API Gemini обеспечивает расширенную генерацию поиска (Retrieval Augmented Generation, RAG) с помощью инструмента поиска файлов. Поиск файлов импортирует, разбивает на фрагменты и индексирует ваши данные, обеспечивая быстрый поиск релевантной информации на основе предоставленного запроса. Полученная информация затем используется в качестве контекста для модели, позволяя ей предоставлять более точные и релевантные ответы. Поиск файлов также обеспечивает многомодальные возможности с поддержкой текстовых встраиваний gemini-embedding-001 и изображений/мультимодальных встраиваний ( gemini-embedding-2 .
Хранение файлов и генерация эмбеддингов во время запроса бесплатны, и вы платите только за создание эмбеддингов при первой индексации файлов и за стандартную стоимость входных/выходных токенов модели Gemini. Эта новая система оплаты делает инструмент поиска файлов проще и экономичнее в разработке и масштабировании. Подробности см. в разделе «Цены» .
Загрузка непосредственно в хранилище файлов с поиском файлов.
В этом примере показано, как напрямую загрузить файл в хранилище поиска файлов :
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.upload_to_file_search_store(
file='sample.txt',
file_search_store_name=file_search_store.name,
config={
'display_name' : 'display-file-name',
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
if content_block.annotations:
print("\nSources:")
for annotation in content_block.annotations:
if annotation.type == "file_citation":
print(f" - {annotation.file_name}: {annotation.source}")
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
if (contentBlock.annotations) {
console.log("\nSources:");
for (const annotation of contentBlock.annotations) {
if (annotation.type === 'file_citation') {
console.log(` - ${annotation.file_name}: ${annotation.source}`);
}
}
}
}
}
}
}
}
run();
Для получения более подробной информации ознакомьтесь со справочником API для uploadToFileSearchStore .
Импорт файлов
В качестве альтернативы вы можете загрузить существующий файл и импортировать его в свою файловую систему поиска :
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
sample_file = client.files.upload(file='sample.txt', config={'display_name': 'display_file_name'})
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const sampleFile = await ai.files.upload({
file: 'sample.txt',
config: { displayName: 'file-name' }
});
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation: operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
}
run();
Для получения более подробной информации обратитесь к справочнику API для importFile .
Настройка разбиения на блоки
При импорте файла в хранилище файлового поиска он автоматически разбивается на фрагменты, встраивается, индексируется и загружается в ваше хранилище файлового поиска. Если вам нужен больший контроль над стратегией разбиения на фрагменты, вы можете указать параметр chunking_config , чтобы задать максимальное количество токенов на фрагмент и максимальное количество перекрывающихся токенов.
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file='sample.txt',
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
print("Custom chunking complete.")
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
chunkingConfig: {
whiteSpaceConfig: {
maxTokensPerChunk: 200,
maxOverlapTokens: 20
}
}
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
console.log("Custom chunking complete.");
Чтобы использовать хранилище файлов, передайте его в качестве инструмента методу interactions.create , как показано в примерах загрузки и импорта .
Как это работает
Поиск файлов использует метод, называемый семантическим поиском, для нахождения информации, релевантной запросу пользователя. В отличие от стандартного поиска по ключевым словам, семантический поиск понимает смысл и контекст вашего запроса.
При импорте файла он преобразуется в числовые представления, называемые эмбеддингами , которые отражают семантическое значение загруженного контента. Эти эмбеддинги хранятся в специализированной базе данных поиска файлов. При выполнении запроса он также преобразуется в эмбеддинг. Затем система выполняет поиск файлов, чтобы найти наиболее похожие и релевантные фрагменты документов в хранилище результатов поиска файлов.
Для эмбеддингов нет параметра Time To Live (TTL); они сохраняются до тех пор, пока не будут удалены вручную или пока модель не будет признана устаревшей. Однако файлы удаляются через 48 часов.
Вот подробное описание процесса использования API ` uploadToFileSearchStore для поиска файлов:
Создайте хранилище для поиска по файлам : хранилище для поиска по файлам содержит обработанные данные из ваших файлов. Это постоянный контейнер для векторных представлений, с которыми будет работать семантический поиск.
Загрузка файла и импорт в хранилище File Search : Одновременно загрузите файл и импортируйте результаты в ваше хранилище File Search. Это создаст временный объект
File, который будет являться ссылкой на ваш исходный документ. Затем эти данные будут разбиты на фрагменты, преобразованы в векторные представления File Search и проиндексированы. ОбъектFileудаляется через 48 часов, а данные, импортированные в хранилище File Search, будут храниться неограниченно долго, пока вы не решите их удалить.Запрос с использованием поиска по файлам : Наконец, вы используете инструмент
FileSearchв вызовеgenerateContent. В конфигурации инструмента вы указываетеFileSearchRetrievalResource, который указывает на хранилищеFileSearchStore, в котором вы хотите выполнить поиск. Это указывает модели выполнить семантический поиск в этом конкретном хранилище FileSearchStore, чтобы найти релевантную информацию для обоснования своего ответа.
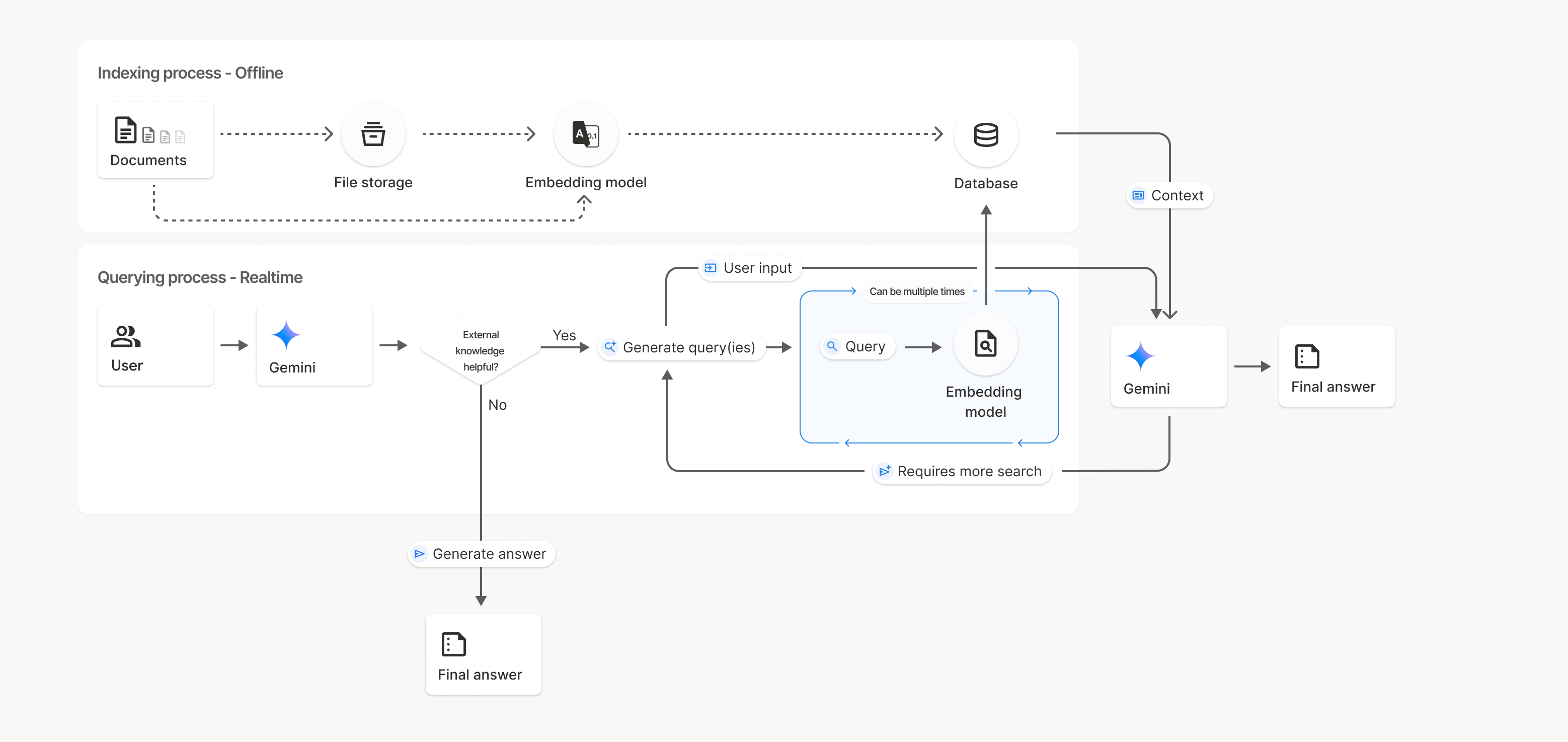
На этой диаграмме пунктирная линия от Documents к модели Embedding (с использованием gemini-embedding-001 ) представляет собой API uploadToFileSearchStore (в обход хранилища файлов ). В противном случае, использование API Files для отдельного создания и последующего импорта файлов перемещает процесс индексирования из Documents в хранилище файлов , а затем в модель Embedding .
Магазины поиска файлов
Хранилище поиска файлов — это контейнер для встраивания ваших документов. В то время как исходные файлы, загруженные через File API, удаляются через 48 часов, данные, импортированные в хранилище поиска файлов, хранятся неограниченно долго, пока вы не удалите их вручную. Вы можете создать несколько хранилищ поиска файлов для организации ваших документов. API FileSearchStore позволяет создавать, просматривать, получать и удалять хранилища поиска файлов для управления ими. Имена хранилищ поиска файлов имеют глобальную область видимости.
Вот несколько примеров того, как управлять хранилищами файлового поиска:
Python
file_search_store = client.file_search_stores.create(
config={
'display_name': 'my-file_search-store-123',
'embedding_model': 'models/gemini-embedding-2'
}
)
for file_search_store in client.file_search_stores.list():
print(file_search_store)
my_file_search_store = client.file_search_stores.get(name='fileSearchStores/my-file_search-store-123')
client.file_search_stores.delete(name='fileSearchStores/my-file_search-store-123', config={'force': True})
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'my-file_search-store-123',
embeddingModel: 'models/gemini-embedding-2'
}
});
const fileSearchStores = await ai.fileSearchStores.list();
for await (const store of fileSearchStores) {
console.log(store);
}
const myFileSearchStore = await ai.fileSearchStores.get({
name: 'fileSearchStores/my-file_search-store-123'
});
await ai.fileSearchStores.delete({
name: 'fileSearchStores/my-file_search-store-123',
config: { force: true }
});
ОТДЫХ
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "displayName": "My Store", "embedding_model": "models/gemini-embedding-2" }'
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
Поиск файлов документов
С помощью API поиска файлов по документам вы можете управлять отдельными документами в своих файловых хранилищах, получать list всех документов в хранилище поиска, get информацию о документе и delete документ по имени.
Python
for document_in_store in client.file_search_stores.documents.list(parent='fileSearchStores/my-file_search-store-123'):
print(document_in_store)
file_search_document = client.file_search_stores.documents.get(name='fileSearchStores/my-file_search-store-123/documents/my_doc')
print(file_search_document)
client.file_search_stores.documents.delete(name='fileSearchStores/my-file_search-store-123/documents/my_doc', config={'force': True})
JavaScript
const documents = await ai.fileSearchStores.documents.list({
parent: 'fileSearchStores/my-file_search-store-123'
});
for await (const doc of documents) {
console.log(doc);
}
const fileSearchDocument = await ai.fileSearchStores.documents.get({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
await ai.fileSearchStores.documents.delete({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
ОТДЫХ
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents?key=${GEMINI_API_KEY}"
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}&force=true"
Метаданные файла
Вы можете добавлять пользовательские метаданные к своим файлам, чтобы фильтровать их или предоставлять дополнительный контекст. Метаданные представляют собой набор пар «ключ-значение».
Python
op = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
config={
'custom_metadata': [
{"key": "author", "string_value": "Robert Graves"},
{"key": "year", "numeric_value": 1934}
]
}
)
JavaScript
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name,
config: {
customMetadata: [
{ key: "author", stringValue: "Robert Graves" },
{ key: "year", numericValue: 1934 }
]
}
});
Это полезно, когда у вас в хранилище поиска файлов находится несколько документов, и вы хотите выполнить поиск только в их подмножестве.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about the book 'I, Claudius'",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name],
"metadata_filter": 'author="Robert Graves"',
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about the book 'I, Claudius'",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
metadata_filter: 'author="Robert Graves"',
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
ОТДЫХ
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": [{"type": "text", "text": "Tell me about the book I, Claudius"}],
"tools": [{
"type": "file_search",
"file_search_store_names": ["'$STORE_NAME'"],
"metadata_filter": "author = \"Robert Graves\""
}]
}' 2> /dev/null > response.json
cat response.json
Инструкции по реализации синтаксиса фильтра списков для metadata_filter можно найти по адресу google.aip.dev/160
Мультимодальный поиск файлов
Функция Multimodal File Search позволяет встраивать изображения и осуществлять поиск по ним, что обеспечивает возможность создания многофункциональных многомодальных RAG-приложений.
Настройте модель встраивания.
При создании FileSearchStore необходимо переопределить модель встраивания только текста по умолчанию, чтобы использовать многомодальную модель. Используйте models/gemini-embedding-2 для обработки как текста, так и изображений.
Python
store = client.file_search_stores.create(
config={
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2",
}
)
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: "Multimodal Catalog",
embeddingModel: "models/gemini-embedding-2",
},
});
ОТДЫХ
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2"
}'
Загрузить изображения
После создания хранилища с мультимодальной моделью встраивания вы можете загружать файлы изображений напрямую, используя те же API загрузки, что описаны в разделах «Прямая загрузка в хранилище поиска файлов» или «Импорт файлов» .
Требования к файлу изображения:
- Разрешение файлов изображений не должно превышать 4K x 4K пикселей.
- Поддерживаемые форматы: PNG, JPEG.
Цитаты
При использовании поиска по файлу ответ модели может содержать ссылки, указывающие, какие части загруженных вами документов были использованы для получения ответа. Это помогает в проверке и подтверждении фактов.
Доступ к информации о цитировании можно получить через атрибут annotations внутри блоков content шага model_output в ответе.
Python
for step in interaction.steps:
if step.type == 'model_output':
for content in step.content:
if content.type == 'text' and content.annotations:
print(content.annotations)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text' && contentBlock.annotations) {
console.log(JSON.stringify(contentBlock.annotations, null, 2));
}
}
}
}
Подробную информацию о структуре цитирований см. в справочнике API для Interactions .
Номера страниц
При использовании поиска по файлу для документов, содержащих страницы (например, PDF-файлов), ответ модели может включать номер страницы, на которой была найдена информация. Вы можете получить доступ к этой информации через атрибут page_number аннотации file_citation .
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.page_number:
print(f"Cited Page: {annotation.page_number}")
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.pageNumber) {
console.log(`Cited Page: ${annotation.pageNumber}`);
}
}
}
}
}
}
Ссылки на публикации в СМИ
Когда модель ссылается на фрагмент изображения во время генерации, API возвращает аннотацию типа file_citation , содержащую media_id . Вы можете использовать этот ID для загрузки именно того фрагмента изображения, на который ссылалась модель. Этот media_id сохраняется между несколькими запросами поиска, что позволяет надежно получать одно и то же изображение или кэшировать его, используя этот ID.
Следующий фрагмент кода представляет собой пример шага REST-ответа:
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "product_image",
"media_id": "fileSearchStores/my-store-123/media/BlobId-456"
}
]
}
]
}
Приведенные ниже фрагменты кода демонстрируют, как получить media_id и загрузить медиафайл:
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.media_id:
print(f"Cited Media ID: {annotation.media_id}")
blob_content = client.file_search_stores.download_media(
media_id=annotation.media_id
)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.mediaId) {
console.log(`Cited Media ID: ${annotation.mediaId}`);
const blobContent = await ai.fileSearchStores.downloadMedia(annotation.mediaId);
}
}
}
}
}
}
ОТДЫХ
curl -X GET "https://generativelanguage.googleapis.com/v1/fileSearchStores/my-store-123/media/BlobId-456" \
-H "x-goog-api-key: $GEMINI_API_KEY"
Пользовательские метаданные
Если вы добавили пользовательские метаданные к своим файлам, вы можете получить к ним доступ в аннотациях ответа модели. Это полезно для передачи дополнительного контекста (например, URL-адресов, номеров страниц или авторов) из исходных документов в логику вашего приложения. Каждая аннотация цитирования типа file_citation содержит эти пользовательские метаданные.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.annotations:
for annotation in content_block.annotations:
print(annotation)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.annotations) {
contentBlock.annotations.forEach((annotation) => {
console.log(annotation);
});
}
}
}
}
ОТДЫХ
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"file_name": "...",
"source": "...",
"custom_metadata": [
{
"key": "author",
"string_value": "Robert Graves"
},
{
"key": "year",
"numeric_value": 1934
}
]
}
]
}
]
}
]
}
Структурированный вывод
Начиная с моделей Gemini 3, вы можете объединить инструмент поиска файлов со структурированным выводом .
