
Strategi desain perintah seperti perintah singkat mungkin tidak selalu menghasilkan hasil yang Anda butuhkan. Fine-tuning adalah proses yang dapat meningkatkan kualitas performa pada tugas tertentu atau membantu model mematuhi output tertentu persyaratan, saat petunjuk tidak memadai, dan Anda memiliki banyak contoh yang menunjukkan {i>output<i} yang Anda inginkan.
Halaman ini memberikan ringkasan konseptual tentang cara menyesuaikan model teks di balik layanan teks Gemini API. Jika Anda sudah siap untuk memulai tuning, coba tutorial penyempurnaan kualitas. Jika Anda ingin pengantar yang lebih umum tentang menyesuaikan LLM untuk kasus penggunaan tertentu, keluar LLM: Fine-tuning, distilasi, dan prompt engineering di Kursus Singkat Machine Learning.
Cara kerja penyesuaian
Tujuan penyesuaian adalah untuk lebih meningkatkan performa model untuk tugas tertentu Anda. Penyesuaian halus bekerja dengan menyediakan set data pelatihan kepada model yang berisi banyak contoh tugas. Untuk tugas khusus, Anda bisa mendapatkan performa model meningkat signifikan dengan men-tune model menggunakan jumlah contoh. Penyesuaian model seperti ini terkadang disebut sebagai supervised fine-tuning, untuk membedakannya dari jenis fine-tuning lainnya.
Data pelatihan Anda harus disusun sebagai contoh dengan input perintah dan output respons yang diharapkan. Anda juga dapat menyesuaikan model secara langsung menggunakan data contoh di Google AI Studio. Tujuannya adalah mengajari model untuk meniru perilaku yang diinginkan atau tugas tertentu, dengan memberi banyak contoh yang menggambarkan perilaku atau tugas tersebut.
Saat Anda menjalankan tugas tuning, model akan mempelajari parameter tambahan yang membantunya mengenkode informasi yang diperlukan untuk melakukan tugas yang diinginkan atau mempelajari perilaku model. Parameter ini kemudian dapat digunakan pada waktu inferensi. Output tugas tuning adalah model baru, yang secara efektif merupakan kombinasi dari parameter yang baru dipelajari dan model asli.
Menyiapkan set data
Sebelum dapat memulai fine-tuning, Anda memerlukan set data untuk melakukan penyesuaian pada model. Untuk performa terbaik, contoh dalam set data harus berkualitas tinggi, beragam, dan mewakili input dan output yang sebenarnya.
Format
Contoh yang disertakan dalam set data harus sesuai dengan traffic produksi yang Anda harapkan. Jika set data Anda berisi pemformatan, kata kunci, petunjuk, atau informasi tertentu, data produksi harus diformat dengan cara yang sama dan berisi petunjuk yang sama.
Misalnya, jika contoh di set data Anda menyertakan "question:" dan "context:", traffic produksi juga harus diformat untuk menyertakan "question:" dan "context:" dalam urutan yang sama seperti yang tampak
pada contoh set data. Jika Anda mengecualikan konteks, model tidak dapat mengenali pola,
meskipun pertanyaan yang sama ada dalam contoh dalam set data.
Sebagai contoh lain, berikut adalah data pelatihan Python untuk aplikasi yang menghasilkan angka berikutnya dalam urutan:
training_data = [
{"text_input": "1", "output": "2"},
{"text_input": "3", "output": "4"},
{"text_input": "-3", "output": "-2"},
{"text_input": "twenty two", "output": "twenty three"},
{"text_input": "two hundred", "output": "two hundred one"},
{"text_input": "ninety nine", "output": "one hundred"},
{"text_input": "8", "output": "9"},
{"text_input": "-98", "output": "-97"},
{"text_input": "1,000", "output": "1,001"},
{"text_input": "10,100,000", "output": "10,100,001"},
{"text_input": "thirteen", "output": "fourteen"},
{"text_input": "eighty", "output": "eighty one"},
{"text_input": "one", "output": "two"},
{"text_input": "three", "output": "four"},
{"text_input": "seven", "output": "eight"},
]
Menambahkan perintah atau pengantar ke setiap contoh dalam set data Anda juga dapat membantu meningkatkan performa model yang dioptimalkan. Perhatikan, jika perintah atau pengantar disertakan dalam set data Anda, perintah tersebut juga harus disertakan dalam perintah ke model yang dioptimalkan pada waktu inferensi.
Batasan
Catatan: Menyempurnakan set data untuk Gemini 1.5 Flash memiliki hal berikut batasan:
- Ukuran input maksimum per contoh adalah 40.000 karakter.
- Ukuran output maksimum per contoh adalah 5.000 karakter.
Ukuran data pelatihan
Anda dapat meningkatkan kualitas model hanya dengan 20 contoh. Data tambahan umumnya meningkatkan kualitas respons. Anda harus menargetkan antara 100 dan 500 contoh, bergantung pada aplikasi Anda. Tabel berikut menunjukkan ukuran set data yang direkomendasikan untuk menyesuaikan model teks untuk berbagai tugas umum:
| Tugas | Jumlah contoh dalam set data |
|---|---|
| Klasifikasi | 100+ |
| Perangkuman | 100-500+ |
| Penelusuran dokumen | 100+ |
Mengupload set data penyesuaian
Data diteruskan secara inline menggunakan API atau melalui file yang diupload di Google di Generative AI Studio.
Untuk menggunakan library klien, berikan file data dalam panggilan createTunedModel.
Batas ukuran file adalah 4 MB. Lihat
panduan memulai penyempurnaan dengan Python
proses memulai.
Untuk memanggil REST API menggunakan cURL, berikan contoh pelatihan dalam format JSON ke argumen training_data. Lihat
panduan memulai penyesuaian dengan cURL
untuk memulai.
Setelan penyesuaian lanjutan
Saat membuat tugas penyesuaian, Anda dapat menentukan setelan lanjutan berikut:
- Epoch: Pass pelatihan penuh pada seluruh set pelatihan sehingga setiap contoh telah diproses satu kali.
- Ukuran batch: Kumpulan contoh yang digunakan dalam satu iterasi pelatihan. Ukuran batch menentukan jumlah contoh dalam batch.
- Kecepatan pembelajaran: Bilangan floating point yang memberi tahu algoritma seberapa besar parameter model harus disesuaikan pada setiap iterasi. Sebagai contoh, kecepatan pembelajaran 0,3 akan menyesuaikan bobot dan bias tiga kali lebih banyak lebih kuat daripada kecepatan pembelajaran 0,1. Rasio pembelajaran tinggi dan rendah memiliki kompromi unik tersendiri dan harus disesuaikan berdasarkan kasus penggunaan Anda.
- Pengganda kecepatan pembelajaran: Pengganda kecepatan mengubah nilai dengan kecepatan pembelajaran asli. Nilai 1 menggunakan kecepatan pembelajaran asli dari model transformer. Nilai yang lebih besar dari 1 akan meningkatkan kecepatan pemelajaran dan nilai antara 1 dan 0 menurunkan kecepatan pemelajaran.
Konfigurasi yang direkomendasikan
Tabel berikut menunjukkan konfigurasi yang disarankan untuk melakukan fine-tuning model dasar berikut:
| Hyperparameter | Nilai default | Penyesuaian yang direkomendasikan |
|---|---|---|
| Epoch | 5 |
Jika kerugian mulai mendatar sebelum 5 epoch, gunakan nilai yang lebih kecil. Jika kerugian meningkat dan tampaknya tidak stabil, gunakan nilai yang lebih tinggi. |
| Ukuran batch | 4 | |
| Kecepatan pembelajaran | 0,001 | Gunakan nilai yang lebih kecil untuk set data yang lebih kecil. |
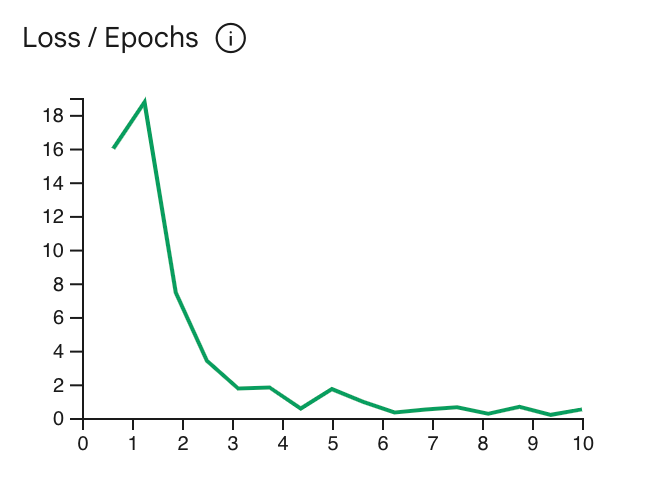
Kurva kerugian menunjukkan seberapa besar prediksi model menyimpang dari ideal
prediksi dalam contoh pelatihan setelah setiap epoch. Idealnya, Anda perlu menghentikan
di titik terendah dalam kurva, tepat sebelum data itu stabil. Misalnya,
grafik di bawah menunjukkan kurva kerugian yang datar pada sekitar epoch 4-6, yang berarti
Anda dapat menetapkan parameter Epoch ke 4 dan tetap mendapatkan performa yang sama.
Memeriksa status tugas penyesuaian
Anda dapat memeriksa status tugas penyesuaian di Google AI Studio pada tab
Library Saya atau menggunakan properti metadata dari model yang disesuaikan di
Gemini API.
Mengatasi error
Bagian ini mencakup tips tentang cara mengatasi error yang mungkin Anda alami saat membuat model yang dioptimalkan.
Autentikasi
Penyesuaian menggunakan API dan library klien memerlukan autentikasi. Anda dapat menyiapkan autentikasi menggunakan kunci API (direkomendasikan) atau menggunakan OAuth memiliki kredensial yang lengkap. Untuk dokumentasi tentang cara menyiapkan kunci API, lihat Menyiapkan kunci API.
Jika melihat error 'PermissionDenied: 403 Request had insufficient authentication
scopes', Anda mungkin perlu menyiapkan autentikasi pengguna menggunakan kredensial
OAuth. Untuk mengonfigurasi kredensial OAuth untuk Python, kunjungi
tutorial penyiapan OAuth.
Model yang dibatalkan
Anda dapat membatalkan tugas penyesuaian kapan saja sebelum tugas selesai. Namun, performa inferensi model yang dibatalkan tidak dapat diprediksi, terutama jika tugas tuning dibatalkan di awal pelatihan. Jika Anda membatalkan karena ingin menghentikan pelatihan pada epoch sebelumnya, Anda harus membuat tugas penyesuaian baru dan menetapkan epoch ke nilai yang lebih rendah.
Batasan model yang disesuaikan
Catatan: Model yang dioptimalkan memiliki batasan berikut:
- Batas input model Gemini 1.5 Flash yang dioptimalkan adalah 40.000 karakter.
- Mode JSON tidak didukung dengan model yang disesuaikan.
- Hanya input teks yang didukung.
Langkah berikutnya
Mulai dengan tutorial fine-tuning: