API-ja Gemini ofron cilësime sigurie që mund t'i rregulloni gjatë fazës së prototipimit për të përcaktuar nëse aplikacioni juaj kërkon një konfigurim sigurie pak a shumë kufizues. Mund t'i rregulloni këto cilësime në katër kategori filtri për të kufizuar ose lejuar lloje të caktuara përmbajtjeje.
Ky udhëzues trajton mënyrën se si Gemini API trajton cilësimet e sigurisë dhe filtrimin dhe si mund t'i ndryshoni cilësimet e sigurisë për aplikacionin tuaj.
Filtra sigurie
Filtrat e sigurisë të rregullueshme të Gemini API mbulojnë kategoritë e mëposhtme:
| Kategoria | Përshkrimi |
|---|---|
| Ngacmim | Komente negative ose të dëmshme që synojnë identitetin dhe/ose atributet e mbrojtura. |
| Gjuhë urrejtjeje | Përmbajtje e pasjellshme, fyese ose fyese. |
| Seksualisht eksplicite | Përmban referenca për akte seksuale ose përmbajtje të tjera të turpshme. |
| I rrezikshëm | Nxit, lehtëson ose inkurajon akte të dëmshme. |
These categories are defined in HarmCategory . You can use these filters to adjust what's appropriate for your use case. For example, if you're building video game dialogue, you may deem it acceptable to allow more content that's rated as Dangerous due to the nature of the game.
Përveç filtrave të sigurisë të rregullueshëm, Gemini API ka mbrojtje të integruara kundër dëmeve thelbësore, siç është përmbajtja që rrezikon sigurinë e fëmijëve. Këto lloje dëmesh bllokohen gjithmonë dhe nuk mund të rregullohen.
Niveli i filtrimit të sigurisë së përmbajtjes
API Gemini e kategorizon nivelin e probabilitetit që përmbajtja të jetë e pasigurt si HIGH , MEDIUM , LOW ose NEGLIGIBLE .
API-ja Gemini bllokon përmbajtjen bazuar në probabilitetin që përmbajtja të jetë e pasigurt dhe jo në ashpërsinë e saj. Kjo është e rëndësishme të merret në konsideratë sepse disa përmbajtje mund të kenë probabilitet të ulët për të qenë të pasigurt edhe pse ashpërsia e dëmit mund të jetë ende e lartë. Për shembull, krahasimi i fjalive:
- Roboti më goditi me grusht.
- Roboti më goditi përdhe.
Fjalia e parë mund të rezultojë në një probabilitet më të lartë për të qenë i pasigurt, por ju mund ta konsideroni fjalinë e dytë si një ashpërsi më të lartë për sa i përket dhunës. Duke pasur parasysh këtë, është e rëndësishme që të testoni me kujdes dhe të merrni në konsideratë se cili është niveli i duhur i bllokimit që nevojitet për të mbështetur rastet tuaja kryesore të përdorimit, duke minimizuar dëmin për përdoruesit fundorë.
Filtrim sigurie sipas kërkesës
Mund të rregulloni cilësimet e sigurisë për çdo kërkesë që bëni në API. Kur bëni një kërkesë, përmbajtja analizohet dhe i caktohet një vlerësim sigurie. Vlerësimi i sigurisë përfshin kategorinë dhe probabilitetin e klasifikimit të dëmit. Për shembull, nëse përmbajtja është bllokuar për shkak se kategoria e ngacmimit ka një probabilitet të lartë, vlerësimi i sigurisë i kthyer do të ketë kategorinë e barabartë me HARASSMENT dhe probabilitetin e dëmit të vendosur në HIGH .
Për shkak të sigurisë së natyrshme të modelit, filtrat shtesë janë çaktivizuar si parazgjedhje. Nëse zgjidhni t'i aktivizoni, mund ta konfiguroni sistemin për të bllokuar përmbajtjen bazuar në probabilitetin e saj për të qenë e pasigurt. Sjellja e parazgjedhur e modelit mbulon shumicën e rasteve të përdorimit, kështu që duhet t'i rregulloni këto cilësime vetëm nëse kërkohet vazhdimisht për aplikacionin tuaj.
Tabela e mëposhtme përshkruan cilësimet e bllokimit që mund të rregulloni për secilën kategori. Për shembull, nëse e vendosni cilësimin e bllokimit në Blloko pak për kategorinë Gjuhë urrejtjeje , çdo gjë që ka një probabilitet të lartë të jetë përmbajtje me gjuhë urrejtjeje bllokohet. Por çdo gjë me një probabilitet më të ulët lejohet.
| Pragu (Google AI Studio) | Pragu (API) | Përshkrimi |
|---|---|---|
| Joaktiv | OFF | Fikni filtrin e sigurisë |
| Blloko asnjë | BLOCK_NONE | Shfaq gjithmonë pavarësisht nga probabiliteti i përmbajtjes së pasigurt |
| Blloko disa | BLOCK_ONLY_HIGH | Blloko kur ka probabilitet të lartë të përmbajtjes së pasigurt |
| Blloko disa | BLOCK_MEDIUM_AND_ABOVE | Blloko kur ka probabilitet mesatar ose të lartë të përmbajtjes së pasigurt |
| Blloko shumicën | BLOCK_LOW_AND_ABOVE | Blloko kur probabiliteti i përmbajtjes së pasigurt është i ulët, mesatar ose i lartë |
| N/A | HARM_BLOCK_THRESHOLD_UNSPECIFIED | Pragu është i paspecifikuar, bllokohet duke përdorur pragun e parazgjedhur |
Nëse pragu nuk është vendosur, pragu i bllokut parazgjedhur është Joaktiv për modelet Gemini 2.5 dhe 3.