Python
from pydantic import BaseModel, Field
class Money(BaseModel):
amount: str = Field(description="The numerical part of the amount.")
currency: str = Field(description="The currency of amount.")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the minimum hourly wage in Tokyo right now?",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}],
response_format={
"type": "text",
"mime_type": "application/json",
"schema": Money.model_json_schema()
},
)
result = Money.model_validate_json(interaction.output_text)
print(result)
JavaScript
import { z } from "zod";
const moneyJsonSchema = {
type: "object",
properties: {
amount: { type: "string", description: "The numerical part of the amount." },
currency: { type: "string", description: "The currency of amount." }
},
required: ["amount", "currency"]
};
const moneySchema = z.fromJSONSchema(moneyJsonSchema);
async function run() {
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "What is the minimum hourly wage in Tokyo right now?",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
}],
response_format: {
type: 'text',
mime_type: 'application/json',
schema: moneyJsonSchema
},
});
const result = moneySchema.parse(JSON.parse(interaction.output_text));
console.log(result);
}
run();
ОТДЫХ
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the minimum hourly wage in Tokyo right now?",
"tools": [{
"type": "file_search",
"file_search_store_names": ["$FILE_SEARCH_STORE_NAME"]
}],
"response_format": {
"type": "text",
"mime_type": "application/json",
"schema": {
"type": "object",
"properties": {
"amount": {"type": "string", "description": "The numerical part of the amount."},
"currency": {"type": "string", "description": "The currency of amount."}
},
"required": ["amount", "currency"]
}
}
}'
Поддерживаемые модели
Следующие модели поддерживают поиск файлов:
| Модель | Поиск файлов |
|---|---|
| Вспышка Gemini 3.5 | ✔️ |
| Gemini 3.1 Pro Preview | ✔️ |
| Фонарик Gemini 3.1 | ✔️ |
| Предварительный просмотр Gemini 3 Flash | ✔️ |
| Gemini 2.5 Pro | ✔️ |
| Фонарь Gemini 2.5 Flash-Lite | ✔️ |
Поддерживаемые комбинации инструментов
В моделях Gemini 3 поддерживается сочетание встроенных инструментов (например, поиска файлов) с пользовательскими инструментами (вызовом функций). Подробнее см. на странице, посвященной сочетаниям инструментов .
Поддерживаемые типы файлов
Функция поиска файлов поддерживает широкий спектр форматов файлов, перечисленных в следующих разделах.
Типы файлов приложений
-
application/dart -
application/ecmascript -
application/json -
application/ms-java -
application/msword -
application/pdf -
application/sql -
application/typescript -
application/vnd.curl -
application/vnd.dart -
application/vnd.ibm.secure-container -
application/vnd.jupyter -
application/vnd.ms-excel -
application/vnd.oasis.opendocument.text -
application/vnd.openxmlformats-officedocument.presentationml.presentation -
application/vnd.openxmlformats-officedocument.spreadsheetml.sheet -
application/vnd.openxmlformats-officedocument.wordprocessingml.document -
application/vnd.openxmlformats-officedocument.wordprocessingml.template -
application/x-csh -
application/x-hwp -
application/x-hwp-v5 -
application/x-latex -
application/x-php -
application/x-powershell -
application/x-sh -
application/x-shellscript -
application/x-tex -
application/x-zsh -
application/xml -
application/zip
Типы текстовых файлов
-
text/1d-interleaved-parityfec -
text/RED -
text/SGML -
text/cache-manifest -
text/calendar -
text/cql -
text/cql-extension -
text/cql-identifier -
text/css -
text/csv -
text/csv-schema -
text/dns -
text/encaprtp -
text/enriched -
text/example -
