
Utilisation de processeurs spécialisés tels que des GPU, des NPU ou des DSP pour le matériel peut améliorer considérablement les performances d'inférence (jusqu'à 10 fois plus vite (inférence dans certains cas) et l'expérience utilisateur de votre application Android compatible avec le ML application. Cependant, compte tenu de la variété du matériel et des pilotes que vos utilisateurs peuvent choisir la configuration d'accélération matérielle optimale pour chaque appareil peut être difficile. De plus, l'activation de la mauvaise configuration appareil peut nuire à l'expérience utilisateur en raison d'une latence élevée ou, dans de rares cas, les erreurs d'exécution ou les problèmes de précision provoqués par des incompatibilités matérielles.
Le service d'accélération pour Android est une API qui vous aide à choisir
une configuration d'accélération matérielle optimale pour l'appareil d'un utilisateur donné et votre
.tflite, tout en minimisant le risque d'erreur d'exécution ou de problèmes de justesse.
Le service d'accélération évalue différentes configurations d'accélération sur l'utilisateur en exécutant des analyses comparatives d'inférence internes avec votre système LiteRT du modèle. Ces tests s'exécutent généralement en quelques secondes, en fonction du modèle. Vous pouvez exécuter les analyses comparatives une fois sur chaque appareil de chaque utilisateur avant l'inférence. mettre en cache le résultat et l'utiliser pendant l'inférence. Ces benchmarks sont exécutés hors processus ; ce qui réduit le risque de plantages de votre application.
Fournissez votre modèle, des échantillons de données et les résultats attendus (entrées "golden" et résultats) et le service d'accélération exécute une inférence TFLite interne pour vous fournir des recommandations matérielles.
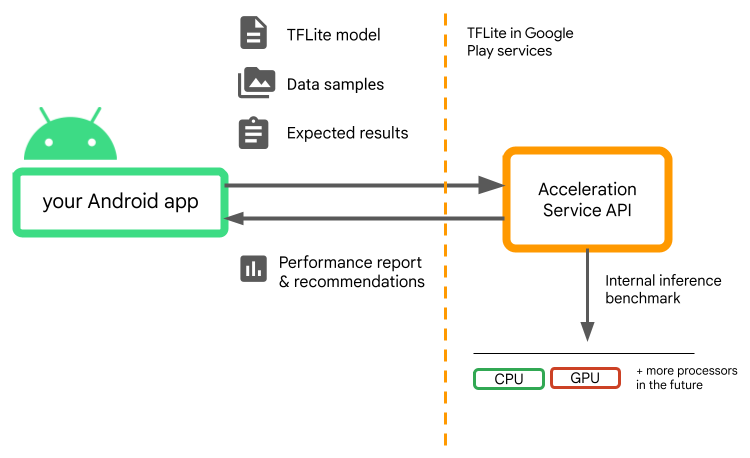
Le service d'accélération fait partie de la pile de ML personnalisée d'Android et fonctionne avec LiteRT dans les services Google Play
Ajouter les dépendances à votre projet
Ajoutez les dépendances suivantes au fichier build.gradle de votre application:
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.5.0-beta01"
L'API du service d'accélération fonctionne avec LiteRT dans Google Play Services. Si vous n'utilisez pas encore l'environnement d'exécution LiteRT fourni par les services Play, vous devrez mettre à jour vos dependencies.
Utiliser l'API Acceleration Service
Pour utiliser le service d'accélération, commencez par créer la configuration d'accélération
à évaluer pour votre modèle (par exemple, un GPU avec OpenGL). Créez ensuite un
configuration de validation avec votre modèle, quelques exemples de données et
la sortie du modèle. Enfin, appelez validateConfig() en transmettant à la fois votre
la configuration de l'accélération et de la validation.

Créer des configurations d'accélération
Les configurations d'accélération sont des représentations des configurations matérielles qui sont traduits en délégués pendant l'exécution. Le service d'accélération utilisera ensuite ces configurations en interne pour effectuer des inférences de test.
Pour le moment, le service d'accélération vous permet d'évaluer le GPU (converties en délégué de GPU pendant la durée d'exécution) avec le GpuAccelerationConfig et l'inférence CPU (avec CpuAccelerationConfig). Nous nous efforçons de permettre à davantage de délégués d'accéder à d'autres matériels dans le à venir.
Configuration de l'accélération GPU
Créez une configuration d'accélération GPU comme suit:
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
Vous devez spécifier si votre modèle utilise une quantification avec
setEnableQuantizedInference()
Configuration de l'accélération du processeur
Créez l'accélération du processeur comme suit:
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
Utilisez le
setNumThreads()
permettant de définir le nombre de threads à utiliser pour évaluer le CPU
l'inférence.
Créer des configurations de validation
Les configurations de validation vous permettent de définir la manière Service permettant d'évaluer les inférences Vous les utiliserez pour transmettre les éléments suivants:
- des échantillons d'entrée,
- les résultats attendus,
- de validation de la justesse.
Veillez à fournir des exemples d'entrées pour lesquels vous attendez de bonnes performances votre modèle (également appelés échantillons "golden").
Créez un
ValidationConfig
avec
CustomValidationConfig.Builder
comme suit:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
Spécifiez le nombre d'échantillons dorés avec
setBatchSize()
Transmettre les entrées de vos échantillons clés à l'aide de
setGoldenInputs()
Fournissez le résultat attendu pour l'entrée transmise avec
setGoldenOutputs()
Vous pouvez définir une durée d'inférence maximale avec setInferenceTimeoutMillis()
(5 000 ms par défaut). Si l'inférence dure plus longtemps
que le temps que vous avez défini,
la configuration sera rejetée.
Vous pouvez également créer un AccuracyValidator personnalisé
comme suit:
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
Veillez à définir une logique de validation adaptée à votre cas d'utilisation.
Notez que si les données de validation sont déjà intégrées à votre modèle, vous pouvez utiliser
EmbeddedValidationConfig
Générer des sorties de validation
Les sorties de référence sont facultatives. Tant que vous fournissez ces entrées,
Le service d'accélération peut générer en interne les sorties clés. Vous pouvez également
définir la configuration d'accélération utilisée pour générer ces résultats clés
nous appelons setGoldenConfig():
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
Valider la configuration de l'accélération
Une fois que vous avez créé une configuration d'accélération et une configuration de validation, vous pouvez les évaluer pour votre modèle.
Assurez-vous que l'environnement d'exécution LiteRT avec les services Play est correct initialisé et que le délégué de GPU est disponible pour l'appareil en exécutant la commande suivante:
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
Instanciez AccelerationService.
en appelant AccelerationService.create().
Vous pouvez ensuite valider la configuration d'accélération de votre modèle en appelant
validateConfig():
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
Vous pouvez également valider plusieurs configurations en appelant
validateConfigs()
et en transmettant un objet Iterable<AccelerationConfig> en tant que paramètre.
validateConfig() renvoie une
Task<ValidatedAccelerationConfigResult>
depuis les services Google Play
l'API Task, qui active
des tâches asynchrones.
Pour obtenir le résultat de l'appel de validation, ajoutez un
addOnSuccessListener()
.
Utiliser une configuration validée dans votre interpréteur
Après avoir vérifié si ValidatedAccelerationConfigResult est renvoyé dans
est valide, vous pouvez définir la configuration validée en tant que configuration d'accélération
pour que votre interprète appelle interpreterOptions.setAccelerationConfig().
Mise en cache de la configuration
Il est peu probable que la configuration d'accélération optimale pour votre modèle change le
l'appareil. Une fois que vous avez une configuration d'accélération satisfaisante,
doit les stocker sur l'appareil et laisser votre application les récupérer et les utiliser pour
créer votre InterpreterOptions lors des sessions suivantes au lieu de
exécuter une autre validation. Les méthodes serialize() et deserialize() dans
ValidatedAccelerationConfigResult assurent le processus de stockage et de récupération
plus facile.
Exemple d'application
Pour examiner une intégration en situation du service d'accélération, consultez la application exemple.
Limites
Le service d'accélération présente actuellement les limites suivantes:
- Seules les configurations d'accélération du processeur et du GPU sont acceptées pour le moment.
- Elle n'est compatible qu'avec LiteRT dans les services Google Play, et vous ne pouvez pas si vous utilisez la version intégrée de LiteRT.
- Le SDK du service d'accélération n'est compatible qu'avec les niveaux d'API 22 et supérieurs.
Mises en garde
Veuillez lire attentivement les mises en garde suivantes, surtout si vous prévoyez pour utiliser ce SDK en production:
Avant de quitter la version bêta et de publier la version stable pour le l'API du service d'accélération, nous allons publier un nouveau SDK pouvant avoir différences par rapport à la version bêta actuelle. Pour continuer à utiliser service d'accélération, vous devez migrer vers ce nouveau SDK et transmettre une mise à jour rapide de votre application. Ne pas le faire peut causer des dysfonctionnements il est possible que le SDK bêta ne soit plus compatible avec les services Google Play après un certain temps.
Rien ne garantit qu'une fonctionnalité spécifique L'API Service ou l'API dans son ensemble seront accessibles à tous. Il peuvent rester en version bêta pour une durée indéterminée, être arrêtées ou combinées à d'autres dans des packages conçus pour des publics de développeurs spécifiques. Un peu avec l'API Acceleration Service ou l'API entière finiront par être en disponibilité générale, mais il n'y a pas de calendrier fixe pour cette étape.
Conditions d'utilisation et règles de confidentialité
Conditions d'utilisation
L'utilisation des API du service d'accélération est soumise aux Conditions d'utilisation des API Google
d'assistance.
De plus, les API Acceleration Service sont actuellement en version bêta.
Aussi, en l'utilisant, vous reconnaissez les problèmes potentiels décrits dans les
Mises en garde ci-dessus et vous reconnaissez que le service d'accélération ne peut pas
fonctionne toujours comme spécifié.
Confidentialité
Lorsque vous utilisez les API du service d'accélération, le traitement des données d'entrée (par exemple,
images, vidéos, texte) s'effectue intégralement sur l'appareil et le service d'accélération
n'envoie pas ces données aux serveurs Google. Vous pouvez donc utiliser nos API
pour traiter les données d'entrée qui ne doivent pas quitter l'appareil.
Les API du service d'accélération peuvent contacter les serveurs Google de temps en temps dans
pour recevoir des corrections de bugs, des mises à jour de modèles et un accélérateur matériel
des informations sur la compatibilité. Les API du service d'accélération envoient aussi des métriques
les performances et l'utilisation
des API de votre appli à Google. Google utilise
ces données métriques pour mesurer les performances, déboguer, gérer et améliorer les API,
et détecter les usages abusifs ou abusifs, comme décrit plus en détail dans nos Règles de confidentialité
Règlement.
Vous êtes tenu d'informer les utilisateurs de votre application du traitement par Google
des données des métriques du service d'accélération, conformément à la législation applicable.
Les données que nous recueillons comprennent les éléments suivants:
- Informations sur l'appareil (fabricant, modèle, version de l'OS et build) les accélérateurs matériels de ML (GPU et DSP) disponibles. Utilisé pour les diagnostics et et l'analyse de l'utilisation.
- Informations sur l'application (nom du package / ID du bundle, version de l'application) Utilisation les diagnostics et les analyses d'utilisation.
- Configuration de l'API (format d'image et résolution, par exemple). Utilisation les diagnostics et les analyses d'utilisation.
- Type d'événement (initialisation, téléchargement du modèle, mise à jour, exécution, détection, par exemple) Utilisé pour les diagnostics et les analyses d'utilisation.
- Codes d'erreur. Utilisé pour les diagnostics.
- Métriques de performances Utilisé pour les diagnostics.
- Identifiants par installation qui n'identifient pas de manière unique un utilisateur ou un appareil physique. Utilisé pour le fonctionnement de la configuration et de l'utilisation à distance analyse.
- Adresses IP de l'expéditeur de la requête réseau. Utilisé pour la configuration à distance de l'infrastructure. Les adresses IP collectées sont conservées temporairement.
Assistance et commentaires
Vous pouvez envoyer vos commentaires et obtenir de l'aide via l'outil Issue Tracker de TensorFlow. Veuillez signaler tout problème ou toute demande d'assistance via le modèle de problème pour LiteRT dans les services Google Play.