Generación de imágenes con Nano Banana
- O bien, crea tu propia rutina a partir de instrucciones:
-








-
Generado por Nano Banana 2 Instrucción: "Una foto de la portada brillante de una revista. La portada azul minimalista tiene las palabras Nano Banana en letras grandes y negritas. El texto está en una fuente serif y llena la vista. No hay otro texto. Delante del texto, hay un retrato de una persona con un vestido elegante y minimalista. Ella sostiene de forma juguetona el número 2, que es el punto focal.
Coloca el número de problema y la fecha "Feb 2026" en la esquina junto con un código de barras. La revista está en un estante contra una pared de yeso naranja, dentro de una tienda de diseño". -
Generado por Nano Banana Pro Instrucción: "Presenta una escena de dibujos animados en 3D en miniatura isométrica clara y con vista superior a 45° de Londres, en la que se muestren sus monumentos y elementos arquitectónicos más emblemáticos. Usa texturas suaves y refinadas con materiales PBR realistas, y luces y sombras suaves y realistas. Integra las condiciones climáticas actuales directamente en el entorno de la ciudad para crear un ambiente atmosférico envolvente. Usa una composición limpia y minimalista con un fondo suave de color sólido. En la parte superior central, coloca el título "Londres" en texto grande y en negrita, un ícono del clima destacado debajo, luego la fecha (texto pequeño) y la temperatura (texto mediano). Todo el texto debe estar centrado con un espaciado uniforme y puede superponerse sutilmente con la parte superior de los edificios". -
Generado por Nano Banana 2 Instrucción: "Usa la búsqueda de imágenes para encontrar imágenes precisas de un quetzal resplandeciente. Crea un hermoso fondo de pantalla de 3:2 de este pájaro, con un degradado natural de arriba a abajo y una composición minimalista". -

Generado por Nano Banana Pro Instrucción: "Coloca este logotipo en un anuncio de alta gama de un perfume con aroma a banana. El logotipo está perfectamente integrado en la botella". -
Generado por Nano Banana Pro Mensaje: "Una foto de una escena cotidiana en una cafetería concurrida que sirve desayunos. En primer plano, se ve un hombre de anime con cabello azul. Una de las personas es un boceto a lápiz y otra es una persona de plastilina". -
Generado por Nano Banana Pro Instrucción: "Usa la búsqueda para averiguar cómo se recibió el lanzamiento de Gemini 3 Flash. Usa esta información para escribir un artículo breve sobre el tema (con encabezados). Devuelve una foto del artículo tal como apareció en una revista brillante centrada en el diseño. Es una foto de una sola página doblada, en la que se muestra el artículo sobre Gemini 3 Flash. Una foto principal El titular está en serif". -
Generado por Nano Banana Pro Instrucción: "Un ícono que representa un perro lindo. El fondo es blanco. Crea los íconos con un estilo 3D táctil y colorido. Sin texto". -
Generado por Nano Banana 2 Instrucción: "Crea una foto que sea perfectamente isométrica. No es una miniatura, sino una foto capturada que resultó ser perfectamente isométrica. Es una foto de un hermoso jardín moderno. Hay una piscina grande en forma de 2 y las palabras: Nano Banana 2".
Nano Banana es el nombre de las capacidades nativas de generación de imágenes de Gemini. Gemini puede generar y procesar imágenes de forma conversacional con texto, imágenes o una combinación de ambos. Esto te permite crear, editar y mejorar imágenes con un control sin precedentes.
Nano Banana hace referencia a cuatro modelos distintos disponibles en la API de Gemini:
- Nano Banana 2 Lite (Gemini 3.1 Flash Lite Image)
(
gemini-3.1-flash-lite-image): Es nuestro modelo de imagen de Gemini más rápido y económico, diseñado para la velocidad y la escala en los casos en que la velocidad y el costo son las principales limitaciones operativas. No está optimizado para múltiples entradas de referencia ni para la edición secuencial de varios turnos. - Nano Banana 2 (Gemini 3.1 Flash Image)
(
gemini-3.1-flash-image): Es el modelo más versátil y generalista para todas las tareas. Equilibra la velocidad con la generación de 4K de vanguardia, el conocimiento del mundo y la renderización de texto confiable. Excelente en el procesamiento y la coherencia de múltiples imágenes de referencia. - Nano Banana Pro (Imagen de Gemini 3 Pro) (
gemini-3-pro-image): Es la opción premium para las tareas visuales más complejas, ya que ofrece el nivel más alto de conocimiento del mundo, localización avanzada, coherencia precisa de la marca y control creativo de precisión. - Nano Banana (Gemini 2.5 Flash Image)
(
gemini-2.5-flash-image): Es el pionero heredado de la serie Nano Banana. Si bien ha sido una herramienta confiable, recomendamos a los clientes que migren a Nano Banana 2 Lite para disfrutar de una calidad mejorada, velocidades de generación más rápidas y precios de API más bajos.
Todas las imágenes generadas incluyen una marca de agua de SynthID.
Generación de imágenes (texto a imagen)
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme";
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}'
Puedes recuperar los datos de la imagen generada con la propiedad interaction.output_image, que devuelve el último bloque de imagen generado. Para obtener detalles sobre las propiedades de conveniencia, consulta la descripción general de las interacciones.
Edición de imágenes (de texto y de imagen a imagen)
Recordatorio: Asegúrate de tener los derechos necesarios de las imágenes que subas. No generes contenido que infrinja los derechos de otras personas, incluidos videos o imágenes que engañen, hostiguen o dañen. El uso de este servicio de IA generativa está sujeto a nuestra Política de Uso Prohibido.
Proporciona una imagen y usa instrucciones de texto para agregar, quitar o modificar elementos, cambiar el estilo o ajustar la corrección de color.
En el siguiente ejemplo, se muestra cómo subir imágenes codificadas en base64.
Para obtener información sobre varias imágenes, cargas útiles más grandes y tipos de MIME admitidos, consulta la página Comprensión de imágenes.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open("/path/to/cat_image.png", "rb") as f:
image_bytes = f.read()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "path/to/cat_image.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ type: "text", text: "Create a picture of my cat eating a nano-banana in a" +
"fancy restaurant under the Gemini constellation" },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation\"},
{
\"type\": \"image\",
\"mime_type\": \"image/jpeg\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
]
}"
Edición de imágenes de varios turnos
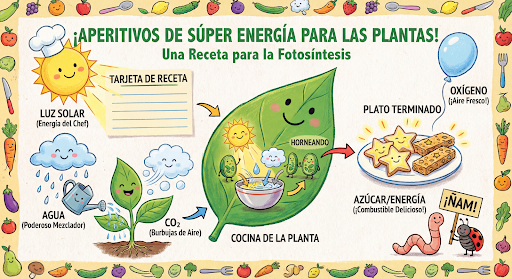
Sigue generando y editando imágenes de forma conversacional. La conversación de varios turnos es la forma recomendada de iterar imágenes. En el siguiente ejemplo, se muestra una instrucción para generar una infografía sobre la fotosíntesis.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools=[{"type": "google_search"}],
)
with open("photosynthesis.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const ai = new GoogleGenAI({});
async function main() {
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools: [{"type": "google_search"}],
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis.png", buffer);
console.log("Image saved as photosynthesis.png");
}
}
await main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plants favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids cookbook, suitable for a 4th grader."}
],
"tools": [{"type": "google_search"}]
}'

