
El uso de procesadores especializados, como GPU, NPU o DSP para hardware La aceleración puede mejorar drásticamente el rendimiento de la inferencia (hasta 10 veces más rápido inferencia en algunos casos) y la experiencia del usuario de tu dispositivo Android y mantener la integridad de su aplicación. Sin embargo, debido a la variedad de hardware y controladores, los usuarios podrían y elige la configuración de aceleración de hardware óptima para las necesidades dispositivo puede ser un desafío. Además, habilitar la configuración incorrecta en un puede causar una mala experiencia del usuario debido a la alta latencia o, en errores de tiempo de ejecución o problemas de precisión causados por incompatibilidades de hardware.
Acceleration Service para Android es una API que te ayuda a elegir
configuración de aceleración de hardware óptima para un dispositivo de usuario determinado y tu
.tflite y, al mismo tiempo, minimiza el riesgo de errores en el tiempo de ejecución o problemas de precisión.
El servicio de aceleración evalúa diferentes configuraciones de aceleración en el usuario a través de la ejecución de comparativas de inferencia internas con tu LiteRT un modelo de responsabilidad compartida. Estas ejecuciones de prueba suelen completarse en pocos segundos, dependiendo de un modelo de responsabilidad compartida. Puedes ejecutar las comparativas una vez en cada dispositivo del usuario antes de la inferencia almacenar en caché el resultado y usarlo durante la inferencia. Estas comparativas se ejecutan fuera del proceso; lo que minimiza el riesgo de fallas en tu app.
Proporciona tu modelo, muestras de datos y resultados esperados (entradas “doradas” y resultados) y el servicio de aceleración ejecutará una inferencia interna de TFLite para ofrecerte recomendaciones de hardware.
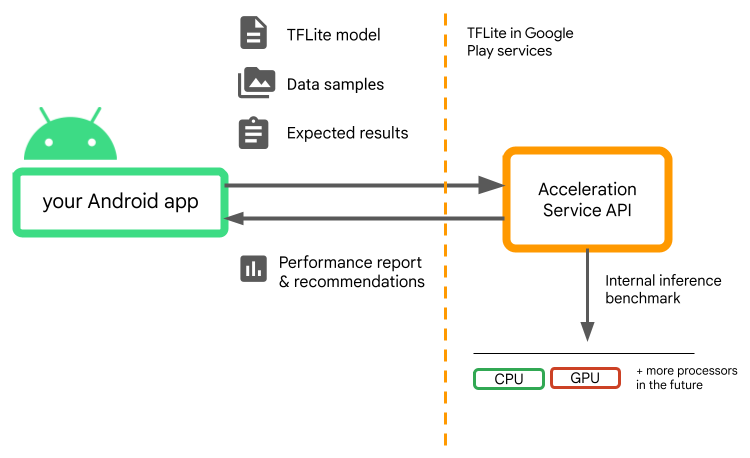
Acceleration Service forma parte de la pila de AA personalizada de Android y funciona con LiteRT en los Servicios de Google Play.
Agrega las dependencias a tu proyecto.
Agrega las siguientes dependencias al archivo build.gradle de tu aplicación:
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.5.0-beta01"
La API de Acceleration Service funciona con LiteRT en Google Play. Servicios Si aún no usan el entorno de ejecución LiteRT proporcionado a través de los Servicios de Play, deberás actualizar tus dependencies.
Cómo usar la API de Acceleration Service
Para usar el servicio de aceleración, crea la configuración de aceleración
que quieres evaluar para tu modelo (p. ej., GPU con OpenGL). Luego, crea
configuración de validación con tu modelo, algunos datos de muestra y los
salida del modelo. Por último, llama a validateConfig() y pasa ambos
de aceleración y validación.

Cómo crear configuraciones de aceleración
Las configuraciones de aceleración son representaciones de las configuraciones de hardware que se traducen en delegados durante el tiempo de ejecución. Luego, el servicio de aceleración usará estos parámetros de configuración internamente para realizar inferencias de prueba.
