
Estratégias de design de comandos, como comandos de poucos disparos (few-shot), nem sempre produzem os resultados necessários. O ajuste é um processo que pode melhorar a desempenho em tarefas específicas ou ajudar o modelo a aderir a resultados quando as instruções não são suficientes e você tem um conjunto de exemplos que demonstrem os resultados desejados.
Esta página fornece uma visão geral conceitual do ajuste do modelo de texto por trás o serviço de texto da API Gemini. Quando estiver tudo pronto para começar o ajuste, teste o tutorial de ajuste. Se você quiser uma introdução mais geral à personalização de LLMs para casos de uso específicos, confira LLMs: ajuste fino, destilação e engenharia de comando no Curso intensivo de machine learning.
Como funciona o ajuste
O objetivo do ajuste é melhorar ainda mais o desempenho do modelo para para a tarefa específica. O ajuste fino funciona fornecendo ao modelo um conjunto de dados de treinamento que contém muitos exemplos da tarefa. Para tarefas de nicho, é possível conseguir melhorias significativas no desempenho do modelo ajustando o modelo em um número modesto de exemplos. Esse tipo de ajuste de modelo é chamado ajustes supervisionados para distingui-los de outros tipos de ajustes.
Os dados de treinamento precisam ser estruturados como exemplos com entradas de comandos as saídas esperadas de resposta. Também é possível ajustar modelos usando dados de exemplo diretamente no Google AI Studio. O objetivo é ensinar o modelo a imitar o comportamento desejado ou tarefa, fornecendo muitos exemplos que ilustram esse comportamento ou tarefa.
Ao executar um job de ajuste, o modelo aprende outros parâmetros que o ajudam a codificar as informações necessárias para executar a tarefa desejada ou aprender o comportamento desejado. Esses parâmetros podem ser usados no momento da inferência. A saída do o job de ajuste é um novo modelo, que é uma combinação da nova parâmetros aprendidos e o modelo original.
Preparar o conjunto de dados
Antes de começar o ajuste, você precisa de um conjunto de dados para ajustar o modelo. Para o melhor desempenho, os exemplos no conjunto de dados devem ser de alta qualidade, diversificados e representativos de entradas e saídas reais.
Formato
Os exemplos no seu conjunto de dados precisam corresponder ao tráfego de produção esperado. Se o conjunto de dados contiver formatação, palavras-chave, instruções ou informações específicas, os dados de produção deverão ser formatados da mesma maneira e conter as mesmas instruções.
Por exemplo, se os exemplos no seu conjunto de dados incluem um "question:" e um "context:", o tráfego de produção também deve ser formatado para incluir um "question:" e um "context:" na mesma ordem em que aparece no exemplos de conjuntos de dados. Se você excluir o contexto, o modelo não reconhecerá o padrão,
mesmo que a pergunta exata esteja em um exemplo no conjunto de dados.
Como outro exemplo, aqui estão os dados de treinamento do Python para um aplicativo que gera o próximo número em uma sequência:
training_data = [
{"text_input": "1", "output": "2"},
{"text_input": "3", "output": "4"},
{"text_input": "-3", "output": "-2"},
{"text_input": "twenty two", "output": "twenty three"},
{"text_input": "two hundred", "output": "two hundred one"},
{"text_input": "ninety nine", "output": "one hundred"},
{"text_input": "8", "output": "9"},
{"text_input": "-98", "output": "-97"},
{"text_input": "1,000", "output": "1,001"},
{"text_input": "10,100,000", "output": "10,100,001"},
{"text_input": "thirteen", "output": "fourteen"},
{"text_input": "eighty", "output": "eighty one"},
{"text_input": "one", "output": "two"},
{"text_input": "three", "output": "four"},
{"text_input": "seven", "output": "eight"},
]
Adicionar um comando ou preâmbulo a cada exemplo no conjunto de dados também pode ajudar a melhorar o desempenho do modelo ajustado. Se um comando ou preâmbulo for incluído no seu conjunto de dados, ele também precisará ser incluído no comando para o modelo sintonizado no momento da inferência.
Limitações
Observação: os conjuntos de dados de ajuste fino para o Gemini 1.5 Flash têm as seguintes limitações:
- O tamanho máximo de entrada por exemplo é de 40.000 caracteres.
- O tamanho máximo da saída por exemplo é de 5.000 caracteres.
Tamanho dos dados de treinamento
É possível ajustar um modelo com apenas 20 exemplos. Dados adicionais melhora a qualidade das respostas. Você deve ter entre 100 e 500 exemplos, dependendo do seu aplicativo. A tabela a seguir mostra tamanhos de conjuntos de dados recomendados para ajustar um modelo de texto para várias tarefas comuns:
| Tarefa | Nº de exemplos no conjunto de dados |
|---|---|
| Classificação | 100+ |
| Resumo | 100-500+ |
| Pesquisa de documentos | 100+ |
Fazer upload do conjunto de dados de ajuste
Os dados são transmitidos inline usando a API ou por meio de arquivos enviados ao Google do Vertex AI Studio.
