
并排评估已成为评估 大型语言模型 (LLM) 响应的质量和安全性。并排 比较可用于在两个不同的模型之间进行选择, 同一模型,甚至是模型的两个不同的调参。不过,手动分析并排比较结果可能既繁琐又乏味。
LLM Comparator 是一个 Web 应用,配有相应的 Python 库,可通过交互式可视化功能更有效、更可伸缩地分析并排评估。LLM 比较器可帮助您:
查看模型性能的不同之处:您可以对响应进行切片处理 识别输出有意义的评估数据的子集 两种模型之间的差异。
了解差异的原因:通常,系统会根据某项政策来评估模型性能和合规性。并排评估有助于自动执行政策合规性评估,并提供有关哪个模型可能更合规的理由。LLM 对比工具将这些原因总结为几个主题, 会突出显示每个主题与哪个模型更匹配。
检查模型输出的差异:您可以通过内置和用户定义的比较函数进一步研究两个模型的输出差异。该工具可以突出显示文本中的特定模式 生成清晰的锚点,便于用户理解 差异
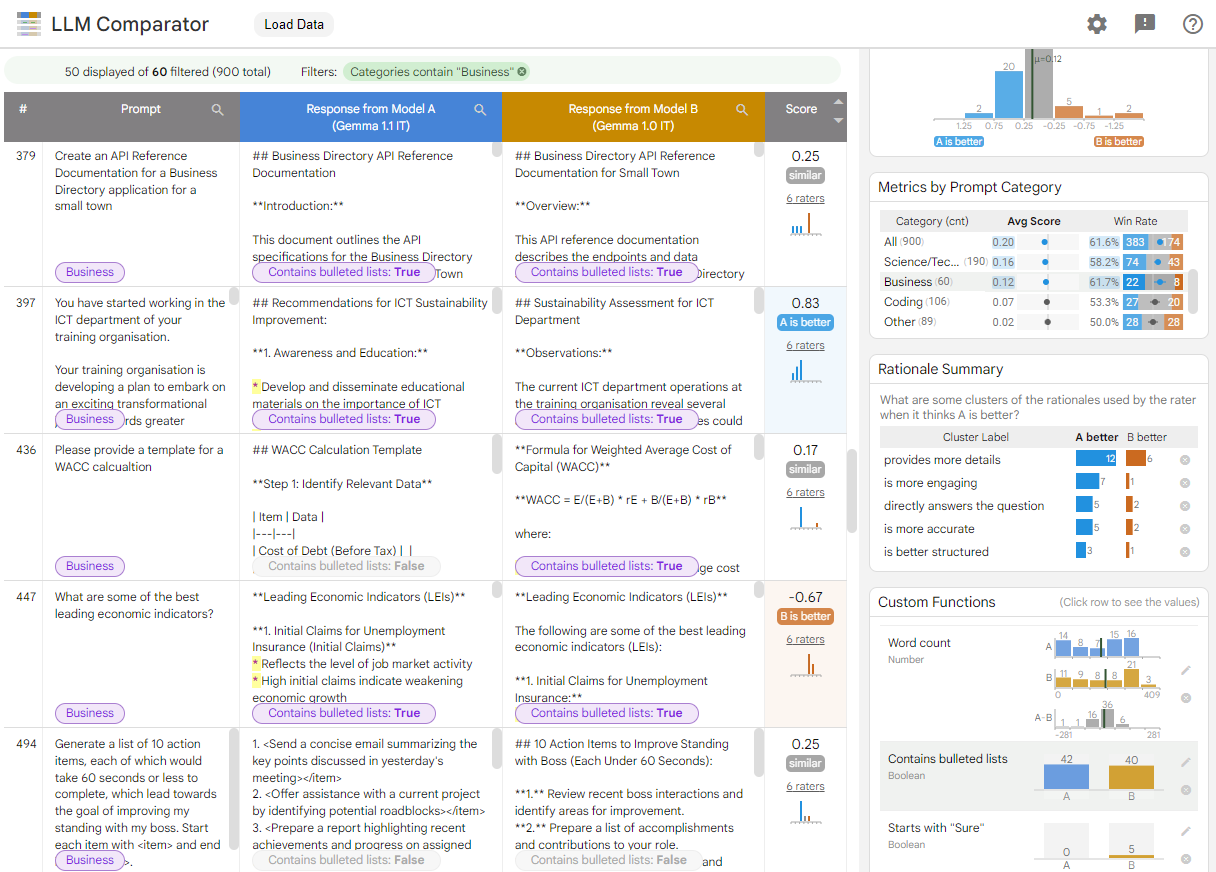
图 1. LLM 比较器界面,显示了 Gemma 比较 针对 v1.0 指示 7B v1.1 模型
LLM Comparator 可帮助您分析并排评估结果。它 从多个角度直观地总结模型性能,同时让您可以 以交互方式检查各个模型输出,以便更深入地了解相关信息。
亲自探索 LLM Comparator:
- 此演示比较了 Gemma Instruct 7B v1.1 与 Gemma Instruct 7B v1.0 在 Chatbot Arena Conversations 数据集上的性能。
- 此 Colab 笔记本使用 Python 库通过 Vertex AI API 运行一项小型并排评估,并将结果加载到单元格中的 LLM 比较器应用中。
如需详细了解 LLM 比较器,请参阅研究论文和 GitHub 代码库。