En este momento, el servicio de aceleración permite evaluar las GPU parámetros de configuración (se convierten en delegados de GPU durante el tiempo de ejecución) con el GpuAccelerationConfig y la inferencia de CPU (con CpuAccelerationConfig). Estamos trabajando para que más delegados puedan acceder a otro hardware en el en el futuro.
Configuración de aceleración de GPU
Crea una configuración de aceleración de GPU de la siguiente manera:
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
Debe especificar si su modelo usa cuantización con
setEnableQuantizedInference()
Configuración de aceleración de la CPU
Crea la aceleración de CPU de la siguiente manera:
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
Usa el
setNumThreads()
para definir la cantidad de subprocesos que quieres usar para evaluar la CPU
la inferencia.
Crear configuraciones de validación
Los parámetros de configuración de validación te permiten definir cómo deseas que se aplique la Servicio para evaluar inferencias. Las usarás para pasar lo siguiente:
- muestras de entrada,
- los resultados esperados,
- la lógica de validación de exactitud.
Asegúrate de proporcionar muestras de entrada de las que esperas un buen rendimiento para tu modelo (también conocidas como muestras “doradas”).
Crea un
ValidationConfig
con
CustomValidationConfig.Builder
de la siguiente manera:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
Especifica la cantidad de muestras doradas con
setBatchSize()
Pasa las entradas de tus muestras doradas con el siguiente
setGoldenInputs()
Proporciona el resultado esperado de la entrada que se pasó con
setGoldenOutputs()
Puedes definir un tiempo máximo de inferencia con setInferenceTimeoutMillis().
(5,000 ms de forma predeterminada). Si la inferencia lleva más tiempo que el tiempo definido,
se rechazará la configuración.
De manera opcional, también puedes crear un AccuracyValidator personalizado
de la siguiente manera:
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
Asegúrate de definir una lógica de validación que funcione para tu caso de uso.
Ten en cuenta que si los datos de validación ya están incorporados en el modelo, puedes usar
EmbeddedValidationConfig
Genera resultados de validación
Los resultados dorados son opcionales y, siempre que proporciones entradas doradas, el
El servicio de aceleración puede generar internamente los resultados dorados. También puedes
definir la configuración de aceleración que se usa para generar estas salidas doradas
Llamando a setGoldenConfig():
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
Valida la configuración de la aceleración
Una vez que hayas creado una configuración de aceleración y una de validación, puedes evaluarlas para tu modelo.
Asegúrate de que el entorno de ejecución de LiteRT con Servicios de Play esté funcionando correctamente se inicialice y que el delegado de la GPU esté disponible para el dispositivo ejecutando lo siguiente:
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
Crea una instancia de AccelerationService.
llamando a AccelerationService.create()
Luego, puedes validar la configuración de aceleración para tu modelo llamando
validateConfig():
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
También puedes validar varios parámetros de configuración llamando
validateConfigs()
y pasar un objeto Iterable<AccelerationConfig> como parámetro.
validateConfig()mostrará un
Task<ValidatedAccelerationConfigResult>
desde los Servicios de Google Play
API de Task que permite
las tareas asíncronas.
Para obtener el resultado de la llamada de validación, agrega un
addOnSuccessListener()
devolución de llamada.
Usa la configuración validada en tu intérprete
Después de verificar si ValidatedAccelerationConfigResult se mostró en el
es válida, puedes establecer la configuración validada como una configuración de aceleración.
para tu intérprete llamando a interpreterOptions.setAccelerationConfig().
Almacenamiento en caché de la configuración
Es poco probable que la configuración de aceleración óptima para tu modelo cambie en
el dispositivo. Una vez que recibes una configuración de aceleración satisfactoria,
debe almacenarla en el dispositivo y dejar que tu aplicación la recupere y la use para
crea tu InterpreterOptions durante las siguientes sesiones en lugar de
ejecutando otra validación. Los métodos serialize() y deserialize() en
ValidatedAccelerationConfigResult realizan el proceso de almacenamiento y recuperación
y fácil de usar.
Aplicación de ejemplo
Para revisar una integración in situ del Acceleration Service, consulta el app de ejemplo.
Limitaciones
Actualmente, el servicio de aceleración tiene las siguientes limitaciones:
- Por el momento, solo se admiten las configuraciones de aceleración de CPU y GPU.
- Solo es compatible con LiteRT en los Servicios de Google Play y no puedes utilízalo si usas la versión integrada de LiteRT.
- El SDK de Acceleration Service solo es compatible con el nivel de API 22 y versiones posteriores.
Advertencias
Revisa atentamente las siguientes advertencias, especialmente si estás planificando para usar este SDK en producción:
Antes de salir del programa Beta y lanzar la versión estable, API de Acceleration Service, publicaremos un nuevo SDK que puede tener diferencias con respecto a la versión beta actual. Para seguir usando de Acceleration, deberás migrar a este SDK nuevo y enviar la actualización de la app de manera oportuna. De lo contrario, se podrían producir fallas es posible que el SDK beta ya no sea compatible con Google Play Services después de algún tiempo.
No hay garantía de que un atributo específico de la La API del servicio o la API en su totalidad estarán disponibles de manera general. Integra pueden permanecer en Beta de forma indefinida, cerrarse o combinarse con otras en paquetes diseñados para públicos de desarrolladores específicos. Algunos con la API de Acceleration Service o toda la API con el tiempo estarán disponibles de forma general, pero no hay un cronograma fijo esto.
Condiciones y privacidad
Condiciones del Servicio
El uso de las APIs de Acceleration Service está sujeto a las Condiciones del Servicio de las APIs de Google
Service.
Además, las APIs de Acceleration Service se encuentran actualmente en versión beta.
y, como tal, al usarlo, reconoces los posibles problemas descritos en las
Advertencias anteriores y reconoce que el Servicio de aceleración no podrá
funcionen siempre según lo especificado.
Privacidad
Cuando usas las APIs de Acceleration Service, el procesamiento de los datos de entrada (p.ej.,
imágenes, video o texto) se realiza en el dispositivo, y el Servicio de aceleración
no envía esos datos a los servidores de Google. Por ello, puedes usar nuestras APIs
para procesar datos de entrada que no deben salir del dispositivo.
Las APIs de Acceleration Service pueden comunicarse con los servidores de Google ocasionalmente
para recibir correcciones de errores, modelos actualizados y acelerador de hardware
información de compatibilidad. Las APIs de Acceleration Service también envían métricas sobre
el rendimiento y el uso de las APIs
de tu app en Google. Google usa
estos datos de métricas para medir el rendimiento,
depurar, mantener y mejorar las APIs
y detectar usos inadecuados o abusos, tal como se describe en nuestra sección
Política.
Usted es responsable de informar a los usuarios de la aplicación sobre el procesamiento que realiza Google.
de los datos de métricas del Servicio de aceleración según lo exija la ley aplicable.
Los datos que recopilamos incluyen lo siguiente:
- Información del dispositivo (como el fabricante, el modelo, la versión del SO y la compilación) aceleradores de hardware para AA disponibles (GPU y DSP). Se usa para diagnósticos y estadísticas de uso.
- Información de la aplicación (nombre del paquete / ID del paquete, versión de la aplicación) Se usa para las estadísticas de uso y diagnóstico.
- Configuración de la API (como el formato y la resolución de imagen) Se usa para las estadísticas de uso y diagnóstico.
- Tipo de evento (como inicialización, descarga del modelo, actualización, ejecución y detección). Se usa para diagnósticos y estadísticas de uso.
- Códigos de error Se usa para diagnósticos.
- Métricas de rendimiento Se usa para diagnósticos.
- Los identificadores por instalación que no identifican de manera inequívoca a un usuario o dispositivo físico. Se usa para la operación de configuración y uso remotos de análisis de datos en la nube.
- Direcciones IP del remitente de la solicitud de red. Se usa para la configuración remota diagnóstico. Las direcciones IP recopiladas se conservan temporalmente.
Asistencia y comentarios
Puedes enviar comentarios y obtener asistencia a través de la Herramienta de seguimiento de errores de TensorFlow. Informa problemas y solicitudes de asistencia a través de la plantilla de problemas para LiteRT en los Servicios de Google Play.