Gemini kann verschiedene Arten von Eingabedaten gleichzeitig verarbeiten, darunter Text, Bilder und Audio.
In diesem Leitfaden erfahren Sie, wie Sie mit der Files API mit Mediendateien arbeiten. Die grundlegenden Vorgänge sind für Audiodateien, Bilder, Videos, Dokumente und andere unterstützte Dateitypen gleich.
Eine Anleitung zu Datei-Prompts finden Sie im Abschnitt Leitfaden zu Datei-Prompts.
Datei hochladen
Sie können die Files API verwenden, um eine Mediendatei hochzuladen. Verwenden Sie immer die Files API, wenn die Gesamtgröße der Anfrage (einschließlich der Dateien, des Text-Prompts, der Systemanweisungen usw.) größer als 100 MB ist. Für PDF-Dateien gilt ein Limit von 50 MB.
Mit dem folgenden Code wird eine Datei hochgeladen und dann in einem Aufruf von interactions.create verwendet.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{"type": "audio", "uri": myfile.uri, "mime_type": myfile.mime_type}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const myfile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mpeg" },
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Describe this audio clip" },
{ type: "audio", uri: myfile.uri, mime_type: myfile.mimeType }
]
});
console.log(interaction.output_text);
}
await main();
Ok
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
defer client.Files.Delete(ctx, file.Name)
interaction, err := client.Interactions.Create(ctx, "gemini-3.5-flash", &genai.InteractionRequest{
Input: []interface{}{
genai.NewPartFromFile(*file),
genai.NewPartFromText("Describe this audio clip"),
},
}, nil)
if err != nil {
log.Fatal(err)
}
// Print the model's text response
for _, step := range interaction.Steps {
if step.Type == "model_output" {
for _, part := range step.Content {
if part.Type == "text" {
fmt.Println(part.Text)
}
}
}
}
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "${BASE_URL}/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D "${tmp_header_file}" \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now create an interaction using the Interactions API
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{"type": "audio", "uri": '$file_uri', "mime_type": "'${MIME_TYPE}'"}
]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".outputs[] | select(.type == \"text\") | .text" response.json
Metadaten für eine Datei abrufen
Sie können prüfen, ob die API die hochgeladene Datei erfolgreich gespeichert hat, und die zugehörigen Metadaten abrufen, indem Sie files.get aufrufen.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
file_name = myfile.name
myfile = client.files.get(name=file_name)
print(myfile)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const myfile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mpeg" },
});
const fileName = myfile.name;
const fetchedFile = await client.files.get({ name: fileName });
console.log(fetchedFile);
}
await main();
Ok
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
gotFile, err := client.Files.Get(ctx, file.Name)
if err != nil {
log.Fatal(err)
}
fmt.Println("Got file:", gotFile.Name)
REST
# file_info.json was created in the upload example
name=$(jq -r ".file.name" file_info.json)
# Get the file of interest to check state
curl https://generativelanguage.googleapis.com/v1beta/$name \
-H "x-goog-api-key: $GEMINI_API_KEY" > file_info.json
# Print some information about the file you got
name=$(jq -r ".name" file_info.json)
echo name=$name
file_uri=$(jq -r ".uri" file_info.json)
echo file_uri=$file_uri
Hochgeladene Dateien auflisten
Mit dem folgenden Code wird eine Liste aller hochgeladenen Dateien abgerufen:
Python
from google import genai
client = genai.Client()
print('My files:')
for f in client.files.list():
print(' ', f.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const listResponse = await client.files.list({ config: { pageSize: 10 } });
for await (const file of listResponse) {
console.log(file.name);
}
}
await main();
Ok
for file, err := range client.Files.All(ctx) {
if err != nil {
log.Fatal(err)
}
fmt.Println(file.Name)
}
REST
echo "My files: "
curl "https://generativelanguage.googleapis.com/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY"
Hochgeladene Dateien löschen
Dateien werden nach 48 Stunden automatisch gelöscht. Sie können eine hochgeladene Datei auch manuell löschen:
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
client.files.delete(name=myfile.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const myfile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mpeg" },
});
const fileName = myfile.name;
await client.files.delete({ name: fileName });
}
await main();
Ok
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
client.Files.Delete(ctx, file.Name)
REST
curl --request "DELETE" https://generativelanguage.googleapis.com/v1beta/$name \
-H "x-goog-api-key: $GEMINI_API_KEY"
Nutzungsinformationen
Mit der Files API können Sie Mediendateien hochladen und mit ihnen interagieren. Mit der Files API können Sie bis zu 20 GB Dateien pro Projekt speichern. Die maximale Größe pro Datei beträgt 2 GB. Dateien werden 48 Stunden lang gespeichert. Während dieser Zeit können Sie die API verwenden, um Metadaten zu den Dateien abzurufen, aber die Dateien nicht herunterladen. Die Files API ist in allen Regionen, in denen die Gemini API verfügbar ist, kostenlos verfügbar.
Strategien für Dateiprompts
In diesem Abschnitt finden Sie Anleitungen und Best Practices für die Verwendung von Mediendateien mit Prompts für die Gemini API.
Da Sie verschiedene Datentypen in Ihren Prompts verwenden können, sind Sie flexibler bei den Aufgaben, die Sie mit der Gemini API erledigen können. Sie können dem Modell zum Beispiel ein Foto von einem leckeren Gericht senden und es bitten, einen kurzen Blogbeitrag über das Gericht zu schreiben.
| Eingabeaufforderung | Antwort |
|
Schreibe einen kurzen, ansprechenden Blogbeitrag auf der Grundlage dieses Bildes. Er sollte eine Beschreibung der Mahlzeit auf dem Foto enthalten und über die Vorbereitung der Mahlzeit sprechen. 
|
Meal Prep ist eine gute Möglichkeit, Zeit und Geld zu sparen. Außerdem kann es dir helfen, dich gesünder zu ernähren. Dieses Gericht ist ein gutes Beispiel für eine gesunde und leckere Mahlzeit, die im Voraus zubereitet werden kann. Dieses Gericht besteht aus braunem Reis, geröstetem Gemüse und Hähnchen-Teriyaki. Der braune Reis ist ein gesundes und komplexes Kohlenhydrat, das dir langanhaltende Energie liefert. Das geröstete Gemüse ist eine gute Möglichkeit, deinen täglichen Bedarf an Vitaminen und Mineralstoffen zu decken, und das Hähnchen-Teriyaki ist eine köstliche und proteinreiche Option. Dieses Gericht ist auch einfach zuzubereiten. Koche einfach den braunen Reis, brate das Gemüse und koche das Hähnchen-Teriyaki. Sobald alles gekocht ist, verteile es auf Behälter für die Essenszubereitung und bewahre es im Kühlschrank auf. So kannst du dir an hektischen Morgen einfach einen Behälter schnappen. Wenn du auf der Suche nach einem gesunden und leckeren Gericht bist, das du im Voraus zubereiten kannst, ist dieses Gericht eine gute Wahl. Es ist reich an Nährstoffen und Geschmack und macht satt und zufrieden. Auf ein gesundes und leckeres Meal Prep! |
Wenn Sie Probleme haben, die gewünschte Ausgabe von Prompts zu erhalten, in denen Mediendateien verwendet werden, können Sie einige Strategien anwenden, um die gewünschten Ergebnisse zu erzielen. In den folgenden Abschnitten finden Sie Designansätze und Tipps zur Fehlerbehebung, mit denen Sie Prompts mit multimodaler Eingabe verbessern können.
Sie können Ihre multimodalen Prompts mit den folgenden Best Practices verbessern:
-
Grundlagen des Prompt-Designs
- Formulieren Sie spezifische Anweisungen: Stellen Sie klare und präzise Anweisungen bereit, die möglichst wenig Raum für Fehldeutungen lassen.
- Ein paar Beispiele zum Prompt hinzufügen: Verwenden Sie realistische Few-Shot-Beispiele, um zu veranschaulichen, was Sie erreichen möchten.
- Schritt für Schritt aufschlüsseln: Teilen Sie komplexe Aufgaben in überschaubare Unterziele auf und führen Sie das Modell durch den Prozess.
- Ausgabeformat angeben: Fordern Sie in dem Prompt an, dass die Ausgabe in dem gewünschten Format vorliegt, z. B. Markdown, JSON, HTML und mehr.
- Bild zuerst für Aufforderungen mit einem einzelnen Bild platzieren: Zwar kann Gemini Bild- und -Texteingaben in beliebiger Reihenfolge verarbeiten, für Aufforderungen mit einem einzelnen Bild kann es jedoch besser sein, wenn dieses Bild (oder Video) vor der Textaufforderung platziert wird. Verwenden Sie jedoch für Aufforderungen, die Bilder erfordern, die eng mit Texten verknüpft sein müssen, die am ehesten natürliche Reihenfolge.
-
Fehlerbehebung bei multimodalem Prompt
- Wenn das Modell aus dem relevanten Teil des Bildes keine Informationen bezieht:Geben Sie an, aus welchen Aspekte des Bildes der Prompt Informationen abrufen soll.
- Wenn die Modellausgabe zu allgemein ist (nicht genug auf die Bild-/Videoeingabe zugeschnitten) : Versuchen Sie zu Beginn des Prompts, das Modell um eine Beschreibung des Bildes oder Videos zu bitten, bevor Sie die Aufgabe beschreiben. oder bitten Sie das Modell, sich auf den Inhalt des Bildes zu beziehen.
- Fehlerbehebung, welcher Teil fehlgeschlagen ist:Bitten Sie das Modell, das Bild zu beschreiben, oder bitten Sie das Modell, seine Logik zu erläutern, um das ursprüngliche Verständnis des Modells zu messen.
- Wenn die Eingabeaufforderung zu halluzinierten Inhalten führt, sollten Sie die Temperatureinstellung verringern oder das Modell um kürzere Beschreibungen bitten, damit die Wahrscheinlichkeit geringer ist, dass zusätzliche Details angezeigt werden.
- Parameter für die Stichprobenerhebung optimieren:Experimentieren Sie mit verschiedenen Temperatureinstellungen und „Top-K“-Auswahlen, um die Kreativität des Modells anzupassen.
Machen Sie genaue Anweisungen
Prompts haben den größten Erfolg, wenn sie klar und detailliert sind. Wenn Sie eine bestimmte Ausgabe im Hinterkopf haben, sollten Sie diese Anforderung in den Prompt aufnehmen, damit Sie die gewünschte Ausgabe erhalten.
Wenn Sie für dieses Bild eines Flughafenboards die Anfrage an das Modell senden, nur „Dieses Bild beschreiben“ könnte es eine allgemeine Beschreibung generieren. Wenn das Modell die Zeit und die Stadt aus dem Bild parsen soll, können Sie diese Anfrage direkt in den Prompt einfügen.
| Prompt | Modellantwort |
|---|---|

Beschreiben Sie dieses Bild. |
Auf dem Bild ist eine Anzeige für Ankunfts- und Abflugfinfos für den Flughafen zu sehen. |
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
Parsen Sie die Uhrzeit und die Stadt vom Flughafenanzeige in dem Bild in eine Liste. |
Ein paar Beispiele hinzufügen
Das Gemini-Modell kann mehrere Eingaben akzeptieren, die es als Beispiele für das Verständnis der gewünschten Ausgabe verwenden kann. Wenn Sie diese Beispiele hinzufügen, kann das Modell die Muster leichter identifizieren und die Beziehung zwischen den angegebenen Bildern und Antworten auf das neue Beispiel anwenden. Dies wird auch als „Few-Shot“-Lernen bezeichnet.
Im folgenden Beispiel wird die ursprüngliche Ausgabe in Satzform geschrieben und enthält auch das Land (Brasilien). Angenommen, Sie möchten die Ausgabe in einem anderen Format oder Stil haben und nur die Stadt und nicht das Land benötigen. Wenn Sie Ihrer Prompt Few-Shot-Beispiele hinzufügen, können Sie das Modell so steuern, dass es antwortet, wie Sie es möchten.
| Eingabeaufforderung | Modellantwort |
|---|---|
 Bestimmen Sie die Stadt und das Wahrzeichen. |
Die Sehenswürdigkeit ist die Cristo Redentor-Statue in Rio de Janeiro, Brasilien. |
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Bestimmen Sie die Stadt und das Wahrzeichen. 
|
Stadt: Rom, Sehenswürdigkeit: Kolosseum. |

|
Stadt: Peking, Sehenswürdigkeit: Verbotene Stadt |
|
|
Stadt: Rio de Janeiro, Sehenswürdigkeit: Cristo Redentor-Statue |
Schritt-für-Schritt-Anleitung
Bei komplexen Aufgaben wie Aufgaben, die sowohl visuelles Verständnis als auch Logik erfordern, kann es hilfreich sein, die Aufgabe in kleinere, einfachere Schritte aufzuteilen. Alternativ kann es auch sinnvoll sein, wenn Sie das Modell in Ihrem Prompt direkt bitten, schrittweise zu denken.
| Prompt | Modellantwort |
|---|---|

Wann habe ich kein Toilettenpapier mehr? |
Bald sind nur noch 3 Rollen übrig. |
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
|
Mathematische Aufgaben oder andere Arten von Wortproblemen sind gute Kandidaten dafür, das Modell zu bitten, Schritt für Schritt zu denken.
| Eingabeaufforderung | Antwort |
|---|---|
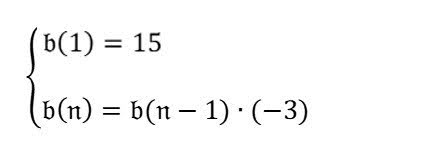
Was ist der vierte Begriff in der Sequenz? |
-135 |
Die Antwort des Modells ist falsch. Zum Verbessern Sie können das Modell beispielsweise bitten, das Problem zu parsen, bevor es den Prompt beantwortet.
| Eingabeaufforderung | Antwort |
|---|---|
|
Parsen Sie zuerst die Formel im Bild. Beantworte dann anhand der Formel: „Was ist der vierte Begriff in der Folge?“. |
Klicken Sie, um das Ergebnis zu maximieren$$ b(n) = b(n-1) * (-3) $$ $$ b(1) = 15 $$
Daher ist der vierte Begriff in der Sequenz -405. |
Diese Modellantwort ist korrekt. Wenn Sie die Antwort jetzt noch optimieren möchten, können Sie das Modell bitten, schrittweise zu denken.
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Was ist der vierte Begriff in der Sequenz? Detaillierte Anleitung |
Der erste Begriff ist 15. Der zweite Begriff ist b(1) * (-3) = 15 * (-3) = -45. Der dritte Begriff ist b(2) * (-3) = -45 * (-3) = 135. Der vierte Begriff ist b(3) * (-3) = 135 * (-3) = -405. |
Ausgabeformat angeben
Ein häufiges Problem besteht darin, dass die Modellausgabe in einem bestimmten Format vorliegen muss (z.B. Markdown, JSON, HTML), insbesondere wenn die Modellausgabe von einer nachgelagerten Aufgabe aufgenommen werden muss. Sie können versuchen, eine Ausgabe in diesem Format zu erstellen, indem Sie das Modell im Prompt dazu anweisen. Hier sind zwei Beispiele:
| Prompt | Modellantwort |
|---|---|
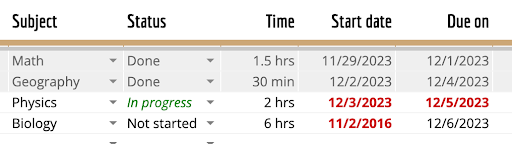
Die Tabelle in diesem Bild in das Markdown-Format parsen |
```none | Fach | Status | Zeit | Startdatum | Fällig am | | ------- | ------ | ---- | ---------- | ------ | | Mathematik | Fertig | 1,5 Std. | 29.11.2023 | 1.12.2023 | | Geografie | Fertig | 30 Min. | 2.12.2023 | 4.12.2023 | | Physik | In Bearbeitung | 2 Std. | 3.12.2023 | 5.12.2023 | | Biologie | Nicht gestartet | 6 Std. | 2.11.2016 | 6.12.2023 | ``` |
| Eingabeaufforderung | Modellantwort |
|---|---|

Geben Sie eine Liste aller folgenden Attribute an: Zutaten, Art der Küche, vegetarisch oder nicht, im JSON-Format |
```json { "ingredients": [ "rice", "shrimp", "clams", "mussels", "peas", "tomatoes", "onions", "garlic", "olive oil", "paprika", "salt", "pepper" ], "type of cuisine": "Spanish", "vegetarian": false } ``` |
Bild zuerst für Aufforderungen mit einem einzelnen Bild platzieren
Gemini kann Bilder und Text in beliebiger Reihenfolge innerhalb einer Eingabeaufforderung interpretieren. Die Platzierung eines einzelnen Bildes vor der Textaufforderung kann jedoch zu besseren Ergebnissen führen. In den folgenden Beispielen sehen Sie, dass das Bild in jedem Prompt zuerst vor dem Text steht.
Fehlerbehebung bei multimodalem Prompt
Möglicherweise müssen Sie Probleme mit Ihrem Prompt beheben, wenn Sie keine hilfreiche Antwort erhalten. Hier sind einige Strategien, die Sie ausprobieren können:
Wenn das Modell keine Informationen aus dem relevanten Bildteil abruft
Um eine spezifischere Antwort zu erhalten, können Sie angeben, aus welchen Aspekten des Bildes Informationen herausgegeben werden sollen.
| Prompt | Modellantwort |
|---|---|

Wie viele Tage halten diese Windeln für ein Baby? |
Die Windel halten 198 Tage, bevor sie aufgebraucht sind. |
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Wie lange halten diese Windeln? Verwenden Sie das auf dem Feld angezeigte Gewicht, um das Alter des Kindes zu bestimmen. Verwenden Sie dann die Gesamtzahl der Windeln im Feld. Teilen Sie die Gesamtzahl durch die Anzahl der Windeln, die das Kind pro Tag benötigt. |
Die Verpackung enthält 198 Windeln. Die Verpackung besagt, dass die Windel für ein Kind mit einem Gewicht von 22-37 lbs gedacht sind. Das durchschnittliche Kind in diesem Gewichtbereich ist wahrscheinlich zwischen 1 und 2 Jahren alt. Eine Zweijährige braucht in der Regel sechs Windeln pro Tag, daher halten sie etwa 33 Tage (198/6). |
Wenn die Modellausgabe zu allgemein und nicht ausreichend auf die Bildeingabe zugeschnitten ist
Damit das Modell seine Antwort auf das Bild bzw. die Bilder anpassen kann, bitten Sie es, das Bild zu beschreiben, bevor das Modell die Logik ausführt.
| Prompt | Modellantwort |
|---|---|



Was haben diese Bilder gemeinsam? |
Alle vier Bilder sind Beispiele für Bilder im Querformat. |
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Beschreiben Sie zuerst im Detail, was die einzelnen Bilder enthalten. Was haben diese Bilder gemeinsam? |
Das erste Bild zeigt eine Person, die einen Koffer verpackt, das zweite zeigt einen leeren Flur in einem Einkaufszentrum, das dritte Bild zeigt einen Rolle von Toilettenpapier und das vierte Bild ein dunkles und stürmisches Meer. Die Gemeinsamkeiten zwischen diesen Bildern sind, dass sie alle Beispiele für Grenzbereiche sind. Grenzbereich sind Orte oder Situationen, die zwischen zwei anderen Orten oder Situationen liegen. Sie sind oft durch ein Gefühl von Unsicherheit oder Mehrdeutigkeit gekennzeichnet. Das erste Bild zeigt die Person, die zwischen der zu Hause und einer Reise steht. Die zweite Abbildung zeigt den Flur zwischen zwei Geschäften. Das dritte Bild ist Toilettenpapier, das ein Bad darstellen kann. Ein Badezimmer ist ein Übergangsraum zwischen privaten und öffentlichen Bereichen. Es ist ein Ort, an dem wir uns darauf vorbereiten, die Außenwelt zu betreten und zu verlassen. Das vierte Bild zeigt das Meer zwischen Ruhe und Sturm. Grenzbereiche können sowohl interessant als auch unübersichtlich sein. Sie können ein Ort für einen neuen Anfang oder ein Ort mit Endungen sein. Sie können ein Ort der Reflexion oder ein Handlungsort sein. |
Sie können auch versuchen, das Modell explizit auffordern, auf den Inhalt des Bildes zu verweisen.
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Was haben diese Bilder gemeinsam? In der Antwort auf den Inhalt der Bildern verweisen |
Alle Bilder beziehen sich auf Reisen. Das erste Bild zeigt eine Person, die einen Koffer packt, das zweite einen leeren Flur in einem Einkaufszentrum, das dritte einen Stapel Toilettenpapier und das vierte ein dunkles und stürmisches Meer. Diese Bilder beziehen sich alle auf Reisen, da es alles ist, was Nutzer auf Reisen brauchen oder verwenden. Das erste Bild zeigt eine Person, die einen Koffer packt. Das ist etwas, was Menschen vor einer Reise tun. Das zweite Bild zeigt einen leeren Flur in einem Einkaufszentrum, in dem Nutzer häufig Dinge für ihre Reisen kaufen. Das dritte Bild zeigt einen Stapel von Toilettenpapier, das Menschen häufig auf Reisen verwenden. Das vierte Bild zeigt ein dunkles und stürmisches Meer. Dies ist eines der Dinge, auf die Menschen häufig auf Reisen treffen. |
Dieselben Tipps gelten auch für die Creative-Ausgabe von Bildern. Im folgenden Beispiel mit dem Kaninchen kann es hilfreich sein, das Modell explizit aufzufordern, Aspekte aus dem Bild in das Modell aufzunehmen.
| Prompt | Modellantwort |
|---|---|

Kannst du mir ein Gedicht zu diesem Bild schreiben? |
Kleines Kaninchen, so weich und braun, Du knabberst am Gras, so grün und süß, |
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Können Sie mir ein beschreibendes und pathetisches Gedicht zu diesem Bild schreiben und den Standort einbeziehen? |
Kleines Kaninchen im Grün, Ist es der blaue Ozean, Kleines Wesen sage mir, Vielleicht ist es die Unermesslichkeit des Seins, Ich frage mich, was ist wohl dein Traum, Was auch immer es ist, kleines Kaninchen, |
Fehlerbehebung, welcher Teil der Prompt fehlgeschlagen ist
Es ist möglicherweise schwierig zu erkennen, ob eine Eingabeaufforderung fehlgeschlagen ist, weil das Modell nicht verstanden hat, mit welchem Bild zu beginnen ist oder wenn es das Bild verstanden hat, nicht die richtigen logischen Schritte ausgeführt hat. Um zwischen diesen Logiken zu unterscheiden, bitten Sie das Modell, den Inhalt des Bildes zu beschreiben.
Wenn das Modell im folgenden Beispiel mit Snacks antwortet, die bei Kombination mit Tee (z.B. Popcorn) überraschend sind, können Sie zuerst eine Fehlerbehebung durchführen, um festzustellen, ob das Modell richtig erkannt hat, dass das Bild Tee zeigt.
| Prompt | Prompt zur Fehlerbehebung |
|---|---|

Welchen Snack kann ich in einer Minute machen, der dazu gut passe würde? |
Beschreiben Sie den Inhalt des Bildes. |
Eine andere Strategie besteht darin, das Modell um seine Logik zu bitten. So können Sie gegebenenfalls ermitteln, welcher Teil der Logik aufgeschlüsselt wurde.
| Prompt | Prompt zur Fehlerbehebung |
|---|---|
|
Welchen Snack kann ich in einer Minute machen, der dazu gut passe würde? |
Welchen Snack kann ich in einer Minute machen, der dazu gut passe würde? Bitte erläutere, weshalb du sie erreicht bzw. nicht erreicht hast. |
Nächste Schritte
- Probieren Sie aus, eigene multimodale Prompts mit Google AI Studio zu erstellen.
- Informationen zur Verwendung der Gemini Files API zum Hochladen von Media-Dateien und zum Einbinden in Ihre Prompts finden Sie in den Leitfäden Vision, Audio und Dokumentverarbeitung.
- Weitere Informationen zum Prompt-Design, z. B. zum Anpassen von Sampling-Parametern, finden Sie auf der Seite Prompt-Strategien.