
使用专用处理器(如 GPU、NPU 或 DSP)作为硬件 可以显著提高推理性能(最多可提升至原先的 10 倍) 以及支持机器学习的 Android 设备的用户体验 应用。不过,考虑到用户可能会使用各种各样的硬件和驱动程序, 为每个用户的设备选择最佳硬件加速配置 可能并非易事此外,在服务器上启用错误的配置 设备可能会由于延迟时间较长(在极少数情况下) 运行时错误或由硬件不兼容引起的准确性问题。
Acceleration Service for Android 是一个 API,可以帮助您选择
最佳硬件加速配置,适用于给定用户设备和您的
.tflite 模型,同时最大限度地降低运行时错误或准确率问题的风险。
加速服务为用户评估不同的加速配置 使用 LiteRT 运行内部推理基准测试, 模型。这些测试运行通常会在几秒钟内完成,具体取决于您的 模型。在推断之前,您可以在每个用户设备上运行一次基准测试 缓存结果并在推理期间使用该结果。这些基准测试运行的是 进程外从而最大限度地降低应用发生崩溃的风险。
提供模型、数据样本和预期结果(“黄金”输入和 输出),而加速服务将运行内部 TFLite 推断 以为您提供硬件建议。
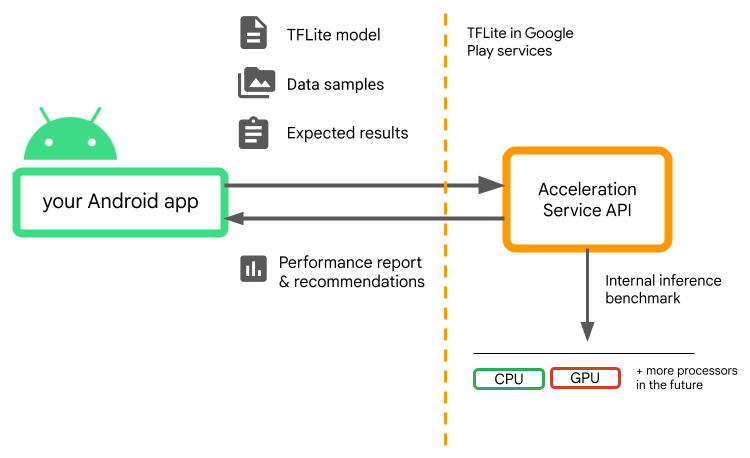
Acceleration Service 是 Android 自定义机器学习堆栈的一部分,可与 Google Play 服务中的 LiteRT。
将依赖项添加到项目中
将以下依赖项添加到应用的 build.gradle 文件:
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.5.0-beta01"
Acceleration Service API 可与 Google Play 中的 LiteRT 结合使用 服务。如果您 尚未使用通过 Play 服务提供的 LiteRT 运行时, 需要更新dependencies。
如何使用 Acceleration Service API
如需使用加速服务,请先创建加速配置
(例如支持 OpenGL 的 GPU)。然后创建一个
使用您的模型、一些示例数据和预期的
模型输出。最后调用 validateConfig(),同时传递
加速配置和验证配置。

创建加速配置
加速配置是硬件配置的表示形式 系统会在执行期间将其转换为委托 然后,加速服务会在内部使用这些配置 以便执行测试推断。
目前,你可以借助加速服务 配置(在执行期间转换为 GPU 代理) 替换为 GpuAccelerationConfig 和 CPU 推理(使用 CpuAccelerationConfig)。 我们正在努力支持更多受托人在 。
GPU 加速配置
按如下方式创建 GPU 加速配置:
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
您必须指定模型是否使用
setEnableQuantizedInference()。
CPU 加速配置
按如下方式创建 CPU 加速:
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
使用
setNumThreads()
方法定义要用于评估 CPU 的线程数
推理。
创建验证配置
通过验证配置,您可以定义如何您希望加速 用于评估推理的服务。您将使用它们来传递:
- 输入样本,
- 预期输出,
- 准确率验证逻辑。
请务必提供您期望获得良好性能的输入样本 模型(也称为“黄金”样本)。
创建
ValidationConfig
替换为
CustomValidationConfig.Builder
如下所示:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
指定
setBatchSize()。
使用以下代码传递黄金样本的输入:
setGoldenInputs()。
为通过 传递的输入提供预期输出
setGoldenOutputs()。
您可以使用 setInferenceTimeoutMillis() 定义推理时间上限
(默认为 5000 毫秒)。如果推断用时比您定义的时间长,
配置将被拒绝
您还可以根据需要创建自定义 AccuracyValidator
如下所示:
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
请务必定义适合您的用例的验证逻辑。
请注意,如果验证数据已嵌入到模型中,您可以使用
EmbeddedValidationConfig。
生成验证输出
黄金输出是可选的,只要您提供黄金输入,
加速服务可以在内部生成黄金输出。您还可以
定义用于生成这些黄金输出的加速配置,
调用 setGoldenConfig():
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
验证 Acceleration 配置
创建加速配置和验证配置后 来为您的模型评估它们。
确保支持 Play 服务的 LiteRT 运行时正确无误 通过运行以下命令,确保 GPU 代理可用于设备:
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
实例化 AccelerationService
通过调用 AccelerationService.create() 启动。
然后,您可以通过调用
validateConfig():
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
您还可以通过调用
validateConfigs()
并将 Iterable<AccelerationConfig> 对象作为参数传递。
validateConfig()将返回
Task<ValidatedAccelerationConfigResult>
来自 Google Play 服务
Task API,可让您
异步任务
要获取验证调用的结果,请将
addOnSuccessListener()
回调。
在解释器中使用经过验证的配置
在检查 ValidatedAccelerationConfigResult 是否在
回调有效,那么您可以将经过验证的配置设置为加速配置
。interpreterOptions.setAccelerationConfig()
配置缓存
模型的最佳加速配置不太可能在
。收到令人满意的加速配置后
都应该将其存储在设备上,然后让应用程序检索和使用
请在以下会话期间创建InterpreterOptions,而不是
运行另一个验证。serialize() 和 deserialize() 方法(位于
ValidatedAccelerationConfigResult让存储和检索过程
。
示例应用
如需了解加速服务的原地集成,请查看 示例应用。
限制
加速服务目前存在以下限制:
- 目前仅支持 CPU 和 GPU 加速配置。
- 它在 Google Play 服务中仅支持 LiteRT,您无法 如果您使用的是捆绑版本的 LiteRT,请使用此方法。
- Acceleration Service SDK 仅支持 API 级别 22 及更高级别。
注意事项
请仔细查看以下注意事项,尤其是当您 在生产环境中使用此 SDK:
在退出 Beta 版和发布稳定版之前, Acceleration Service API 之后,我们将发布一个新 SDK, 与当前 Beta 版的不同之处。若要继续使用 您需要迁移到这个新的 SDK 并推送 及时更新至您的应用否则可能会导致应用无法正常运行, Beta 版 SDK 可能 一段时间。
我们并不保证 Acceleration 中的特定功能 服务 API 或整个 API 将全面推出。它 可能会无限期地保持 Beta 版、被关闭或与其他 将这些功能整合到面向特定开发者群体设计的软件包中。部分 与 Acceleration Service API 集成的功能或整个 API 本身 最终会正式发布,但没有针对 这个。
条款和隐私权
服务条款
使用 Acceleration Service API 时需遵守 Google API 条款
服务。
此外,加速服务 API 目前为 Beta 版
因此,使用此服务即表示您确认已知晓
并承认加速服务可能无法
始终按指定方式执行
隐私权
在使用 Acceleration Service API 时,
图片、视频、文字)全部在设备端发生,而加速服务
不会将该数据发送到 Google 服务器。因此,您可以使用我们的 API
用于处理不应离开设备的输入数据。
在
以便接收问题修复、更新的模型和硬件加速器等
兼容性信息。Acceleration Service API 还会发送
您应用中 API 的性能和利用率。Google 使用
这些指标数据来衡量性能、调试、维护和改进 API
并检测滥用或滥用行为,如我们的隐私权
政策。
您有责任将 Google 的处理情况告知应用用户
的加速服务指标数据。
我们收集的数据包括:
- 设备信息(例如制造商、型号、操作系统版本和版本号)和 可用的机器学习硬件加速器(GPU 和 DSP)。用于诊断和 使用情况分析
- 应用信息(软件包名称 / 软件包 ID、应用版本)。用途 和使用情况分析
- API 配置(例如图片格式和分辨率)。用途 和使用情况分析
- 事件类型(例如初始化、下载模型、更新、运行、检测)。 用于诊断和使用情况分析。
- 错误代码。用于诊断。
- 效果指标。用于诊断。
- 每次安装使用的标识符不能唯一标识用户或 实体设备用于执行远程配置和使用操作 分析。
- 网络请求发送者的 IP 地址。用于远程配置 诊断。收集的 IP 地址会暂时保留。
支持与反馈
您可以通过 TensorFlow 问题跟踪器提供反馈和获取支持。 请使用 问题模板 。