Luego, puedes usar previous_interaction_id para cambiar el idioma del gráfico a español.
Python
interaction_2 = client.interactions.create(
model="gemini-3.1-flash-image",
input="Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id=interaction.id,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
},
)
generated_image = interaction_2.output_image
if generated_image:
with open("photosynthesis_spanish.png", "wb") as f:
f.write(base64.b64decode(generated_image.data))
JavaScript
const interaction2 = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id: interaction.id,
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const generatedImage = interaction2.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis_spanish.png", buffer);
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Update this infographic to be in Spanish. Do not change any other elements of the image.",
"previous_interaction_id": "<PREVIOUS_INTERACTION_ID>",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
Novedades de los modelos de Gemini 3 Image
Gemini 3 ofrece modelos de vanguardia para la generación y edición de imágenes. Gemini 3.1 Flash Image está optimizado para la velocidad y los casos de uso de gran volumen, y Gemini 3 Pro Image está optimizado para la producción de recursos profesionales. Diseñadas para abordar los flujos de trabajo más desafiantes a través del razonamiento avanzado, se destacan en tareas complejas de creación y modificación de varios turnos.
- Salida de alta resolución: Capacidades de generación integradas para imágenes en 1K, 2K y 4K
- Gemini 3.1 Flash Image agrega la resolución más pequeña de 512 px (0.5 K).
- Gemini 3.1 Flash Lite Image solo admite una resolución de 1 K.
- Renderización de texto avanzada: Puede generar texto legible y estilizado para infografías, menús, diagramas y recursos de marketing.
- Fundamentación con la Búsqueda de Google: El modelo puede usar la Búsqueda de Google como herramienta para verificar hechos y generar imágenes basadas en datos en tiempo real (p.ej., mapas del clima actuales, gráficos de acciones, eventos recientes).
- No es compatible con el modelo Gemini 3.1 Flash Lite Image.
- Gemini 3.1 Flash Image agrega la integración de la fundamentación de la Búsqueda de imágenes de Google junto con la Búsqueda web.
- Modo de pensamiento: El modelo utiliza un proceso de "pensamiento" para razonar a través de instrucciones complejas. Genera "imágenes de pensamiento" provisorias (visibles en el backend, pero no se cobran) para definir la composición antes de producir el resultado final de alta calidad.
- Hasta 14 imágenes de referencia: Ahora puedes combinar hasta 14 imágenes de referencia para producir la imagen final.
- Nuevas relaciones de aspecto: Gemini 3.1 Flash Lite Image agrega las relaciones de aspecto
1:1,3:2,2:3,3:4,4:3,4:5,5:4,9:16,16:9y21:9.
Usa hasta 14 imágenes de referencia
Los modelos de imágenes de Gemini 3 te permiten combinar hasta 14 imágenes de referencia. Estas 14 imágenes pueden incluir lo siguiente:
| Imagen de Gemini 3.1 Flash Lite | Gemini 3.1 Flash Image | Gemini 3 Pro Image |
|---|---|---|
| Hasta 14 imágenes de objetos con alta fidelidad para incluir en la imagen final | Hasta 10 imágenes de objetos con alta fidelidad para incluir en la imagen final | Hasta 6 imágenes de objetos con alta fidelidad para incluir en la imagen final |
| N/A | Hasta 4 imágenes de personajes para mantener la coherencia | Hasta 5 imágenes de personajes para mantener la coherencia de los personajes |
| N/A | N/A | Hasta 3 imágenes para usar como referencias de estilo |
Python
from google import genai
from google.genai import types
from PIL import Image
import base64
prompt = "An office group photo of these people, they are making funny faces."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": prompt,
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
],
response_format={
"type": "image",
"aspect_ratio": "5:4",
"image_size": "2K"
},
)
with open("office.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const input = [
{
type: "text",
text: "An office group photo of these people, they are making funny faces.",
},
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile1 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile2 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile3 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile4 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile5 },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
response_format: {
type: "image",
aspect_ratio: "5:4",
image_size: "2K",
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('office.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"An office group photo of these people, they are making funny faces.\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_1>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_2>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_3>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_4>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_5>\"}
],
\"response_format\": {
\"type\": \"image\",
\"aspect_ratio\": \"5:4\",
\"image_size\": \"2K\"
}
}"

