Gemini Robotics-ER 1.6 هو نموذج للرؤية واللغة (VLM) يتيح استخدام إمكانات Gemini في مجال الروبوتات. وهو مصمّم لإجراء عمليات الاستدلال المتقدّم في العالم المادي، ما يتيح للروبوتات تفسير البيانات المرئية المعقّدة وإجراء عمليات الاستدلال المكاني وتخطيط الإجراءات من خلال الأوامر باللغة الطبيعية.
يُرجى العِلم أنّه إذا كنت تستخدم Gemini Robotics-ER 1.5، يمكنك البدء في استخدام النموذج 1.6
من خلال استبدال اسم النموذج من model="gemini-robotics-er-1.5-preview"
إلى model="gemini-robotics-er-1.6-preview" في طلب البيانات من واجهة برمجة التطبيقات.
الميزات والمزايا الرئيسية:
- الاستقلالية المحسّنة: يمكن للروبوتات التفكير والتكيّف والاستجابة للتغييرات في البيئات المفتوحة.
- التفاعل باللغة الطبيعية: يسهّل استخدام الروبوتات من خلال إتاحة إسناد مهام معقّدة باستخدام اللغة الطبيعية.
- تنظيم المهام: يحلّل الأوامر باللغة الطبيعية إلى مهام فرعية، ويتكامل مع أدوات التحكّم والسلوكيات الحالية للروبوتات من أجل إكمال المهام الطويلة الأمد.
- إمكانات متعدّدة الاستخدامات: تحديد الأجسام والتعرّف عليها، وفهم العلاقات بين الأجسام، وتخطيط عمليات الإمساك والمسارات، وتفسير المشاهد الديناميكية
يوضّح هذا المستند وظيفة النموذج ويقدّم لك عدة أمثلة تسلّط الضوء على إمكانات النموذج المستندة إلى الذكاء الاصطناعي.
إذا أردت البدء على الفور، يمكنك تجربة النموذج في Google AI Studio.
تجربة الميزة في Google AI Studio
الأمان
على الرغم من أنّ Gemini Robotics-ER 1.6 مصمَّم مع مراعاة السلامة، تقع على عاتقك مسؤولية الحفاظ على بيئة آمنة حول الروبوت. قد ترتكب نماذج الذكاء الاصطناعي التوليدي أخطاء، وقد تتسبّب الروبوتات المادية في إلحاق الضرر. تُعدّ السلامة إحدى أولوياتنا، لذا نعمل حاليًا على إجراء أبحاث مكثّفة في مجال توفير السلامة عند استخدام نماذج الذكاء الاصطناعي التوليدي مع الروبوتات في العالم الحقيقي. لمزيد من المعلومات، يُرجى الانتقال إلى صفحة أمان الروبوتات في Google DeepMind.
البدء: العثور على عناصر في مشهد
يوضّح المثال التالي حالة استخدام شائعة للروبوتات. يوضّح هذا المثال كيفية تمرير صورة وطلب نصي إلى النموذج باستخدام طريقة generateContent للحصول على قائمة بالعناصر المحدّدة مع نقاطها الثنائية الأبعاد المقابلة.
يعرض النموذج نقاطًا للعناصر التي تم تحديدها في صورة، ويعرض الإحداثيات الثنائية الأبعاد العادية والتصنيفات الخاصة بها.
يمكنك استخدام هذا الناتج مع واجهة برمجة تطبيقات خاصة بالروبوتات أو استدعاء نموذج رؤية ولغة وإجراء (VLA) أو أي دوال أخرى يحدّدها المستخدم تابعة لجهات خارجية لإنشاء إجراءات يمكن للروبوت تنفيذها.
Python
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
REST
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
سيكون الناتج مصفوفة JSON تحتوي على عناصر، كل منها يتضمّن point
(إحداثيات [y, x] عادية) وlabel يحدّد العنصر.
JSON
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
في ما يلي مثال على كيفية عرض هذه النقاط:

آلية العمل
يتيح الإصدار 1.6 من Gemini Robotics للروبوتات فهم السياق والعمل في العالم المادي باستخدام ميزة "الفهم المكاني". تتلقّى هذه النماذج مدخلات على شكل صور أو فيديوهات أو ملفات صوتية، بالإضافة إلى طلبات مكتوبة بلغة طبيعية، وذلك بهدف:
- فهم العناصر وسياق المشهد: يحدّد هذا الخيار العناصر ويشرح علاقتها بالمشهد، بما في ذلك إمكانات استخدامها.
- فهم تعليمات المهام: تفسير المهام المقدَّمة بلغة طبيعية، مثل "العثور على الموزة"
- الاستدلال المكاني والزمني: فهم تسلسلات الإجراءات وكيفية تفاعل الكائنات مع مشهد بمرور الوقت
- توفير ناتج منظَّم: تعرض هذه الدالة إحداثيات (نقاط أو مربّعات محيطة) تمثّل مواقع العناصر.
ويتيح ذلك للروبوتات "رؤية" و "فهم" البيئة المحيطة بها آليًا.
تتسم Gemini Robotics-ER 1.6 أيضًا بقدرتها على تنفيذ المهام بشكل مستقل، ما يعني أنّها تستطيع تقسيم المهام المعقّدة (مثل "وضع التفاحة في الوعاء") إلى مهام فرعية لتنفيذ المهام الطويلة الأمد:
- ترتيب المهام الفرعية: يحلّل الأوامر إلى تسلسل منطقي من الخطوات.
- استدعاء الدوال/تطبيق الرموز البرمجية: تنفيذ الخطوات من خلال استدعاء دوال/أدوات الروبوت الحالية أو تنفيذ الرمز الذي تم إنشاؤه
يمكنك الاطّلاع على مزيد من المعلومات حول طريقة عمل ميزة استدعاء الدوال في Gemini على صفحة "استدعاء الدوال".
استخدام ميزانية التفكير مع Gemini Robotics-ER 1.6
يوفّر Gemini Robotics-ER 1.6 ميزانية مرنة للتفكير تتيح لك التحكّم في المفاضلة بين وقت الاستجابة والدقة. بالنسبة إلى مهام الفهم المكاني، مثل رصد العناصر، يمكن للنموذج تحقيق أداء عالٍ بميزانية تفكير صغيرة. تستفيد مهام الاستدلال الأكثر تعقيدًا، مثل العد وتقدير الوزن، من ميزانية تفكير أكبر. يتيح لك ذلك تحقيق التوازن بين الحاجة إلى ردود بزمن انتقال منخفض ونتائج عالية الدقة للمهام الأكثر صعوبة.
لمزيد من المعلومات عن ميزانيات التفكير، اطّلِع على صفحة الإمكانات الأساسية التفكير.
الاستدلال المكاني العادي
توضّح الأمثلة التالية مهام الإدراك الآلي والاستدلال المكاني باستخدام طلبات باللغة الطبيعية، بدءًا من الإشارة إلى العناصر والعثور عليها في صورة وصولاً إلى تخطيط المسارات. لتبسيط الأمور، تم تقليل مقتطفات الرموز البرمجية في هذه الأمثلة لعرض الطلب واستدعاء واجهة برمجة التطبيقات generate_content فقط.
يمكنك العثور على الرمز الكامل القابل للتنفيذ بالإضافة إلى أمثلة إضافية في كتاب وصفات الروبوتات.
الإشارة إلى العناصر
يُعدّ توجيه الروبوتات إلى العناصر والعثور عليها في الصور أو لقطات الفيديو من حالات الاستخدام الشائعة لنماذج الرؤية واللغة (VLMs) في مجال الروبوتات. يطلب المثال التالي من النموذج العثور على عناصر محدّدة داخل صورة وعرض إحداثياتها.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
سيكون الناتج مشابهًا لمثال "البدء"، وهو ملف JSON يحتوي على إحداثيات العناصر التي تم العثور عليها وتصنيفاتها.
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

استخدِم الطلب التالي لكي يفسّر النموذج الفئات المجردة مثل "الفاكهة" بدلاً من الكائنات المحددة، ويحدّد جميع مثيلاتها في الصورة.
Python
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
يمكنك الانتقال إلى صفحة فهم الصور للاطّلاع على تقنيات أخرى لمعالجة الصور.
تتبُّع العناصر في فيديو
يمكن لـ Gemini Robotics-ER 1.6 أيضًا تحليل لقطات الفيديو لتتبُّع العناصر بمرور الوقت. يمكنك الاطّلاع على مدخلات الفيديو للحصول على قائمة بتنسيقات الفيديو المتوافقة.
في ما يلي الطلب الأساسي المستخدَم للعثور على عناصر محدّدة في كل إطار يحلّله النموذج:
Python
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
تعرض النتيجة قلمًا وكمبيوترًا محمولاً يتم تتبّعهما في جميع لقطات الفيديو.
![]()
للاطّلاع على الرمز الكامل القابل للتنفيذ، راجِع كتاب وصفات الروبوتات.
رصد العناصر والمربّعات المحيطة
بالإضافة إلى النقاط الفردية، يمكن للنموذج أيضًا عرض مربّعات حدود ثنائية الأبعاد، ما يوفّر منطقة مستطيلة تحيط بالكائن.
يطلب هذا المثال مربّعات إحاطة ثنائية الأبعاد للعناصر القابلة للتحديد على جدول. يتم توجيه النموذج إلى حصر الناتج بـ 25 عنصرًا وتسمية مثيلات متعددة بشكل فريد.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
يعرض ما يلي المربّعات التي تمّت إعادتها من النموذج.
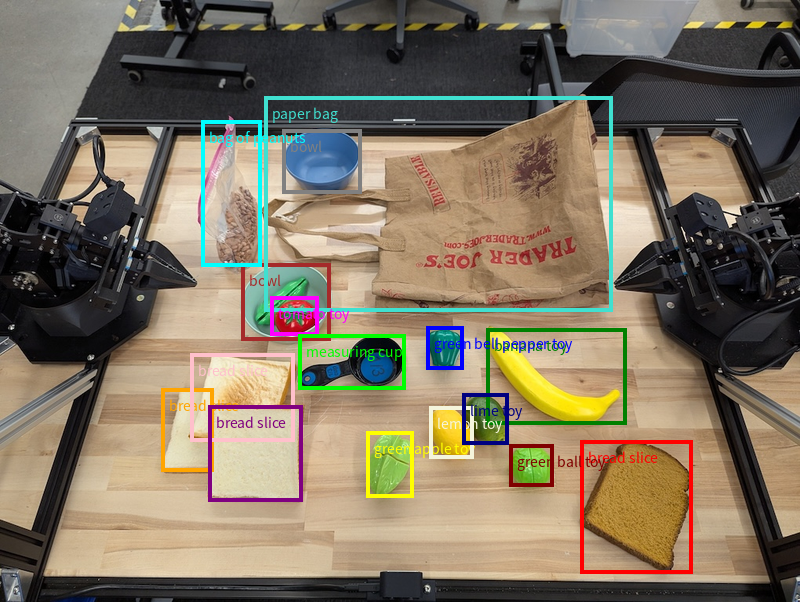
للاطّلاع على الرمز الكامل القابل للتنفيذ، راجِع كتاب الطبخ الخاص بالروبوتات. تتضمّن صفحة فهم الصور أيضًا أمثلة إضافية على المهام المرئية، مثل رصد العناصر وأمثلة على المربّعات المحيطة.
المسارات
يمكن لنموذج Gemini Robotics-ER 1.6 إنشاء تسلسلات من النقاط التي تحدّد مسارًا، ما يفيد في توجيه حركة الروبوت.
يطلب هذا المثال مسارًا لتحريك قلم أحمر إلى منظم، بما في ذلك نقطة البداية وسلسلة من النقاط الوسيطة.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
الردّ هو مجموعة من الإحداثيات التي تصف مسار القلم الأحمر الذي يجب أن يتّبعه لإكمال مهمة تحريكه إلى أعلى المنظِّم:
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

إمكانات بالذكاء الاصطناعي الوكيل
توضّح الأمثلة التالية الاستدلال الآلي المتقدّم باستخدام إمكانات الذكاء الاصطناعي الوكيل في النموذج، وتحديدًا تنفيذ الرمز البرمجي. في هذه الحالات، يمكن للنموذج أن يقرر كتابة رمز Python وتنفيذه لمعالجة الصور (مثل التكبير أو الاقتصاص أو التدوير) من أجل إزالة الغموض أو تحسين الدقة قبل تقديم الإجابة.
رصد العناصر (التكبير والاقتصاص)
يوضّح المثال التالي كيفية استخدام تنفيذ الرمز البرمجي لتكبير صورة واقتصاصها من أجل عرضها بشكل أوضح عند رصد العناصر وعرض المربّعات المحيطة بها.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
ستكون مخرجات النموذج مشابهة لما يلي:
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
يعرض ما يلي المربّعات التي تمّت إعادتها من النموذج.

قراءة مقياس تناظري وتطبيق المنطق
يوضّح المثال التالي كيفية استخدام النموذج لقراءة مقياس تناظري وإجراء عمليات حسابية متعلقة بالوقت. يستخدم تعليمات النظام لفرض إخراج JSON.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
في ما يلي مثال على إدخال صورة.

ستكون مخرجات النموذج مشابهة لما يلي:
Time Response: {
"hours": 12,
"minutes": 44
}
قياس السائل في وعاء
يوضّح المثال التالي كيفية استخدام تنفيذ الرمز البرمجي لقراءة مقياس واحتساب مستوى السائل كنسبة مئوية.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
في ما يلي صورة مكبّرة للإدخال.

قراءة العلامات على لوحة الدوائر الكهربائية
يوضّح المثال التالي كيفية استخدام تنفيذ الرمز البرمجي لقراءة نص على شريحة لوحة إلكترونية، ما يتيح للنموذج تكبير الصورة واقتصاصها وتدويرها حسب الحاجة.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
في ما يلي صورة مكبّرة للإدخال.

التعليق التوضيحي على الصور
يوضّح المثال التالي كيفية استخدام تنفيذ الرمز البرمجي لإضافة تعليقات توضيحية إلى صورة (مثل رسم أسهم لتعليمات التخلص) وعرض الصورة المعدَّلة.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
في ما يلي مثال على إدخال صورة.

ستكون مخرجات النموذج مشابهة لما يلي:
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
التنسيق
يمكن لروبوت Gemini Robotics-ER 1.6 إجراء تخطيط المهام والاستدلال المكاني على مستوى أعلى، واستنتاج الإجراءات أو تحديد المواقع المثالية استنادًا إلى الفهم السياقي لتنفيذ المهام الطويلة الأمد.
توفير مساحة للكمبيوتر المحمول
يوضّح هذا المثال كيف يمكن لـ Gemini Robotics-ER التفكير في مساحة معيّنة. يطلب الطلب من النموذج تحديد العنصر الذي يجب نقله لإتاحة مساحة لعنصر آخر.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
تحتوي الاستجابة على إحداثيات ثنائية الأبعاد للعنصر الذي يجيب عن سؤال المستخدم، وهو في هذه الحالة العنصر الذي يجب تحريكه لإفساح المجال لجهاز كمبيوتر محمول.
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

تجهيز وجبة غداء
يمكن للنموذج أيضًا تقديم تعليمات للمهام المتعددة الخطوات والإشارة إلى الكائنات ذات الصلة بكل خطوة. يوضّح هذا المثال كيف يخطّط النموذج لسلسلة من الخطوات لتعبئة حقيبة الغداء.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
تتضمّن الاستجابة لهذا الطلب مجموعة من التعليمات المفصَّلة حول كيفية تعبئة حقيبة غداء من الصورة التي تم إدخالها.
الصورة المدخَلة

مخرجات النموذج
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
استدعاء واجهة برمجة تطبيقات مخصّصة لبرامج الروبوت
يوضّح هذا المثال تنسيق المهام باستخدام واجهة برمجة تطبيقات مخصّصة للروبوت. وتتضمّن واجهة برمجة تطبيقات وهمية مصمَّمة لتنفيذ عملية الالتقاط والوضع. المهمة هي التقاط مكعّب أزرق ووضعه في وعاء برتقالي:

كما هو الحال مع الأمثلة الأخرى في هذه الصفحة، يتوفّر الرمز الكامل القابل للتنفيذ في كتاب وصفات الروبوتات.
الخطوة الأولى هي تحديد موقع كل من العنصرين باستخدام الطلب التالي:
Python
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
يتضمّن ردّ النموذج الإحداثيات العادية للمكعب والوعاء:
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
يستخدم هذا المثال واجهة برمجة تطبيقات الروبوت الوهمية التالية:
Python
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
الخطوة التالية هي استدعاء سلسلة من دوال واجهة برمجة التطبيقات مع المنطق اللازم لتنفيذ الإجراء. يتضمّن الطلب التالي وصفًا لواجهة برمجة التطبيقات الخاصة بالروبوت التي يجب أن يستخدمها النموذج عند تنسيق هذه المهمة.
Python
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
يوضّح ما يلي ناتجًا محتملاً للنموذج استنادًا إلى الطلب وواجهة برمجة التطبيقات الوهمية الخاصة بالروبوت. يتضمّن الناتج عملية التفكير في النموذج والمهام التي خطّط لها نتيجةً لذلك. ويعرض أيضًا ناتج استدعاءات وظائف الروبوت التي رتّبها النموذج معًا.
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
أفضل الممارسات
لتحسين أداء تطبيقات الروبوتات ودقتها، من المهم معرفة كيفية التفاعل مع نموذج Gemini بفعالية. يوضّح هذا القسم أفضل الممارسات والاستراتيجيات الرئيسية لصياغة الطلبات والتعامل مع البيانات المرئية وتنظيم المهام لتحقيق النتائج الأكثر موثوقية.
استخدِم لغة واضحة وبسيطة.
استخدام اللغة الطبيعية: تم تصميم نموذج Gemini لفهم اللغة الطبيعية المستخدمة في المحادثات. نظِّم طلباتك بطريقة واضحة من الناحية الدلالية وتعكس الطريقة التي يقدّم بها الشخص التعليمات بشكل طبيعي.
استخدام مصطلحات يومية: استخدِم لغة شائعة ويومية بدلاً من المصطلحات الفنية أو المتخصصة. إذا لم يستجب النموذج كما هو متوقّع لمصطلح معيّن، جرِّب إعادة صياغته باستخدام مرادف أكثر شيوعًا.
تحسين الإدخال المرئي
التكبير للحصول على التفاصيل: عند التعامل مع عناصر صغيرة أو يصعب تمييزها في لقطة أوسع، استخدِم وظيفة المربّع المحيط لعزل العنصر المطلوب. يمكنك بعد ذلك اقتصاص الصورة إلى هذا الجزء وإرسال الصورة الجديدة التي تم التركيز فيها إلى النموذج لإجراء تحليل أكثر تفصيلاً.
تجربة الإضاءة والألوان: يمكن أن تتأثر قدرة النموذج على الإدراك بظروف الإضاءة الصعبة والتباين الضعيف في الألوان.
قسِّم المشاكل المعقّدة إلى خطوات أصغر. ومن خلال معالجة كل خطوة أصغر على حدة، يمكنك توجيه النموذج للوصول إلى نتيجة أكثر دقة ونجاحًا.
تحسين الدقة من خلال الإجماع بالنسبة إلى المهام التي تتطلّب درجة عالية من الدقة، يمكنك توجيه طلب البحث إلى النموذج عدة مرات باستخدام الطلب نفسه. ومن خلال حساب متوسط النتائج التي تم عرضها، يمكنك التوصّل إلى "إجماع" يكون غالبًا أكثر دقة وموثوقية.
القيود
يجب مراعاة القيود التالية عند التطوير باستخدام Gemini Robotics-ER 1.6:
- حالة المعاينة: النموذج حاليًا في مرحلة المعاينة. قد تتغيّر واجهات برمجة التطبيقات والإمكانات، وقد لا تكون مناسبة للتطبيقات المهمة في مرحلة الإنتاج بدون إجراء اختبارات شاملة.
- زمن الاستجابة: يمكن أن تؤدي الطلبات المعقّدة أو المدخلات العالية الدقة أو
