
דף המודל: CodeGemma
משאבים ותיעוד טכני:
התנאים וההגבלות: התנאים
מחברים: Google
פרטי דגם
סיכום המודל
תיאור
CodeGemma היא משפחה של מודלים קלים בקוד פתוח שנוצרו על גבי Gemma. מודלים של CodeGemma הם מודלים של מפענחים בלבד, שממירים טקסט לטקסט וטקסט לקוד. הם זמינים כגרסה מותאמת מראש עם 7 מיליארד פרמטרים שמתמחה במשימות של השלמת קוד ויצירת קוד, כגרסה מותאמת מראש עם 7 מיליארד פרמטרים שמתמחה בצ'אט בקוד ובביצוע הוראות, וכגרסה מותאמת מראש עם 2 מיליארד פרמטרים שמתמחה בהשלמת קוד מהירה.
קלט ופלט
קלט: לגרסאות של מודלים שהותאמו מראש: תחילית קוד וסיומת אופציונלית בתרחישים של השלמה וייצור של קוד, או טקסט/הנחיה בשפה טבעית. עבור וריאנט של מודל שהותאם להוראות: טקסט או הנחיה בשפה טבעית.
פלט: לגרסאות של מודלים שהותאמו מראש: השלמת קוד באמצע, קוד ושפה טבעית. עבור וריאנט של מודל מותאם להוראות: קוד ושפה טבעית.
ציטוט ביבליוגרפי
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
נתוני מודל
מערך נתונים לאימון
באמצעות Gemma בתור מודל הבסיס, הוכשרו וריאנטים מוכנים מראש של CodeGemma 2B ו-7B על סמך 500 עד 1,000 מיליארד אסימונים נוספים של נתונים בשפה האנגלית, בעיקר ממערכי נתונים של מתמטיקה בקוד פתוח ומקוד שנוצר באופן סינתטי.
עיבוד נתוני אימון
כדי לאמן את CodeGemma, השתמשנו בשיטות הבאות לעיבוד מוקדם של נתונים:
- FIM – מודלים של CodeGemma שהותאמו מראש מתמקדים במשימות של מילוי החסר (FIM). המודלים מאומנים לעבוד גם במצב PSM וגם במצב SPM. ההגדרות שלנו ל-FIM הן שיעור FIM של 80% עד 90% עם חלוקה של 50%-50% בין PSM לבין SPM.
- שיטות אריזה שמבוססות על תרשים יחסי תלות ושיטות אריזה לקובצי מילון שמבוססות על בדיקות יחידה: כדי לשפר את ההתאמה של המודל לאפליקציות בעולם האמיתי, פיתחנו דוגמאות לאימון ברמת הפרויקט או המאגר כדי למקם יחד את קובצי המקור הרלוונטיים ביותר בכל מאגר. באופן ספציפי, השתמשנו בשתי שיטות חזותיות: אריזה שמבוססת על תרשים יחסי תלות ואריזה לקסיקלית שמבוססת על בדיקת יחידה.
- פיתחנו שיטה חדשנית לפצל את המסמכים לתחילית, אמצע וסיומת, כדי שהסיומת תתחיל בנקודה טבעית יותר מבחינה תחבירית, ולא בהפצה אקראית לחלוטין.
- בטיחות: בדומה ל-Gemma, פרסנו סינון קפדני של תוכן לא בטיחותי, כולל סינון של מידע אישי, סינון של תוכן פורנוגרפי וסינון אחר על סמך איכות התוכן והבטיחות שלו, בהתאם למדיניות שלנו.
מידע על ההטמעה
החומרה והמסגרות שבהן נעשה שימוש במהלך האימון
כמו Gemma, גם CodeGemma הוכשרה על גבי חומרת הדור האחרון של יחידת עיבוד טרנספורמציות (TPU) (TPUv5e), באמצעות JAX ו-ML Pathways.
פרטי ההערכה
תוצאות של בנצ'מרק
שיטת ההערכה
- מדדי ביצועים להשלמתם של שורות קוד: HumanEval (HE) (מילוי של שורה אחת ומספר שורות)
- מדדי ביצועים ליצירת קוד: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
- שאלות ותשובות: BoolQ, PIQA, TriviaQA
- שפה טבעית: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- חשיבה מתמטית: GSM8K, MATH
תוצאות של מדדי ביצועים בתחום הקוד
| השוואה לשוק | 2B | 2B (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4 |
| MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6 |
| HumanEval Single Line | 78.4 | 79.3 | 76.1 | 68.3 | 77.4 |
| HumanEval Multi Line | 51.4 | 51.0 | 58.4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6 |
| BC HE C# | 10.6 | 26.1 | 22.4 | 26.7 | 54.7 |
| BC HE Go | 20.5 | 18.0 | 21.7 | 28.6 | 34.2 |
| BC HE Java | 29.2 | 29.8 | 41.0 | 48.4 | 50.3 |
| BC HE JavaScript | 21.7 | 28.0 | 39.8 | 46.0 | 48.4 |
| BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8 |
| BC HE Python | 21.7 | 36.6 | 42.2 | 48.4 | 54.0 |
| BC HE Rust | 26.7 | 24.2 | 34.1 | 36.0 | 37.3 |
| BC MBPP C++ | 47.1 | 38.9 | 53.8 | 56.7 | 63.5 |
| BC MBPP C# | 28.7 | 45.3 | 32.5 | 41.2 | 62.0 |
| BC MBPP Go | 45.6 | 38.9 | 43.3 | 46.2 | 53.2 |
| BC MBPP Java | 41.8 | 49.7 | 50.3 | 57.3 | 62.9 |
| BC MBPP JavaScript | 45.3 | 45.0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6 |
| BC MBPP Python | 38.6 | 52.9 | 59.1 | 62.0 | 60.2 |
| BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3 |
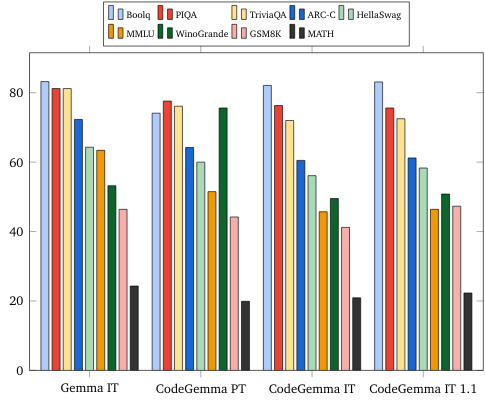
מדדי ביצועים של שפה טבעית (במודלים של 7 מיליארד)
אתיקה ובטיחות
בדיקות אתיקה ובטיחות
הגישה למבדקים
שיטות ההערכה שלנו כוללות בדיקות מובנות ובדיקות פנימיות של צוות אדום (red team) של מדיניות התוכן הרלוונטית. צוות אדום ניהל מספר צוותים שונים, לכל אחד מהם מטרות שונות ומדדים שונים של הערכה אנושית. המודלים האלה נבדקו בהתאם למספר קטגוריות שונות שקשורות לאתיקה ולבטיחות, כולל:
הערכה אנושית של הנחיות בנושאי בטיחות תוכן ונזקים שקשורים לייצוג. פרטים נוספים על שיטת ההערכה זמינים בכרטיס המודל של Gemma.
בדיקה ספציפית של יכולות התקפה באינטרנט, שמתמקדת בבדיקת יכולות פריצה אוטונומיות ובהבטחת שהנזקים הפוטנציאליים מוגבלים.
תוצאות הבדיקה
התוצאות של הבדיקות האתיות והבטיחותיות נמצאות בגבולות הסף הקבילים למדיניות הפנימית בקטגוריות כמו בטיחות ילדים, בטיחות תוכן, נזקים שקשורים לייצוג, שמירה בזיכרון ונזקים בקנה מידה רחב. פרטים נוספים זמינים בכרטיס המודל של Gemma.
שימוש במודלים והגבלות
מגבלות ידועות
למודלים גדולים של שפה (LLMs) יש מגבלות שמבוססות על נתוני האימון שלהם ועל המגבלות הטבועות בטכנולוגיה. בכרטיס המודל של Gemma מפורט מידע נוסף על המגבלות של LLM.
שיקולים אתיים וסיכונים
הפיתוח של מודלים גדולים של שפה (LLM) מעלה כמה חששות אתיים. במהלך הפיתוח של המודלים האלה, התייחסנו בקפידה למספר היבטים.
פרטי המודל מפורטים באותה שיחה בכרטיס המודל של Gemma.
שימוש מיועד
אפליקציה
למודלים של Code Gemma יש מגוון רחב של יישומים, שמשתנים בהתאם למודלים של IT ו-PT. רשימת השימושים האפשריים הבאה היא חלקית. מטרת הרשימה הזו היא לספק מידע לפי הקשר לגבי תרחישי השימוש האפשריים שאותם הגדירו יוצרי המודל במסגרת אימון המודל ופיתוח המודל.
- השלמת קוד: אפשר להשתמש במודלים של PT כדי להשלים קוד באמצעות תוסף IDE
- יצירת קוד: אפשר להשתמש במודל IT כדי ליצור קוד עם או בלי תוסף IDE
- שיחה על קוד: מודל IT יכול להפעיל ממשקי שיחה שמדברים על קוד
- Code Education: מודל IT שתומך בחוויית למידה אינטראקטיבית של קוד, עוזר בתיקון תחביר או מספק תרגול תכנות
יתרונות
נכון למועד הפרסום, משפחת המודלים הזו מספקת הטמעות של מודלים גדולים של שפה (LLM) שמתמקדות בקוד פתוח ובביצועים גבוהים, ועוצבו מלכתחילה לפיתוח של AI אחראי בהשוואה למודלים בגודל דומה.
לפי מדדי ההערכה של מדדי הקוד שמפורטים במסמך הזה, המודלים האלה סיפקו ביצועים טובים יותר ממודלים אחרים בגודל דומה של קוד פתוח.