Fundamentación con la Búsqueda de Google
Usa la herramienta de Búsqueda de Google para generar imágenes basadas en información en tiempo real, como pronósticos del clima, gráficos de acciones o eventos recientes.
Ten en cuenta que, cuando se usa la fundamentación con la Búsqueda de Google para generar imágenes, los resultados de la búsqueda basados en imágenes no se pasan al modelo de generación y se excluyen de la respuesta (consulta Fundamentación con Google Imágenes).
Python
from google import genai
from google.genai import types
import base64
prompt = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
tools=[{"type": "google_search"}],
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
},
)
with open("weather.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day",
tools: [{"type": "google_search"}],
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('weather.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"}
],
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
}
}'

La respuesta incluye los pasos google_search_call y google_search_result, junto con anotaciones intercaladas url_citation en el paso de texto:
google_search_result: Contienesearch_suggestions, un fragmento de HTML para renderizar sugerencias de búsqueda en tu IU.- Anotaciones
url_citation: Citas intercaladas en el paso de texto que vinculan partes de la respuesta a sus fuentes web.
Fundamentación con la Búsqueda de Google para imágenes (3.1 Flash)
La fundamentación con la Búsqueda con imágenes de Google permite que los modelos usen imágenes web recuperadas a través de la Búsqueda con imágenes de Google como contexto visual para la generación de imágenes. La Búsqueda de imágenes es un nuevo tipo de búsqueda dentro de la herramienta existente Fundamentación con la Búsqueda de Google, que funciona junto con la Búsqueda web estándar.
Para habilitar la Búsqueda de imágenes, configura la herramienta google_search en tu solicitud de API y especifica image_search dentro del array search_types. La Búsqueda con imágenes se puede usar de forma independiente o junto con la Búsqueda web.
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A detailed painting of a Timareta butterfly resting on a flower",
tools=[{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
)
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A detailed painting of a Timareta butterfly resting on a flower",
tools: [{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
});
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A detailed painting of a Timareta butterfly resting on a flower",
"tools": [{"type": "google_search", "search_types": ["web_search", "image_search"]}]
}'
Requisitos de visualización
Cuando usas la Búsqueda de imágenes en la Fundamentación con la Búsqueda de Google, debes mostrar el search_suggestions del paso google_search_result. Los requisitos de uso completos se detallan en las Condiciones del Servicio.
Respuesta
En el caso de las respuestas fundamentadas que usan la búsqueda de imágenes, la API devuelve citas intercaladas y metadatos de atribución como parte de los pasos de la respuesta:
Anotaciones de
url_citation: Citas intercaladas en el bloque de contenido de texto dentro demodel_output, que vinculan el contenido generado a su fuente.google_search_result: Contienesearch_suggestions, un fragmento de HTML para renderizar sugerencias de búsqueda en tu IU.
Generación de video a imagen (3.1 Flash)
La generación de imágenes a partir de videos te permite crear imágenes nuevas usando el contexto de un video como referencia multimodal. Esto es útil para crear miniaturas de videos de alta calidad, pósters cinematográficos, infografías de resumen o ilustraciones nuevas inspiradas en una escena de video.
Durante la generación, el modelo analiza los fotogramas del video en contexto para extraer temas visuales y eventos clave, y luego los usa junto con tu instrucción de texto para sintetizar la imagen de salida.
Puedes pasar URLs de YouTube públicas directamente en tu solicitud de API o subir archivos de video locales con la API de Files.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{"type": "text", "text": "Generate a poster image that captures the key themes of this video."}
],
response_format={"type": "image", "aspect_ratio": "16:9"}
)
# Save the generated image part
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("video_poster.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
print("Image saved as video_poster.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "video",
uri: "https://www.youtube.com/watch?v=UTdfxFyOQTI",
mime_type: "video/mp4"
},
{ type: "text", text: "Generate a poster image that captures the key themes of this video." }
],
response_format: {
type: "image",
aspect_ratio: "16:9"
}
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("video_poster.png", buffer);
console.log("Image saved as video_poster.png");
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{
"type": "text",
"text": "Generate a poster image that captures the key themes of this video."
}
],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

Genera imágenes con una resolución de hasta 4K
Los modelos de imagen de Gemini 3 generan 1,000 imágenes de forma predeterminada, pero también pueden generar imágenes de 2K, 4K y 512 px (05.K) (solo Gemini 3.1 Flash Image). Para generar recursos con una resolución más alta, especifica image_size en response_format.
Debes usar una "K" en mayúscula (p.ej., 512 px (05.K), 1K, 2K, 4K). Se rechazarán los parámetros en minúsculas (p.ej., 1k).
Python
from google import genai
from google.genai import types
import base64
prompt = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
},
)
print(interaction.output_text)
with open("butterfly.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "1:1",
image_size: "1K",
},
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('butterfly.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
}
}'
La siguiente es una imagen de ejemplo generada a partir de esta instrucción:

Proceso de pensamiento
Los modelos de imágenes de Gemini 3 son modelos de razonamiento que usan un proceso de razonamiento ("Pensar") para instrucciones complejas. Esta función está habilitada de forma predeterminada y no se puede inhabilitar en la API. Para obtener más información sobre el proceso de pensamiento, consulta la guía Gemini Thinking.
El modelo genera hasta dos imágenes provisionales para probar la composición y la lógica. La última imagen dentro de Thinking también es la imagen renderizada final.
Puedes consultar las ideas que llevaron a la producción de la imagen final.
Python
for step in interaction.steps:
if step.type == "thought":
for content_block in step.summary:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
image = Image.open(io.BytesIO(base64.b64decode(content_block.data)))
image.show()
JavaScript
for (const step of interaction.steps) {
if (step.type === "thought") {
for (const contentBlock of step.summary) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, 'base64');
fs.writeFileSync('thought_image.png', buffer);
}
}
}
}
Imágenes y texto intercalado
Si bien los modelos estándar de generación de imágenes solo producen imágenes, algunos modelos avanzados de Gemini 3 (como gemini-3-pro-image) pueden generar contenido intercalado, como historias o guías instructivas que contienen bloques de texto e ilustraciones en la misma respuesta.
Dado que el resultado es complejo y está intercalado, las propiedades de conveniencia como .output_image o .output_text no capturarán la secuencia completa. Para acceder al contenido intercalado y guardarlo, debes iterar manualmente sobre steps:
Python
interaction = client.interactions.create(
model="gemini-3-pro-image",
input="Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
)
image_counter = 1
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
filename = f"butterfly_lifecycle_{image_counter}.png"
with open(filename, "wb") as f:
f.write(base64.b64decode(content_block.data))
print(f"\n[Saved illustration: {filename}]\n")
image_counter += 1
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3-pro-image",
input: "Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
});
let imageCounter = 1;
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
const filename = `butterfly_lifecycle_${imageCounter}.png`;
fs.writeFileSync(filename, buffer);
console.log(`\n[Saved illustration: ${filename}]\n`);
imageCounter++;
}
}
}
}
Cómo controlar los niveles de pensamiento
Con Gemini 3.1 Flash Image, puedes controlar la cantidad de razonamiento que usa el modelo para equilibrar la calidad y la latencia. El valor predeterminado de thinking_level es minimal, y los niveles admitidos son minimal y high.
Python
from google import genai
from PIL import Image
import base64
import io
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A futuristic city built inside a giant glass bottle floating in space",
generation_config={"thinking_level": "high"},
)
print(interaction.output_text)
image = Image.open(io.BytesIO(base64.b64decode(interaction.output_image.data)))
image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A futuristic city built inside a giant glass bottle floating in space",
generation_config: { thinking_level: "high" },
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('image.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A futuristic city built inside a giant glass bottle floating in space",
"generation_config": {
"thinking_level": "high"
}
}'
Ten en cuenta que los tokens de pensamiento se facturan de forma predeterminada para los modelos de pensamiento, ya que el proceso de pensamiento siempre se produce de forma predeterminada, ya sea que veas el proceso o no.
Otros modos de generación de imágenes
Si bien los modelos de generación de imágenes de Nano Banana se recomiendan para la mayoría de los casos de uso, también puedes explorar modelos de generación de imágenes específicos:
- Imagen: Son los modelos de texto a imagen de Google optimizados para generar imágenes de alta calidad.
- Veo: Es el modelo de generación de videos de Google.
Genera imágenes por lotes
Todas las capacidades de generación de imágenes que se describen en esta página también se pueden ejecutar como trabajos por lotes con la API de Batch, que es ideal si necesitas generar muchas imágenes.Obtendrás límites de frecuencia más altos a cambio de un tiempo de respuesta de hasta 24 horas.
Guía y estrategias de instrucciones
En esta sección, se proporcionan ejemplos de instrucciones y plantillas para flujos de trabajo comunes de generación y edición de imágenes. Cada ejemplo incluye una plantilla reutilizable y un ejemplo de mensaje para la API de Interactions.
Instrucciones para generar imágenes
En los siguientes ejemplos, se muestra cómo usar instrucciones de texto para generar varios tipos de imágenes.
1. Escenas fotorrealistas
Describe una escena con muchos detalles. Cuanto más específica sea la instrucción, mayor control tendrás sobre los resultados.
Plantilla
A photorealistic [type of shot] of a [subject description] in a [setting
description]. [Description of the light]. Shot from a [camera angle]
with a [lens type].
Instrucción
A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format=[
{
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
}
],
)
print(interaction.output_text)
with open("coral_reef.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format: [
{
type: "image",
mime_type: "image/jpeg",
aspect_ratio: "16:9",
}
],
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('coral_reef.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
"response_format": {
"type": "image",
"mime_type": "image/png",
"aspect_ratio": "16:9"
}
}'