Para usar a biblioteca de cliente, forneça o arquivo de dados na chamada createTunedModel.
O arquivo pode ter até 4 MB. Consulte a
Guia de início rápido de ajuste com Python
para começar.
Para chamar a API REST usando cURL, dê exemplos de treinamento no formato JSON à
argumento training_data. Consulte o
guia de início rápido de ajuste com o cURL
para começar.
Configurações de ajuste avançadas
Ao criar um job de ajuste, é possível especificar as seguintes configurações avançadas:
- Períodos: uma passagem de treinamento completa por todo o conjunto de treinamento, de modo que cada exemplo seja processado uma vez.
- Tamanho do lote: o conjunto de exemplos usado em uma iteração de treinamento. O tamanho do lote determina o número de exemplos em um lote.
- Taxa de aprendizado: um número de ponto flutuante que informa ao algoritmo como ajustar os parâmetros do modelo em cada iteração. Por exemplo, uma taxa de aprendizado de 0,3 ajustaria os pesos e os vieses três vezes mais muito mais do que uma taxa de aprendizado de 0,1. As taxas de aprendizado altas e baixas têm suas próprias compensações e precisam ser ajustadas com base no seu caso de uso.
- Multiplicador da taxa de aprendizado: o multiplicador de taxa modifica a taxa de aprendizado original do modelo. Um valor de 1 usa a taxa de aprendizado original do modelo. Valores maiores que 1 aumentam a taxa de aprendizado e valores entre 1 e 0 diminui a taxa de aprendizado.
Configurações recomendadas
A tabela a seguir mostra as configurações recomendadas para ajustar um modelo de base:
| Hiperparâmetro | Valor padrão | Ajustes recomendados |
|---|---|---|
| Período | 5 |
Se a perda começar a se estabilizar antes de 5 épocas, use um valor menor. Se a perda estiver convergindo e não parecer ter um platô, use um valor mais alto. |
| Tamanho do lote | 4 | |
| Taxa de aprendizado | 0,001 | Use um valor menor para conjuntos de dados menores. |
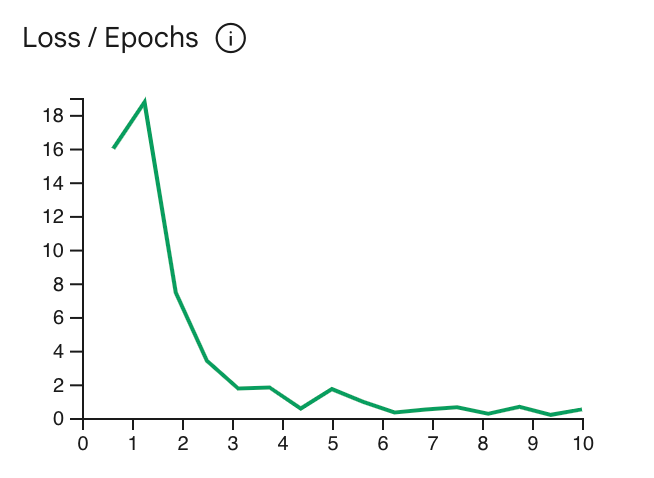
A curva de perda mostra o quanto a previsão do modelo se desvia das previsões
ideais nos exemplos de treinamento após cada época. O ideal é interromper
o treinamento no ponto mais baixo da curva, logo antes de ele atingir o platô. Por exemplo,
o gráfico abaixo mostra a curva de perda estabilizando-se na época 4-6, o que significa
que você pode definir o parâmetro Epoch como 4 e ainda ter o mesmo desempenho.
Verificar o status do job de ajuste
É possível verificar o status do job de ajuste no Google AI Studio na guia
My Library ou usando a propriedade metadata do modelo ajustado na
API Gemini.
Solucionar erros
Esta seção inclui dicas sobre como resolver erros que podem ocorrer ao criar o modelo ajustado.
Autenticação
O ajuste usando a API e a biblioteca de cliente requer autenticação. É possível configurar a autenticação usando uma chave de API (recomendado) ou credenciais OAuth. Para acessar a documentação sobre como configurar uma chave de API, consulte Configure a chave de API.
Se você receber um erro 'PermissionDenied: 403 Request had insufficient authentication
scopes', talvez seja necessário configurar a autenticação do usuário usando credenciais
do OAuth. Para configurar as credenciais do OAuth no Python, acesse nosso
tutorial de configuração do OAuth.
Modelos cancelados
É possível cancelar um job de ajuste fino a qualquer momento antes da conclusão. No entanto, o desempenho de inferência de um modelo cancelado é imprevisível, especialmente se o job de ajuste é cancelado no início do treinamento. Se você cancelou porque quer interromper o treinamento em uma época anterior, crie um novo job de ajuste e defina a época como um valor menor.
Limitações dos modelos ajustados
Observação:modelos ajustados têm as seguintes limitações:
- O limite de entrada de um modelo Gemini 1.5 Flash ajustado é de 40.000 caracteres.
- O modo JSON não é compatível com modelos ajustados.
- Somente a entrada de texto é aceita.
A seguir
Comece a usar os tutoriais de ajuste fino: