempio: (con un'immagine di una stanza arredata) "Quali altri divani di colore diverso si adatterebbero al mio spazio? Puoi aggiornare l'immagine?"
Generare immagini in batch
Se devi generare molte immagini, puoi utilizzare l'API Batch. In cambio di un turnaround fino a 24 ore, ottieni limiti di frequenza più elevati.
Consulta la documentazione sulla generazione di immagini dell'API Batch e il cookbook per esempi e codice di immagini dell'API Batch.
Guida e strategie per i prompt
Per padroneggiare la generazione di immagini, devi partire da un principio fondamentale:
Descrivi la scena, non elencare solo le parole chiave. Il punto di forza principale del modello è la sua profonda comprensione del linguaggio. Un paragrafo narrativo e descrittivo produrrà quasi sempre un'immagine migliore e più coerente rispetto a un elenco di parole scollegate.
Prompt per la generazione di immagini
Le seguenti strategie ti aiuteranno a creare prompt efficaci per generare esattamente le immagini che stai cercando.
Fotografia
Per immagini realistiche, utilizza termini fotografici. Menziona angolazioni della videocamera, tipi di obiettivo, illuminazione e dettagli precisi per guidare il modello verso un risultato realistico.
| Prompt | Output generato |
|---|---|
| Una foto di un ritratto in primo piano di un ceramista giapponese anziano con rughe profonde e incise dal sole e un sorriso caloroso e consapevole. Sta esaminando attentamente una ciotola da tè appena smaltata. L'ambientazione è il suo laboratorio rustico e assolato. La scena è illuminata da una luce soffusa dell'ora d'oro che entra da una finestra, mettendo in risalto la trama fine dell'argilla. Scattata con un obiettivo da ritratto da 85 mm, che ha prodotto uno sfondo morbido e sfocato (bokeh). L'atmosfera generale è serena e magistrale. Orientamento verticale. |

|
Illustrazioni e adesivi stilizzati
Per creare adesivi, icone o asset, specifica lo stile e richiedi uno sfondo bianco.
| Prompt | Output generato |
|---|---|
| Adesivo in stile kawaii di un panda rosso felice che indossa un piccolo cappello di bambù. Sta mangiando una foglia di bambù verde. Il design è caratterizzato da contorni puliti e decisi, ombreggiatura semplice e una tavolozza di colori vivaci. Lo sfondo deve essere bianco. |

|
Testo accurato nelle immagini
Gemini eccelle nel rendering del testo. Descrivi in modo chiaro il testo, lo stile del carattere e il design complessivo. Utilizza Gemini 3 Pro Image per la produzione di asset professionali.
| Prompt | Output generato |
|---|---|
| Crea un logo moderno e minimalista per una caffetteria chiamata "The Daily Grind". Il testo deve essere in un carattere sans-serif pulito e in grassetto. La combinazione di colori è in bianco e nero. Inserisci il logo in un cerchio. Utilizza un chicco di caffè in modo intelligente. |
|
Mockup di prodotti e fotografia commerciale
Ideale per creare foto di prodotti pulite e professionali per l'e-commerce, la pubblicità o il branding.
| Prompt | Output generato |
|---|---|
| Fotografia di un prodotto ad alta risoluzione illuminato in studio di una tazza da caffè in ceramica minimalista di colore nero opaco, presentata su una superficie in cemento lucido. L'illuminazione è una configurazione softbox a tre punti progettata per creare luci morbide e diffuse ed eliminare le ombre marcate. L'angolazione della fotocamera è leggermente rialzata a 45 gradi per mostrare le linee pulite. Ultrarealistico, con una messa a fuoco nitida sul vapore che sale dal caffè. Immagine quadrata. |

|
Design minimalista e con spazio negativo
Ideale per creare sfondi per siti web, presentazioni o materiali di marketing in cui verrà sovrapposto il testo.
| Prompt | Output generato |
|---|---|
| Una composizione minimalista con una singola e delicata foglia d'acero rossa posizionata in basso a destra dell'inquadratura. Lo sfondo è una tela bianco sporco vasta e vuota, che crea uno spazio negativo significativo per il testo. Illuminazione soffusa e diffusa dall'angolo in alto a sinistra. Immagine quadrata. |

|
Arte sequenziale (riquadro di fumetto / storyboard)
Si basa sulla coerenza dei personaggi e sulla descrizione delle scene per creare pannelli per lo storytelling visivo. Per una maggiore precisione con il testo e la capacità di narrazione, questi prompt funzionano meglio con Gemini 3.1 Pro e Gemini 3.1 Flash Image.
| Prompt | Output generato |
|---|---|
|
Input image: 
Prompt: crea un fumetto di tre vignette in uno stile artistico noir e crudo con inchiostri in bianco e nero ad alto contrasto. Inserisci il personaggio in una scena umoristica. |

|
Grounding con la Ricerca Google
Utilizza la Ricerca Google per generare immagini basate su informazioni recenti o in tempo reale. Questa funzionalità è utile per notizie, meteo e altri argomenti sensibili al fattore tempo.
| Prompt | Output generato |
|---|---|
| Crea una grafica semplice ma elegante della partita di ieri sera dell'Arsenal in Champions League |

|
Prompt per la modifica delle immagini
Questi esempi mostrano come fornire immagini insieme ai prompt di testo per la modifica, la composizione e il trasferimento dello stile.
Aggiunta e rimozione di elementi
Fornisci un'immagine e descrivi la modifica. Il modello corrisponderà allo stile, all'illuminazione e alla prospettiva dell'immagine originale.
| Prompt | Output generato |
|---|---|
|
Input image: 
Prompt: utilizzando l'immagine fornita del mio gatto, aggiungi un piccolo cappello da mago lavorato a maglia sulla sua testa. Fai in modo che sembri seduto comodamente e che l'illuminazione corrisponda a quella della foto. |

|
Inpainting (mascheramento semantico)
Definisci in modo conversazionale una "maschera" per modificare una parte specifica di un'immagine lasciando il resto invariato.
| Prompt | Output generato |
|---|---|
|
Input image: 
Prompt: utilizzando l'immagine fornita di un soggiorno, cambia solo il divano blu in un divano Chesterfield vintage in pelle marrone. Lascia invariato il resto della stanza, inclusi i cuscini sul divano e l'illuminazione. |

|
Trasferimento stile
Fornisci un'immagine e chiedi al modello di ricreare i suoi contenuti in uno stile artistico diverso.
| Prompt | Output generato |
|---|---|
|
Input image: 
Prompt: trasforma la fotografia fornita di una strada moderna di una città di notte nello stile artistico di "Notte stellata" di Vincent van Gogh. Preserva la composizione originale di edifici e auto, ma esegui il rendering di tutti gli elementi con pennellate vorticose e materiche e una tavolozza drammatica di blu intensi e gialli brillanti. |

|
Composizione avanzata: combinare più immagini
Fornisci più immagini come contesto per creare una nuova scena composita. È perfetto per i mockup di prodotti o i collage creativi.
| Prompt | Output generato |
|---|---|
|
Immagini di input: 

Prompt: crea una foto di moda professionale per l'e-commerce. Prendi l'abito a fiori blu della prima immagine e fallo indossare alla donna della seconda immagine. Genera uno scatto realistico a figura intera della donna che indossa l'abito, con l'illuminazione e le ombre regolate in modo che corrispondano all'ambiente esterno. |

|
Conservazione dei dettagli ad alta fedeltà
Per assicurarti che i dettagli importanti (come un volto o un logo) vengano conservati durante una modifica, descrivili in modo molto dettagliato insieme alla richiesta di modifica.
| Prompt | Output generato |
|---|---|
|
Immagini di input: 
Prompt:prendi la prima immagine della donna con capelli castani, occhi azzurri e un'espressione neutra. Aggiungi il logo della seconda immagine alla sua t-shirt nera. Assicurati che il volto e i tratti della donna rimangano completamente invariati. Il logo deve sembrare stampato in modo naturale sul tessuto, seguendo le pieghe della maglietta. |
|
Dare vita a qualcosa
Carica uno schizzo o un disegno e chiedi al modello di perfezionarlo in un'immagine finita.
| Prompt | Output generato |
|---|---|
|
Input image: 
Prompt: trasforma questo schizzo a matita approssimativo di un'auto futuristica in una foto impeccabile del concept car finito in uno showroom. Mantieni le linee eleganti e il profilo basso dello schizzo, ma aggiungi vernice blu metallizzata e illuminazione del cerchione al neon. |

|
Coerenza dei personaggi: visualizzazione a 360°
Puoi generare visualizzazioni a 360 gradi di un personaggio chiedendo in modo iterativo angolazioni diverse. Per ottenere risultati ottimali, includi le immagini generate in precedenza nei prompt successivi per mantenere la coerenza. Per le pose complesse, includi un'immagine di riferimento della posa desiderata.
| Prompt | Output generato |
|---|---|
|
Input image:
Prompt: un ritratto in studio di quest'uomo su sfondo bianco, di profilo e rivolto verso destra |


|
Best practice
Per migliorare i tuoi risultati, incorpora queste strategie professionali nel tuo flusso di lavoro.
- Sii iper-specifico: più dettagli fornisci, maggiore è il controllo che hai. Invece di "armatura fantasy", descrivila: "armatura a piastre elfica riccamente decorata, incisa con motivi a foglie d'argento, con un colletto alto e spallacci a forma di ali di falco".
- Fornisci contesto e intenzione:spiega lo scopo dell'immagine. La comprensione del contesto da parte del modello influenzerà l'output finale. Ad esempio, "Crea un logo per un brand di prodotti per la cura della pelle minimalista di fascia alta" produrrà risultati migliori rispetto a "Crea un logo".
- Esegui l'iterazione e perfeziona:non aspettarti un'immagine perfetta al primo tentativo. Sfrutta la natura conversazionale del modello per apportare piccole modifiche. Segui con prompt come "Ottimo, ma puoi rendere l'illuminazione un po' più calda?" o "Lascia tutto invariato, ma cambia l'espressione del personaggio in modo che sia più serio".
- Utilizza istruzioni passo passo:per scene complesse con molti elementi, suddividi il prompt in passaggi. "Per prima cosa, crea uno sfondo di una serena foresta nebbiosa all'alba. Poi, in primo piano, aggiungi un antico altare in pietra ricoperto di muschio. Infine, posiziona una spada singola e luminosa sopra l'altare".
- Utilizza "prompt negativi semantici": invece di dire "no auto", descrivi la scena desiderata in modo positivo: "una strada vuota e deserta senza segni di traffico".
- Controlla la fotocamera:utilizza un linguaggio fotografico e cinematografico per controllare
la composizione. Termini come
wide-angle shot,macro shot,low-angle perspective.
Limitazioni
- Per ottenere prestazioni ottimali, utilizza le seguenti lingue: EN, ar-EG, de-DE, es-MX, fr-FR, hi-IN, id-ID, it-IT, ja-JP, ko-KR, pt-BR, ru-RU, ua-UA, vi-VN, zh-CN.
- La generazione di immagini non supporta gli input audio. Gli input video sono supportati solo per Gemini 3.1 Flash Image.
- Il modello non sempre segue il numero esatto di output di immagini richiesto esplicitamente dall'utente.
gemini-2.5-flash-imagefunziona al meglio con un massimo di tre immagini come input, mentregemini-3-pro-imagesupporta cinque immagini ad alta fedeltà e fino a 14 immagini in totale.gemini-3.1-flash-imagesupporta la somiglianza dei personaggi fino a 4 caratteri e la fedeltà fino a 10 oggetti in un unico flusso di lavoro.- Quando genera testo per un'immagine, Gemini funziona meglio se prima genera il testo e poi chiede un'immagine con il testo.
gemini-3.1-flash-imageAl momento, il grounding con la Ricerca Google non supporta l'utilizzo di immagini di persone del mondo reale provenienti dalla ricerca web.- Tutte le immagini generate includono una filigrana SynthID.
Configurazioni facoltative
Facoltativamente, puoi configurare le modalità di risposta e le proporzioni dell'output del modello nel campo config delle chiamate generate_content.
Tipi di output
Il modello restituisce per impostazione predefinita risposte di testo e immagini
(ad es. response_modalities=['Text', 'Image']).
Puoi configurare la risposta in modo che restituisca solo immagini senza testo utilizzando
response_modalities=['Image'].
Python
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=['Image']
)
)
JavaScript
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: prompt,
config: {
responseModalities: ['Image']
}
});
Go
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
&genai.GenerateContentConfig{
ResponseModalities: "Image",
},
)
Java
response = client.models.generateContent(
"gemini-3.1-flash-image",
prompt,
GenerateContentConfig.builder()
.responseModalities("IMAGE")
.build());
C#
var response = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part> { new Part { Text = prompt } },
config: new GenerateContentConfig
{
ResponseModalities = new List<string> { "IMAGE" }
}
);
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}],
"generationConfig": {
"responseModalities": ["Image"]
}
}'
Proporzioni e dimensioni delle immagini
Per impostazione predefinita, il modello fa corrispondere le dimensioni dell'immagine di output a quelle dell'immagine di input
oppure genera quadrati 1:1.
Puoi controllare le proporzioni dell'immagine di output utilizzando il campo aspect_ratio
in response_format nella richiesta di risposta, come mostrato qui:
Python
# For gemini-2.5-flash-image
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents=[prompt],
config=types.GenerateContentConfig(
response_format={"image": {aspect_ratio: "16:9",}}
)
)
# For gemini-3.1-flash-image and gemini-3-pro-image
response = client.models.generate_content(
model="gemini-3.1-flash-image",
contents=[prompt],
config=types.GenerateContentConfig(
response_format={"image": {aspect_ratio: "16:9", image_size: "2K",}}
)
)
JavaScript
// For gemini-2.5-flash-image
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
config: {
responseFormat: {
image: {
aspectRatio: "16:9",
}
},
}
});
// For gemini-3.1-flash-image and gemini-3-pro-image
const response_gemini3 = await ai.models.generateContent({
model: "gemini-3.1-flash-image",
contents: prompt,
config: {
responseFormat: {
image: {
aspectRatio: "16:9",
imageSize: "2K",
}
},
}
});
Go
// For gemini-2.5-flash-image
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
&genai.GenerateContentConfig{
ImageConfig: &genai.ImageConfig{
AspectRatio: "16:9",
},
}
)
// For gemini-3.1-flash-image and gemini-3-pro-image
result_gemini3, _ := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
&genai.GenerateContentConfig{
ImageConfig: &genai.ImageConfig{
AspectRatio: "16:9",
ImageSize: "2K",
},
}
)
Java
// For gemini-2.5-flash-image
response = client.models.generateContent(
"gemini-2.5-flash-image",
prompt,
GenerateContentConfig.builder()
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.build())
.build());
// For gemini-3.1-flash-image and gemini-3-pro-image
response_gemini3 = client.models.generateContent(
"gemini-3.1-flash-image",
prompt,
GenerateContentConfig.builder()
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.imageSize("2K")
.build())
.build());
C#
// For gemini-2.5-flash-image
var response = await client.Models.GenerateContentAsync(
model: "gemini-2.5-flash-image",
contents: new List<Part> { new Part { Text = prompt } },
config: new GenerateContentConfig
{
ImageConfig = new ImageConfig
{
AspectRatio = "16:9"
}
}
);
// For gemini-3.1-flash-image and gemini-3-pro-image
var response_gemini3 = await client.Models.GenerateContentAsync(
model: "gemini-3.1-flash-image",
contents: new List<Part> { new Part { Text = prompt } },
config: new GenerateContentConfig
{
ImageConfig = new ImageConfig
{
AspectRatio = "16:9",
ImageSize = "2K"
}
}
);
REST
# For gemini-2.5-flash-image
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}],
"generationConfig": {
"responseFormat": {
"image": {
"aspectRatio": "16:9"
}
}
}
}'
# For gemini-3-pro-image
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1/models/gemini-3.1-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}],
"generationConfig": {
"responseFormat": {
"image": {
"aspectRatio": "16:9",
"imageSize": "2K"
}
}
}
}'
I diversi formati disponibili e le dimensioni dell'immagine generata sono elencati nelle tabelle seguenti:
3.1 Flash Image
| Proporzioni | Risoluzione 512 | 500 token | Risoluzione 1K | 1000 token | Risoluzione 2K | 2000 token | Risoluzione 4K | 4K token |
|---|---|---|---|---|---|---|---|---|
| 1:1 | 512x512 | 747 | 1024x1024 | 1120 | 2048x2048 | 1680 | 4096x4096 | 2520 |
| 1:4 | 256x1024 | 747 | 512x2048 | 1120 | 1024x4096 | 1680 | 2048x8192 | 2520 |
| 1:08 | 192x1536 | 747 | 384x3072 | 1120 | 768x6144 | 1680 | 1536x12288 | 2520 |
| 2:3 | 424x632 | 747 | 848x1264 | 1120 | 1696x2528 | 1680 | 3392x5056 | 2520 |
| 3:2 | 632x424 | 747 | 1264x848 | 1120 | 2528x1696 | 1680 | 5056x3392 | 2520 |
| 3:4 | 448x600 | 747 | 896x1200 | 1120 | 1792x2400 | 1680 | 3584x4800 | 2520 |
| 4:1 | 1024x256 | 747 | 2048x512 | 1120 | 4096x1024 | 1680 | 8192x2048 | 2520 |
| 4:3 | 600x448 | 747 | 1200x896 | 1120 | 2400x1792 | 1680 | 4800x3584 | 2520 |
| 4:5 | 464x576 | 747 | 928x1152 | 1120 | 1856x2304 | 1680 | 3712x4608 | 2520 |
| 5:4 | 576x464 | 747 | 1152x928 | 1120 | 2304x1856 | 1680 | 4608x3712 | 2520 |
| 8:1 | 1536x192 | 747 | 3072x384 | 1120 | 6144x768 | 1680 | 12288x1536 | 2520 |
| 9:16 | 384x688 | 747 | 768x1376 | 1120 | 1536x2752 | 1680 | 3072x5504 | 2520 |
| 16:9 | 688x384 | 747 | 1376x768 | 1120 | 2752x1536 | 1680 | 5504x3072 | 2520 |
| 21:9 | 792x168 | 747 | 1584x672 | 1120 | 3168x1344 | 1680 | 6336x2688 | 2520 |
3.1 Pro Image
| Proporzioni | Risoluzione 1K | 1000 token | Risoluzione 2K | 2000 token | Risoluzione 4K | 4K token |
|---|---|---|---|---|---|---|
| 1:1 | 1024x1024 | 1120 | 2048x2048 | 1120 | 4096x4096 | 2000 |
| 2:3 | 848x1264 | 1120 | 1696x2528 | 1120 | 3392x5056 | 2000 |
| 3:2 | 1264x848 | 1120 | 2528x1696 | 1120 | 5056x3392 | 2000 |
| 3:4 | 896x1200 | 1120 | 1792x2400 | 1120 | 3584x4800 | 2000 |
| 4:3 | 1200x896 | 1120 | 2400x1792 | 1120 | 4800x3584 | 2000 |
| 4:5 | 928x1152 | 1120 | 1856x2304 | 1120 | 3712x4608 | 2000 |
| 5:4 | 1152x928 | 1120 | 2304x1856 | 1120 | 4608x3712 | 2000 |
| 9:16 | 768x1376 | 1120 | 1536x2752 | 1120 | 3072x5504 | 2000 |
| 16:9 | 1376x768 | 1120 | 2752x1536 | 1120 | 5504x3072 | 2000 |
| 21:9 | 1584x672 | 1120 | 3168x1344 | 1120 | 6336x2688 | 2000 |
Gemini 2.5 Flash Image
| Proporzioni | Risoluzione | Token |
|---|---|---|
| 1:1 | 1024x1024 | 1290 |
| 2:3 | 832x1248 | 1290 |
| 3:2 | 1248x832 | 1290 |
| 3:4 | 864x1184 | 1290 |
| 4:3 | 1184x864 | 1290 |
| 4:5 | 896x1152 | 1290 |
| 5:4 | 1152x896 | 1290 |
| 9:16 | 768x1344 | 1290 |
| 16:9 | 1344x768 | 1290 |
| 21:9 | 1536x672 | 1290 |
Selezione del modello
Scegli il modello più adatto al tuo caso d'uso specifico.
Gemini 3.1 Flash Image (Nano Banana 2) dovrebbe essere il tuo modello di generazione di immagini di riferimento, in quanto offre le migliori prestazioni e la migliore intelligenza in assoluto in termini di equilibrio tra costi e latenza. Per ulteriori dettagli, consulta la pagina relativa ai prezzi e alle funzionalità del modello.
Gemini 3 Pro Image (Nano Banana Pro) è progettato per la produzione di asset professionali e istruzioni complesse. Questo modello è caratterizzato da una base di dati reali che utilizza la Ricerca Google, un processo di "Pensiero" predefinito che perfeziona la composizione prima della generazione e può generare immagini con risoluzioni fino a 4K. Per ulteriori dettagli, consulta la pagina relativa ai prezzi e alle funzionalità del modello.
Gemini 2.5 Flash Image (Nano Banana) è progettato per la velocità e l'efficienza. Questo modello è ottimizzato per attività ad alto volume e bassa latenza e genera immagini con una risoluzione di 1024 px. Per ulteriori dettagli, consulta la pagina relativa ai prezzi e alle funzionalità del modello.
Quando utilizzare Imagen
Oltre a utilizzare le funzionalità di generazione di immagini integrate di Gemini, puoi accedere anche a Imagen, il nostro modello specializzato di generazione di immagini, tramite l'API Gemini. Pianifica la migrazione prima della data di chiusura.
Passaggi successivi
- Trova altri esempi e campioni di codice nella guida al cookbook.
- Consulta la guida di Veo per scoprire come generare video con l'API Gemini.
- Per scoprire di più sui modelli Gemini, consulta Modelli Gemini.