2. Ilustraciones y calcomanías estilizadas
Describe el estilo artístico, el tema y el medio. Sé específico sobre los detalles visuales (líneas en negrita, colores, etcétera) para obtener resultados coherentes.
Plantilla
A [style] of a [subject, with details about accessories or actions]
doing [activity]. The design features [visual qualities, e.g., bold outlines,
cel-shading, etc.] and [color/background preference].
Instrucción
A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("red_panda_sticker.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("red_panda_sticker.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It is munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white."
}'

3. Texto preciso en imágenes
Gemini se destaca en el procesamiento de texto. Sé claro sobre el texto, el estilo de la fuente (de forma descriptiva) y el diseño general. Usa Gemini 3 Pro Image para la producción de recursos profesionales.
Plantilla
Create a [image type] for [brand/concept] with the text "[text to render]"
in a [font style]. The design should be [style description], with a
[color scheme].
Instrucción
Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format={"type": "image", "aspect_ratio": "1:1"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("logo_example.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format: { type: "image", aspect_ratio: "1:1" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("logo_example.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a modern, minimalist logo for a coffee shop called The Daily Grind. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
"response_format": {
"type": "image",
"aspect_ratio": "1:1"
}
}'
4. Simulaciones de productos y fotografía comercial
Es ideal para crear fotos de productos limpias y profesionales para el comercio electrónico, la publicidad o la marca.
Plantilla
A high-resolution, studio-lit product photograph of a [product description]
on a [background surface/description]. The lighting is a [lighting setup,
e.g., three-point softbox setup] to [lighting purpose]. The camera angle is
a [angle type] to showcase [specific feature]. Ultra-realistic, with sharp
focus on [key detail]. [Aspect ratio].
Instrucción
A high-resolution, studio-lit product photograph of a minimalist ceramic
coffee mug in matte black, presented on a polished concrete surface. The
lighting is a three-point softbox setup designed to create soft, diffused
highlights and eliminate harsh shadows. The camera angle is a slightly
elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with
sharp focus on the steam rising from the coffee. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("product_mockup.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("product_mockup.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image."
}'

5. Diseño minimalista y de espacio negativo
Es excelente para crear fondos para sitios web, presentaciones o materiales de marketing en los que se superpondrá texto.
Plantilla
A minimalist composition featuring a single [subject] positioned in the
[bottom-right/top-left/etc.] of the frame. The background is a vast, empty
[color] canvas, creating significant negative space. Soft, subtle lighting.
[Aspect ratio].
Instrucción
A minimalist composition featuring a single, delicate red maple leaf
positioned in the bottom-right of the frame. The background is a vast, empty
off-white canvas, creating significant negative space for text. Soft,
diffused lighting from the top left. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("minimalist_design.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("minimalist_design.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image."
}'

6. Arte secuencial (panel de cómic o storyboard)
Se basa en la coherencia del personaje y la descripción de la escena para crear paneles de narración visual. Para obtener precisión con el texto y capacidad de narración, estas instrucciones funcionan mejor con Gemini 3 Pro y Gemini 3.1 Flash Image.
Plantilla
Make a 3 panel comic in a [style]. Put the character in a [type of scene].
Instrucción
Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/jpeg"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("comic_panel.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/man_in_white_glasses.jpg";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene." },
{
type: "image",
mime_type: "image/jpeg",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("comic_panel.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."},
{"type": "image", "data": "<BASE64_IMAGE_DATA>", "mime_type": "image/jpeg"}
]
}'
Entrada |
Salida |

|

|
7. Fundamentación con la Búsqueda de Google
Usar la Búsqueda de Google para generar imágenes basadas en información reciente o en tiempo real Esto es útil para noticias, el clima y otros temas urgentes.
Instrucción
Make a simple but stylish graphic of last night's Arsenal game in the Champion's League
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools=[{"type": "google_search"}],
response_format={"type": "image", "aspect_ratio": "16:9"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("football-score.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools: [{ type: "google_search" }],
response_format: { type: "image", aspect_ratio: "16:9", image_size: "2K" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("football-score.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Make a simple but stylish graphic of last nights Arsenal game in the Champions League",
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

Instrucciones para editar imágenes
En estos ejemplos, se muestra cómo proporcionar imágenes junto con tus instrucciones de texto para la edición, la composición y la transferencia de estilo.
1. Cómo agregar y quitar elementos
Proporciona una imagen y describe el cambio. El modelo coincidirá con el estilo, la iluminación y la perspectiva de la imagen original.
Plantilla
Using the provided image of [subject], please [add/remove/modify] [element]
to/from the scene. Ensure the change is [description of how the change should
integrate].
Instrucción
"Using the provided image of my cat, please add a small, knitted wizard hat
on its head. Make it look like it's sitting comfortably and matches the soft
lighting of the photo."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/cat_photo.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("cat_with_hat.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/cat_photo.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off." },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("cat_with_hat.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off.\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"}
]
}"
Entrada |
Salida |

|

|
2. Reconstrucción (máscara semántica)
Define de forma conversacional una "máscara" para editar una parte específica de una imagen y dejar el resto intacto.
Plantilla
Using the provided image, change only the [specific element] to [new
element/description]. Keep everything else in the image exactly the same,
preserving the original style, lighting, and composition.
Instrucción
"Using the provided image of a living room, change only the blue sofa to be
a vintage, brown leather chesterfield sofa. Keep the rest of the room,
including the pillows on the sofa and the lighting, unchanged."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/living_room.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("living_room_edited.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/living_room.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("living_room_edited.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged.\"}
]
}"
Entrada |
Salida |

|

|
3. Transferencia de estilo
Proporciona una imagen y pídele al modelo que recree su contenido con un estilo artístico diferente.
Plantilla
Transform the provided photograph of [subject] into the artistic style of [artist/art style]. Preserve the original composition but render it with [description of stylistic elements].
Instrucción
"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/city.png', 'rb') as f:
image_bytes = f.read()
text_input = """Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("city_style_transfer.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imageData = fs.readFileSync("/path/to/your/city.png");
const base64Image = imageData.toString("base64");
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows." },
],
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("city_style_transfer.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows.\"}
]
}"
Entrada |
Salida |

|

|
4. Composición avanzada: Combinación de varias imágenes
Proporciona varias imágenes como contexto para crear una escena compuesta nueva. Es ideal para simulaciones de productos o collages creativos.
Plantilla
Create a new image by combining the elements from the provided images. Take
the [element from image 1] and place it with/on the [element from image 2].
The final image should be a [description of the final scene].
Instrucción
"Create a professional e-commerce fashion photo. Take the blue floral dress
from the first image and let the woman from the second image wear it.
Generate a realistic, full-body shot of the woman wearing the dress, with
the lighting and shadows adjusted to match the outdoor environment."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/dress.png', 'rb') as f:
dress_bytes = f.read()
with open('/path/to/your/model.png', 'rb') as f:
model_bytes = f.read()
text_input = """Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(dress_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(model_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("fashion_ecommerce_shot.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/dress.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/model.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image1
},
{
type: "image",
mime_type: "image/png",
data: base64Image2
},
{ type: "text", text: "Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("fashion_ecommerce_shot.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment.\"}
}]
}"
Entrada 1 |
Entrada 2 |
Salida |

|

|

|
5. Conservación de detalles de alta fidelidad
Para asegurarte de que se conserven los detalles importantes (como un rostro o un logotipo) durante la edición, descríbelos con mucho detalle junto con tu solicitud de edición.
Plantilla
Using the provided images, place [element from image 2] onto [element from
image 1]. Ensure that the features of [element from image 1] remain
completely unchanged. The added element should [description of how the
element should integrate].
Instrucción
"Take the first image of the woman with brown hair, blue eyes, and a neutral
expression. Add the logo from the second image onto her black t-shirt.
Ensure the woman's face and features remain completely unchanged. The logo
should look like it's naturally printed on the fabric, following the folds
of the shirt."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/woman.png', 'rb') as f:
woman_bytes = f.read()
with open('/path/to/your/logo.png', 'rb') as f:
logo_bytes = f.read()
text_input = """Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(woman_bytes).decode('utf-8')},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(logo_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("woman_with_logo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/woman.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/logo.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image1},
{"type": "image", "mime_type":"image/png", "data": base64Image2},
{"type": "text", "text": "Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("woman_with_logo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt.\"}
]
}"
Entrada 1 |
Entrada 2 |
Salida |

|
|
|
6. Darle vida a algo
Sube un boceto o dibujo aproximado y pídele al modelo que lo refine hasta convertirlo en una imagen terminada.
Plantilla
Turn this rough [medium] sketch of a [subject] into a [style description]
photo. Keep the [specific features] from the sketch but add [new details/materials].
Instrucción
"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/car_sketch.png', 'rb') as f:
sketch_bytes = f.read()
text_input = """Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(sketch_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("car_photo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/car_sketch.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image},
{"type": "text", "text": "Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("car_photo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting.\"}
]
}"
Entrada |
Salida |

|

|
7. Coherencia de personajes: vista de 360°
Puedes generar vistas de 360 grados de un personaje solicitando ángulos diferentes de forma iterativa. Para obtener mejores resultados, incluye imágenes generadas anteriormente en las instrucciones posteriores para mantener la coherencia. Para las poses complejas, incluye una imagen de referencia de la pose seleccionada.
Plantilla
A studio portrait of [person] against [background], [looking forward/in profile looking right/etc.]
Instrucción
A studio portrait of this man against white, in profile looking right
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = """A studio portrait of this man against white, in profile looking right"""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input={
{"type": "text", "text": text_input},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(image_bytes).decode('utf-8')}
},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("man_right_profile.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
Entrada |
Salida 1 |
Resultado 2 |
|
|

|

|
Prácticas recomendadas
Para mejorar tus resultados, incorpora estas estrategias profesionales en tu flujo de trabajo.
- Sé hiperespecífico: Cuantos más detalles proporciones, mayor será el control que tendrás. En lugar de "armadura de fantasía", descríbela: "armadura de placas élfica ornamentada, grabada con patrones de hojas plateadas, con un cuello alto y hombreras con forma de alas de halcón".
- Proporciona contexto y la intención: Explica el propósito de la imagen. La comprensión del contexto por parte del modelo influirá en el resultado final. Por ejemplo, "Crea un logotipo para una marca de cuidado de la piel minimalista y de alta gama" generará mejores resultados que solo "Crea un logotipo".
- Itera y define mejor: No esperes obtener una imagen perfecta en el primer intento. Usa la naturaleza conversacional del modelo para realizar pequeños cambios. Puedes hacer un seguimiento con instrucciones como "Eso es genial, pero ¿puedes hacer que la iluminación sea un poco más cálida?" o "Mantén todo igual, pero cambia la expresión del personaje para que sea más seria".
- Usa instrucciones paso a paso: Para escenas complejas con muchos elementos, divide la instrucción en pasos. "Primero, crea un fondo de un bosque sereno y brumoso al amanecer. Luego, en primer plano, agrega un antiguo altar de piedra cubierto de musgo. Por último, coloca una sola espada brillante sobre el altar".
- Usa "instrucciones negativas semánticas": En lugar de decir "sin autos", describe la escena deseada de forma positiva: "una calle vacía y desierta sin señales de tráfico".
- Controla la cámara: Usa el lenguaje fotográfico y cinematográfico para controlar la composición. Términos como
wide-angle shot,macro shotylow-angle perspective.
Limitaciones
- Para obtener el mejor rendimiento, usa los siguientes idiomas: EN, ar-EG, de-DE, es-MX, fr-FR, hi-IN, id-ID, it-IT, ja-JP, ko-KR, pt-BR, ru-RU, ua-UA, vi-VN y zh-CN.
- La generación de imágenes no admite entradas de audio. Las entradas de video solo se admiten en Gemini 3.1 Flash Image.
- El modelo no siempre seguirá la cantidad exacta de imágenes que el usuario solicite explícitamente.
gemini-2.5-flash-imagefunciona mejor con hasta 3 imágenes como entrada, mientras quegemini-3-pro-imageadmite 5 imágenes con alta fidelidad y hasta 14 imágenes en total.gemini-3.1-flash-imageadmite la similitud de caracteres de hasta 4 caracteres y la fidelidad de hasta 10 objetos en un solo flujo de trabajo.- Cuando generas texto para una imagen, Gemini funciona mejor si primero generas el texto y, luego, pides una imagen con el texto.
gemini-3.1-flash-imagePor el momento, la fundamentación con la Búsqueda de Google no admite el uso de imágenes de personas del mundo real obtenidas de la búsqueda web.- Todas las imágenes generadas incluyen una marca de agua de SynthID.
Configuración opcional
De manera opcional, puedes configurar el formato de salida, la relación de aspecto y el tamaño de la imagen con el parámetro response_format.
Formato de salida
De forma predeterminada, el modelo devuelve respuestas de texto y de imagen. Puedes configurar la respuesta para que solo muestre las imágenes generadas (omitiendo el texto conversacional) especificando un formato de imagen en el parámetro response_format.
Para solicitar varias modalidades (por ejemplo, texto y la imagen generada), pasa un array de entradas de formato a response_format.
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Write a short poem about a starry night and generate an image of it.",
response_format=[
{"type": "text"},
{"type": "image"},
],
)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Write a short poem about a starry night and generate an image of it.",
response_format: [
{ type: "text" },
{ type: "image" },
],
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Write a short poem about a starry night and generate an image of it.",
"response_format": [
{ "type": "text" },
{ "type": "image" }
]
}'
Relaciones de aspecto y tamaño de la imagen
De forma predeterminada, el modelo hace coincidir el tamaño de la imagen de salida con el de la imagen de entrada o, de lo contrario, genera cuadrados de 1:1. Puedes controlar la proporción de aspecto y el tamaño de la imagen de salida con los campos aspect_ratio y image_size en response_format cuando type se establece en "image".
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K",
},
)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
response_format: {
type: "image",
aspect_ratio: "16:9",
image_size: "2K",
},
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
"response_format": {
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
En las siguientes tablas, se indican las diferentes proporciones disponibles y el tamaño de la imagen generada:
3.1 Flash Image
| Relación de aspecto | Resolución de 512 px | 500 tokens | Resolución 1K | 1,000 tokens | Resolución 2K | 2,000 tokens | Resolución 4K | Tokens 4K |
|---|---|---|---|---|---|---|---|---|
| 1:1 | 512 x 512 | 747 | 1024x1024 | 1120 | 2048x2048 | 1120 | 4096 x 4096 | 2000 |
| 1:4 | 256 x 1,024 | 747 | 512 x 2,048 | 1120 | 1024 x 4096 | 1120 | 2,048 x 8,192 | 2000 |
| 1:8 | 192 x 1536 | 747 | 384 × 3,072 | 1120 | 768 x 6,144 | 1120 | 1536 x 12288 | 2000 |
| 2:3 | 424 x 632 | 747 | 848 x 1264 | 1120 | 1696 x 2528 | 1120 | 3392 x 5056 | 2000 |
| 3:2 | 632 x 424 | 747 | 1264 x 848 | 1120 | 2528 x 1696 | 1120 | 5056 x 3392 | 2000 |
| 3:4 | 448 x 600 | 747 | 896 x 1200 | 1120 | 1792 x 2400 | 1120 | 3584 × 4800 | 2000 |
| 4:1 | 1024 x 256 | 747 | 2048 x 512 | 1120 | 4096 x 1024 | 1120 | 8192 x 2048 | 2000 |
| 4:3 | 600 x 448 | 747 | 1200 × 896 | 1120 | 2400 x 1792 | 1120 | 4800 x 3584 | 2000 |
| 4:5 | 464 x 576 | 747 | 928 × 1,152 | 1120 | 1856 x 2304 | 1120 | 3712 x 4608 | 2000 |
| 5:4 | 576 x 464 | 747 | 1152 x 928 | 1120 | 2304 x 1856 | 1120 | 4608 x 3712 | 2000 |
| 8:1 | 1536 x 192 | 747 | 3072 x 384 | 1120 | 6144 × 768 | 1120 | 12288 × 1536 | 2000 |
| 9:16 | 384 × 688 | 747 | 768 × 1,376 | 1120 | 1536 x 2752 | 1120 | 3072 x 5504 | 2000 |
| 16:9 | 688 × 384 | 747 | 1376 × 768 | 1120 | 2752 x 1536 | 1120 | 5504 x 3072 | 2000 |
| 21:9 | 792 x 168 | 747 | 1584 x 672 | 1120 | 3168 x 1344 | 1120 | 6336 x 2688 | 2000 |
3.1 Pro Image
| Relación de aspecto | Resolución 1K | 1,000 tokens | Resolución 2K | 2,000 tokens | Resolución 4K | Tokens 4K |
|---|---|---|---|---|---|---|
| 1:1 | 1024x1024 | 1120 | 2048x2048 | 1120 | 4096 x 4096 | 2000 |
| 2:3 | 848 x 1264 | 1120 | 1696 x 2528 | 1120 | 3392 x 5056 | 2000 |
| 3:2 | 1264 x 848 | 1120 | 2528 x 1696 | 1120 | 5056 x 3392 | 2000 |
| 3:4 | 896 x 1200 | 1120 | 1792 x 2400 | 1120 | 3584 × 4800 | 2000 |
| 4:3 | 1200 × 896 | 1120 | 2400 x 1792 | 1120 | 4800 x 3584 | 2000 |
| 4:5 | 928 × 1,152 | 1120 | 1856 x 2304 | 1120 | 3712 x 4608 | 2000 |
| 5:4 | 1152 x 928 | 1120 | 2304 x 1856 | 1120 | 4608 x 3712 | 2000 |
| 9:16 | 768 × 1,376 | 1120 | 1536 x 2752 | 1120 | 3072 x 5504 | 2000 |
| 16:9 | 1376 × 768 | 1120 | 2752 x 1536 | 1120 | 5504 x 3072 | 2000 |
| 21:9 | 1584 x 672 | 1120 | 3168 x 1344 | 1120 | 6336 x 2688 | 2000 |
Gemini 2.5 Flash Image
| Relación de aspecto | Solución | Tokens |
|---|---|---|
| 1:1 | 1024x1024 | 1290 |
| 2:3 | 832 x 1248 | 1290 |
| 3:2 | 1248 × 832 | 1290 |
| 3:4 | 864 x 1184 | 1290 |
| 4:3 | 1184 × 864 | 1290 |
| 4:5 | 896 × 1,152 | 1290 |
| 5:4 | 1152 × 896 | 1290 |
| 9:16 | 768 × 1,344 | 1290 |
| 16:9 | 1344 x 768 | 1290 |
| 21:9 | 1536 × 672 | 1290 |
Selección del modelo
Elige el modelo que mejor se adapte a tu caso de uso específico.
Gemini 3.1 Flash Image (Nano Banana 2) debería ser tu modelo de generación de imágenes de referencia, ya que ofrece el mejor rendimiento general y el mejor equilibrio entre inteligencia, costo y latencia. Consulta la página de precios y capacidades del modelo para obtener más detalles.
Gemini 3.1 Flash Lite Image (Nano Banana 2 Lite) es el modelo más eficiente de la familia de generación de imágenes, ya que ofrece una latencia ultrabaja y una generación y edición de imágenes rentables. Consulta la página de precios y capacidades del modelo para obtener más detalles.
Gemini 3 Pro Image (Nano Banana Pro) está diseñado para la producción de recursos profesionales y las instrucciones complejas. Este modelo incluye fundamentación en el mundo real con la Búsqueda de Google, un proceso predeterminado de "pensamiento" que refina la composición antes de la generación y puede generar imágenes con resoluciones de hasta 4K. Consulta la página de precios y capacidades del modelo para obtener más detalles.
Gemini 2.5 Flash Image (Nano Banana) está diseñado para brindar velocidad y eficiencia. Este modelo está optimizado para tareas de alto volumen y baja latencia, y genera imágenes con una resolución de 1,024 px. Consulta la página de precios y capacidades del modelo para obtener más detalles.
Cuándo usar Imagen
Además de usar las funciones integradas de generación de imágenes de Gemini, también puedes acceder a Imagen, nuestro modelo especializado de generación de imágenes, a través de la API de Gemini. Planifica la migración antes de la fecha de cierre.
¿Qué sigue?
- Consulta la guía de Veo para aprender a generar videos con la API de Gemini.
- Para obtener más información sobre los modelos de Gemini, consulta Modelos de Gemini.