thinking_budgetالواسعة النطاق إلى زيادة أوقات المعالجة. - الهلوسات: مثل جميع النماذج اللغوية الكبيرة، يمكن أن "يهلوس" Gemini Robotics-ER 1.6 أحيانًا أو يقدّم معلومات غير صحيحة، خاصةً في ما يتعلّق بالطلبات الغامضة أو المدخلات غير المتوقّعة.
- الاعتماد على جودة الطلب: تعتمد جودة النتائج التي يقدّمها النموذج بشكل كبير على وضوح الطلب المُدخَل ومدى صلته بالموضوع. يمكن أن تؤدي الطلبات الغامضة أو السيئة التنظيم إلى نتائج غير مثالية.
- التكلفة الحسابية: يؤدي تشغيل النموذج، خاصةً مع إدخال فيديوهات أو
thinking_budgetعالية، إلى استهلاك موارد حسابية وتكبُّد تكاليف. يمكنك الاطّلاع على صفحة التفكير لمزيد من التفاصيل. - أنواع الإدخال: اطّلِع على المواضيع التالية لمعرفة تفاصيل حول القيود المفروضة على كل وضع.
إشعار الخصوصية
أنت تقرّ بأنّ النماذج المشار إليها في هذا المستند ("نماذج الروبوتات") تستخدم بيانات الفيديو والصوت لتشغيل الأجهزة وتحريكها وفقًا لتعليماتك. وبالتالي، يمكنك تشغيل "نماذج الروبوتات" بطريقة تؤدي إلى جمع بيانات من أشخاص يمكن التعرّف عليهم، مثل بيانات الصوت والصور والتشابه ("البيانات الشخصية")، من خلال "نماذج الروبوتات". إذا اخترت تشغيل "نماذج الروبوتات" بطريقة تجمع "البيانات الشخصية"، أنت توافق على عدم السماح لأي أشخاص يمكن التعرّف عليهم بالتفاعل مع "نماذج الروبوتات" أو التواجد في المنطقة المحيطة بها، إلا بعد إبلاغ هؤلاء الأشخاص بشكل كافٍ وموافقتهم على إمكانية تقديم بياناتهم الشخصية إلى Google واستخدامها من قِبلها على النحو الموضّح في "بنود الخدمة الإضافية لخدمة Gemini API" المتوفّرة على الرابط https://ai.google.dev/gemini-api/terms (المشار إليها باسم "البنود")، بما في ذلك وفقًا للقسم بعنوان "طريقة استخدام Google لبياناتك". ستضمن أنّ هذا الإشعار يسمح بجمع البيانات الشخصية واستخدامها على النحو الموضّح في "البنود"، وستبذل جهودًا معقولة تجاريًا للحدّ من جمع البيانات الشخصية وتوزيعها باستخدام تقنيات مثل تمويه الوجوه وتشغيل "نماذج الروبوتات" في مناطق لا تحتوي على أشخاص يمكن التعرّف عليهم إلى الحدّ الذي يمكن تنفيذه عمليًا.
الأسعار
للحصول على معلومات تفصيلية حول الأسعار والمناطق المتاحة، يُرجى الرجوع إلى صفحة الأسعار.
إصدارات النموذج
Robotics-ER 1.6 Preview
| الموقع | الوصف |
|---|---|
| رمز النموذج | gemini-robotics-er-1.6-preview |
| أنواع البيانات المتوافقة |
المدخلات النصوص والصور والفيديوهات والمحتوى الصوتي الناتج نص |
| حدود الرموز المميزة[*] |
الحدّ الأقصى لعدد الرموز المميزة التي يمكن إدخالها 131,072 الحدّ الأقصى لعدد الرموز المميزة الناتجة 65,536 |
| الإمكانات | غير متاح متاح متاح متاح متاح متاح متاح غير متاح غير متاح متاح متاح متاح متاح |
| خيارات الاستهلاك |
متاح متاح متاح |
| الإصدارات |
|
| آخر تعديل | ديسمبر 2025 |
| تاريخ آخر تحديث للبيانات | يناير 2025 |
الخطوات التالية
- استكشِف إمكانات أخرى وواصِل تجربة طلبات ومدخلات مختلفة لاكتشاف المزيد من تطبيقات Gemini Robotics-ER 1.6. اطّلِع على ملف Colab الخاص ببدء استخدام الروبوتات للاطّلاع على المزيد من الأمثلة.
- لمعرفة المزيد حول كيفية تصميم نماذج Gemini Robotics مع مراعاة الأمان، يُرجى الانتقال إلى صفحة أمان الروبوتات في Google DeepMind.
- يمكنك الاطّلاع على آخر الأخبار حول نماذج Gemini Robotics على صفحة Gemini Robotics المقصودة.