text/fhirpath -
text/flexfec -
text/fwdred -
text/gff3 -
text/grammar-ref-list -
text/hl7v2 -
text/html -
text/javascript -
text/jcr-cnd -
text/jsx -
text/markdown -
text/mizar -
text/n3 -
text/parameters -
text/parityfec -
text/php -
text/plain -
text/provenance-notation -
text/prs.fallenstein.rst -
text/prs.lines.tag -
text/prs.prop.logic -
text/raptorfec -
text/rfc822-headers -
text/rtf -
text/rtp-enc-aescm128 -
text/rtploopback -
text/rtx -
text/sgml -
text/shaclc -
text/shex -
text/spdx -
text/strings -
text/t140 -
text/tab-separated-values -
text/texmacs -
text/troff -
text/tsv -
text/tsx -
text/turtle -
text/ulpfec -
text/uri-list -
text/vcard -
text/vnd.DMClientScript -
text/vnd.IPTC.NITF -
text/vnd.IPTC.NewsML -
text/vnd.a -
text/vnd.abc -
text/vnd.ascii-art -
text/vnd.curl -
text/vnd.debian.copyright -
text/vnd.dvb.subtitle -
text/vnd.esmertec.theme-descriptor -
text/vnd.exchangeable -
text/vnd.familysearch.gedcom -
text/vnd.ficlab.flt -
text/vnd.fly -
text/vnd.fmi.flexstor -
text/vnd.gml -
text/vnd.graphviz -
text/vnd.hans -
text/vnd.hgl -
text/vnd.in3d.3dml -
text/vnd.in3d.spot -
text/vnd.latex-z -
text/vnd.motorola.reflex -
text/vnd.ms-mediapackage -
text/vnd.net2phone.commcenter.command -
text/vnd.radisys.msml-basic-layout -
text/vnd.senx.warpscript -
text/vnd.sosi -
text/vnd.sun.j2me.app-descriptor -
text/vnd.trolltech.linguist -
text/vnd.wap.si -
text/vnd.wap.sl -
text/vnd.wap.wml -
text/vnd.wap.wmlscript -
text/vtt -
text/wgsl -
text/x-asm -
text/x-bibtex -
text/x-boo -
text/xc -
text/x-c++hdr -
text/x-c++src -
text/x-cassandra -
text/x-chdr -
text/x-coffeescript -
text/x-component -
text/x-csh -
text/x-csharp -
text/x-csrc -
text/x-cuda -
text/xd -
text/x-diff -
text/x-dsrc -
text/x-emacs-lisp -
text/x-erlang -
text/x-gff3 -
text/x-go -
text/x-haskell -
text/x-java -
text/x-java-properties -
text/x-java-source -
text/x-kotlin -
text/x-lilypond -
text/x-lisp -
text/x-literate-haskell -
text/x-lua -
text/x-moc -
text/x-objcsrc -
text/x-pascal -
text/x-pcs-gcd -
text/x-perl -
text/x-perl-script -
text/x-python -
text/x-python-script -
text/xr-markdown -
text/x-rsrc -
text/x-rst -
text/x-ruby-script -
text/x-rust -
text/x-sass -
text/x-scala -
text/x-scheme -
text/x-script.python -
text/x-scss -
text/x-setext -
text/x-sfv -
text/x-sh -
text/x-siesta -
text/x-sos -
text/x-sql -
text/x-swift -
text/x-tcl -
text/x-tex -
text/x-vbasic -
text/x-vcalendar -
text/xml -
text/xml-dtd -
text/xml-external-parsed-entity -
text/yaml
Ограничения
- В Live API поиск файлов не поддерживается.
- Несовместимость инструментов: В настоящее время поиск файлов нельзя комбинировать с другими инструментами, такими как сопоставление с поиском Google , контекст URL и т. д.
Ограничения скорости
Для обеспечения стабильности работы API поиска файлов установлены следующие ограничения:
- Максимальный размер файла / ограничение на один документ : 100 МБ
- Общий размер хранилищ файлового поиска проекта (в зависимости от уровня пользователя):
- Бесплатно : 1 ГБ
- Уровень 1 : 10 ГБ
- Уровень 2 : 100 ГБ
- Уровень 3 : 1 ТБ
- Рекомендация : Ограничьте размер каждого хранилища результатов поиска файлов до 20 ГБ, чтобы обеспечить оптимальную задержку при извлечении данных.
Цены
- Оплата за эмбеддинги взимается во время индексирования на основе существующих тарифов на эмбеддинги .
- Хранение предоставляется бесплатно.
- Встраивание данных во время выполнения запроса предоставляется бесплатно.
- Полученные токены документа оплачиваются как обычные контекстные токены .
Что дальше?
- Для получения информации о хранилищах файлов и документах, полученных в результате поиска файлов, посетите справочник API.