Mund t’i caktoni këto cilësime për çdo kërkesë që i bëni shërbimit gjenerues. Shihni referencën e HarmBlockThreshold API për detaje.
Reagime për sigurinë
generateContent kthen një GenerateContentResponse i cili përfshin reagime mbi sigurinë.
Reagimi i shpejtë përfshihet në promptFeedback . Nëse është vendosur promptFeedback.blockReason , atëherë përmbajtja e kërkesës është bllokuar.
Response candidate feedback is included in Candidate.finishReason and Candidate.safetyRatings . If response content was blocked and the finishReason was SAFETY , you can inspect safetyRatings for more details. The content that was blocked is not returned.
Rregullo cilësimet e sigurisë
Ky seksion trajton mënyrën e rregullimit të cilësimeve të sigurisë si në Google AI Studio ashtu edhe në kodin tuaj.
Studioja e AI-së e Google-it
Mund të rregulloni cilësimet e sigurisë në Google AI Studio.
Klikoni Cilësimet e Sigurisë nën Cilësimet e Avancuara në panelin e Cilësimeve të Ekzekutimit për të hapur modalin e Cilësimeve të Sigurisë së Ekzekutimit . Në modal, mund të përdorni rrëshqitësit për të rregulluar nivelin e filtrimit të përmbajtjes sipas kategorisë së sigurisë:
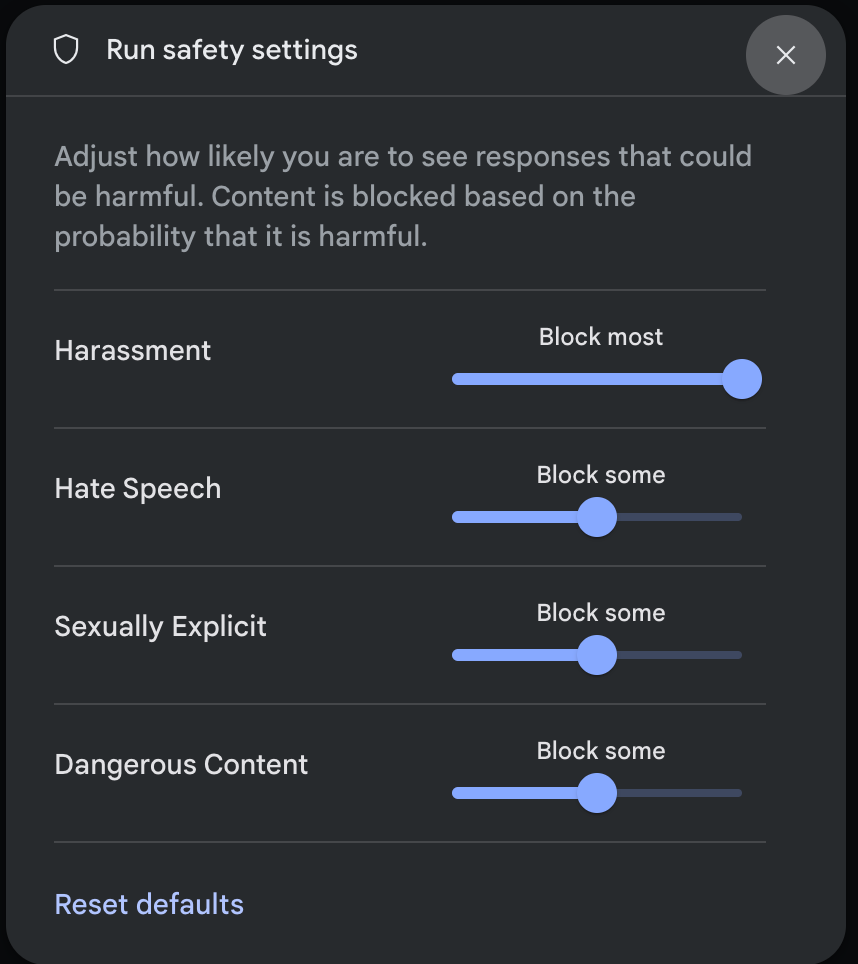
Kur dërgoni një kërkesë (për shembull, duke i bërë modelit një pyetje), shfaqet një mesazh Përmbajtja është e bllokuar nëse përmbajtja e kërkesës është e bllokuar. Për të parë më shumë detaje, mbani treguesin mbi tekstin Përmbajtja është e bllokuar për të parë kategorinë dhe probabilitetin e klasifikimit të dëmit.
Shembuj kodi
The following code snippet shows how to set safety settings in your GenerateContent call. This sets the threshold for the hate speech ( HARM_CATEGORY_HATE_SPEECH ) category. Setting this category to BLOCK_LOW_AND_ABOVE blocks any content that has a low or higher probability of being hate speech. To understand the threshold settings, see Safety filtering per request .
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Shko
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3-flash-preview",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3-flash-preview",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3-flash-preview",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
PUSHTIM
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
Hapat e ardhshëm
- Shihni referencën e API-t për të mësuar më shumë rreth API-t të plotë.
- Rishikoni udhëzimet e sigurisë për një vështrim të përgjithshëm mbi konsideratat e sigurisë gjatë zhvillimit me LLM.
- Learn more about assessing probability versus severity from the Jigsaw team
- Mësoni më shumë rreth produkteve që kontribuojnë në zgjidhjet e sigurisë si Perspective API . * Mund t'i përdorni këto cilësime sigurie për të krijuar një klasifikues toksiciteti. Shihni shembullin e klasifikimit për të filluar.