A API Gemini oferece configurações de segurança que podem ser ajustadas durante a prototipagem para determinar se o aplicativo requer uma configuração de segurança mais ou menos restritiva. É possível ajustar essas configurações em quatro categorias de filtros para restringir ou permitir determinados tipos de conteúdo.
Este guia mostra como a API Gemini lida com as configurações e a filtragem de segurança e como você pode mudar as configurações de segurança do seu aplicativo.
Filtros de segurança
Os filtros de segurança ajustáveis da API Gemini abrangem as seguintes categorias:
| Categoria | Descrição |
|---|---|
| Assédio | Comentários negativos ou prejudiciais relacionados à identidade e/ou características protegidas. |
| Discurso de ódio | Conteúdo grosseiro, desrespeitoso ou linguagem obscena. |
| Conteúdo sexualmente explícito | Contém referências a atos sexuais ou outro conteúdo obsceno. |
| Perigoso | Promove, facilita ou encoraja atos prejudiciais. |
Essas categorias são definidas em HarmCategory. Use esses filtros para ajustar o que for necessário conforme seu caso de uso. Por exemplo, se você estiver criando diálogos de videogame, poderá considerar aceitável permitir mais conteúdo classificado como Perigoso devido à natureza do jogo.
Além dos filtros de segurança ajustáveis, a API Gemini tem proteções integradas contra danos principais, como conteúdo que coloca crianças em risco. Esses tipos de danos são sempre bloqueados e não podem ser ajustados.
Nível de filtragem da segurança de conteúdo
A API Gemini categoriza o nível de probabilidade de um conteúdo ser considerado não seguro como
HIGH, MEDIUM, LOW ou NEGLIGIBLE.
A API Gemini bloqueia conteúdo com base na probabilidade de o conteúdo ser inseguro e não na gravidade. É importante considerar isso, porque alguns conteúdos podem ter baixa probabilidade de não serem seguros, mesmo que a gravidade dos danos ainda seja alta. Por exemplo, comparando as frases:
- O robô me bateu.
- O robô me cortou.
A primeira frase pode resultar em uma probabilidade maior de não ser segura, mas a segunda pode ser considerada mais grave em termos de violência. Por isso, é importante testar cuidadosamente e considerar o nível apropriado de bloqueio necessário para oferecer suporte aos seus principais casos de uso e minimizar os danos aos usuários finais.
Filtragem de segurança por solicitação
Você pode ajustar as configurações de segurança de cada solicitação feita à API. Quando você faz uma solicitação, o conteúdo é analisado e recebe uma classificação de segurança. A classificação de segurança inclui a categoria e a probabilidade da classificação de dano. Por exemplo, se o conteúdo foi bloqueado porque a categoria de assédio tem uma alta probabilidade, a classificação de segurança retornada teria a categoria igual a HARASSMENT e a probabilidade de dano definida como HIGH.
Devido à segurança inerente do modelo, outros filtros ficam desativados por padrão. Se você ativar essas opções, poderá configurar o sistema para bloquear conteúdo com base na probabilidade de ser inseguro. O comportamento padrão do modelo abrange a maioria dos casos de uso. Portanto, ajuste essas configurações apenas se isso for consistentemente necessário para sua aplicação.
A tabela a seguir descreve as configurações de bloqueio que você pode ajustar em cada categoria. Por exemplo, se você definir a configuração de bloqueio como Bloquear poucos na categoria Discurso de ódio, tudo com alta probabilidade de ser um conteúdo de discurso de ódio será bloqueado. No entanto, qualquer item com menor probabilidade de risco é permitido.
| Limite (Google AI Studio) | Limite (API) | Descrição |
|---|---|---|
| Desativado | OFF |
Desativar o filtro de segurança |
| Bloquear nenhum | BLOCK_NONE |
Sempre mostrar, seja qual for a probabilidade do conteúdo não ser seguro |
| Bloquear poucos | BLOCK_ONLY_HIGH |
Bloquear quando houver alta probabilidade do conteúdo não ser seguro |
| Bloquear alguns | BLOCK_MEDIUM_AND_ABOVE |
Bloquear quando houver probabilidade média ou alta do conteúdo não ser seguro |
| Bloquear muitos | BLOCK_LOW_AND_ABOVE |
Bloquear quando houver probabilidade baixa, média ou alta de o conteúdo não ser seguro |
| N/A | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
Como o limite não foi especificado, o bloqueio está usando o limite padrão. |
Se o limite não for definido, o padrão será Desativado para os modelos Gemini 2.5 e 3.
Você pode definir essas configurações para cada solicitação feita ao serviço generativo.
Consulte a referência da API HarmBlockThreshold
para mais detalhes.
Feedback de segurança
generateContent
retorna um
GenerateContentResponse que
inclui feedback de segurança.
O feedback do comando está incluído em
promptFeedback. Se
promptFeedback.blockReason estiver definido, o conteúdo da solicitação será bloqueado.
O feedback do candidato à resposta está incluído em
Candidate.finishReason e
Candidate.safetyRatings. Se o conteúdo da resposta foi bloqueado e o finishReason era SAFETY, inspecione safetyRatings para mais detalhes. O conteúdo bloqueado não é retornado.
Ajustar as configurações de segurança
Esta seção explica como ajustar as configurações de segurança no Google AI Studio e no seu código.
Google AI Studio
É possível ajustar as configurações de segurança no Google AI Studio.
Clique em Configurações de segurança em Configurações avançadas no painel Configurações de execução para abrir o modal Executar configurações de segurança. No modal, use os controles deslizantes para ajustar o nível de filtragem de conteúdo por categoria de segurança:
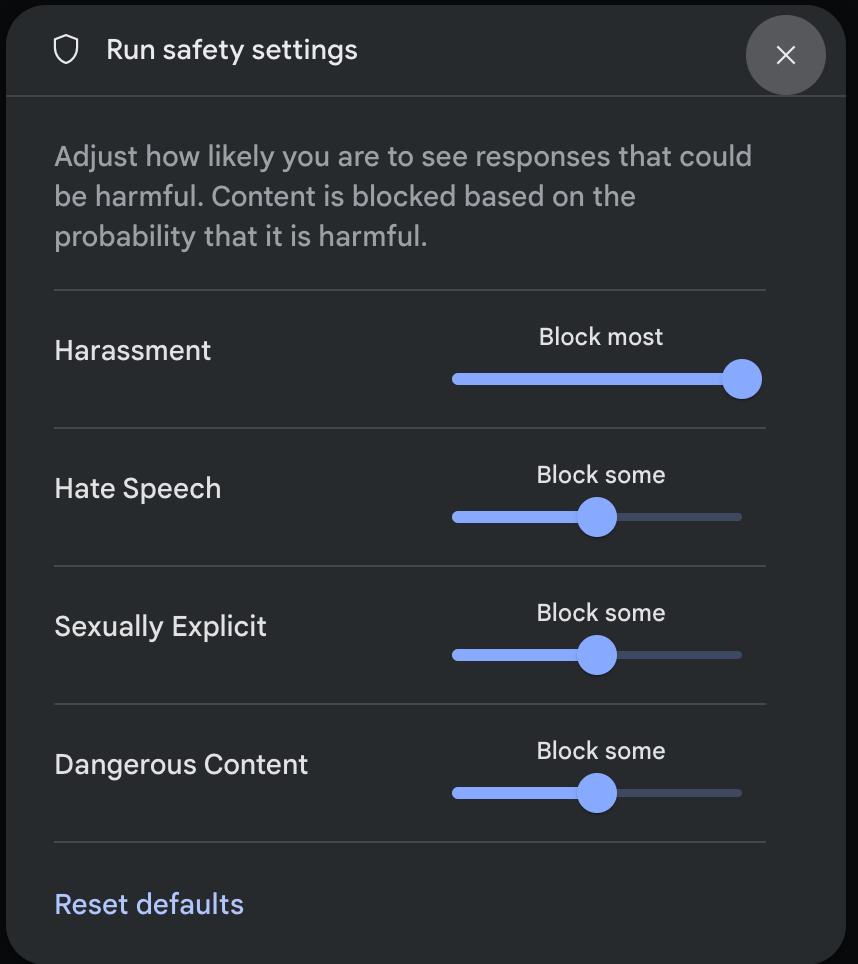
Quando você envia uma solicitação (por exemplo, fazendo uma pergunta ao modelo), uma mensagem Conteúdo bloqueado aparece se o conteúdo da solicitação for bloqueado. Para mais detalhes, mantenha o ponteiro sobre o texto Conteúdo bloqueado para ver a categoria e a probabilidade da classificação de dano.
Exemplos de código
O snippet de código a seguir mostra como definir as configurações de segurança na chamada de
GenerateContent. Isso define o limite da categoria de discurso de ódio (HARM_CATEGORY_HATE_SPEECH). Definir essa categoria como
BLOCK_LOW_AND_ABOVE bloqueia qualquer conteúdo com probabilidade baixa ou alta de
ser discurso de ódio. Para entender as configurações de limite, consulte Filtragem de segurança por solicitação.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
Próximas etapas
- Consulte a referência da API para saber mais sobre a API completa.
- Consulte as diretrizes de segurança para uma visão geral das considerações de segurança ao desenvolver com LLMs.
- Saiba mais sobre como avaliar a probabilidade e a gravidade com a equipe da Jigsaw.
- Saiba mais sobre os produtos que contribuem para soluções de segurança, como a API Perspective. * Você pode usar essas configurações de segurança para criar um classificador de toxicidade. Consulte o exemplo de classificação para começar.