Gemini Robotics-ER 1.6 è un modello di visione-linguaggio (VLM) che porta le capacità agentiche di Gemini nella robotica. È progettato per il ragionamento avanzato nel mondo fisico, consentendo ai robot di interpretare dati visivi complessi, eseguire ragionamenti spaziali e pianificare azioni a partire da comandi in linguaggio naturale.
Tieni presente che se utilizzavi Gemini Robotics-ER 1.5, puoi iniziare a utilizzare il modello 1.6
sostituendo il nome del modello da model="gemini-robotics-er-1.5-preview"
a model="gemini-robotics-er-1.6-preview" nella chiamata API.
Funzionalità e vantaggi principali:
- Maggiore autonomia:i robot possono ragionare, adattarsi e rispondere ai cambiamenti in ambienti aperti.
- Interazione in linguaggio naturale:semplifica l'utilizzo dei robot consentendo l'assegnazione di attività complesse utilizzando il linguaggio naturale.
- Orchestrazione delle attività:scompone i comandi in linguaggio naturale in sottoattività e si integra con i controller e i comportamenti dei robot esistenti per completare attività a lungo termine.
- Funzionalità versatili: individua e identifica oggetti, comprende le relazioni tra gli oggetti, pianifica prese e traiettorie e interpreta scene dinamiche.
Questo documento descrive cosa fa il modello e ti guida attraverso diversi esempi che mettono in evidenza le capacità agentiche del modello.
Se vuoi iniziare subito, puoi provare il modello in Google AI Studio.
Sicurezza
Sebbene Gemini Robotics-ER 1.6 sia stato progettato pensando alla sicurezza, è tua responsabilità mantenere un ambiente sicuro intorno al robot. I modelli di AI generativa possono commettere errori e i robot fisici possono causare danni. La sicurezza è una priorità e rendere sicuri i modelli di AI generativa quando vengono utilizzati con la robotica del mondo reale è un'area attiva e critica della nostra ricerca. Per saperne di più, visita la pagina sulla sicurezza della robotica di Google DeepMind.
Per iniziare: trovare oggetti in una scena
L'esempio seguente mostra un caso d'uso comune della robotica. Mostra come
passare un'immagine e un prompt testuale al modello utilizzando il
metodo generateContent per ottenere un elenco di oggetti identificati con i relativi punti 2D.
Il modello restituisce i punti per gli elementi identificati in un'immagine, restituendo
le coordinate 2D normalizzate e le etichette.
Puoi utilizzare questo output con un'API di robotica o chiamare un modello vision-language-action (VLA) o qualsiasi altra funzione definita dall'utente di terze parti per generare azioni che un robot deve eseguire.
Python
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
REST
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
L'output sarà un array JSON contenente oggetti, ognuno con un point
(coordinate [y, x] normalizzate) e un label che identifica l'oggetto.
JSON
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
L'immagine seguente è un esempio di come possono essere visualizzati questi punti:

Come funziona
Gemini Robotics-ER 1.6 consente ai robot di contestualizzare e lavorare nel mondo fisico utilizzando la comprensione spaziale. Prende input di immagini/video/audio e prompt in linguaggio naturale per:
- Comprendere gli oggetti e il contesto della scena: identifica gli oggetti e ragiona sulla loro relazione con la scena, comprese le loro affordance.
- Comprendere le istruzioni delle attività: interpreta le attività date in linguaggio naturale, ad esempio "trova la banana".
- Ragionamento spaziale e temporale: comprendere le sequenze di azioni e il modo in cui gli oggetti interagiscono con una scena nel tempo.
- Fornisci output strutturato: restituisce le coordinate (punti o riquadri di delimitazione) che rappresentano le posizioni degli oggetti.
In questo modo, i robot possono "vedere" e "comprendere" il loro ambiente in modo programmatico.
Gemini Robotics-ER 1.6 è anche agentico, il che significa che può suddividere attività complesse (come "metti la mela nella ciotola") in sotto-attività per orchestrare attività a lungo termine:
- Sequenziazione delle attività secondarie: scompone i comandi in una sequenza logica di passaggi.
- Chiamate di funzione/Esecuzione del codice: esegue i passaggi chiamando le funzioni/gli strumenti del robot esistenti o eseguendo il codice generato.
Scopri di più su come funziona la chiamata di funzione con Gemini nella pagina Chiamata di funzione.
Utilizzo del budget di pensiero con Gemini Robotics-ER 1.6
Gemini Robotics-ER 1.6 ha un budget di ragionamento flessibile che ti consente di controllare i compromessi tra latenza e accuratezza. Per attività di comprensione spaziale come il rilevamento di oggetti, il modello può ottenere prestazioni elevate con un budget di pensiero ridotto. Le attività di ragionamento più complesse, come il conteggio e la stima del peso, traggono vantaggio da un budget di pensiero più ampio. In questo modo, puoi bilanciare la necessità di risposte a bassa latenza con risultati di alta precisione per le attività più complesse.
Per saperne di più sui budget di pensiero, consulta la pagina delle funzionalità principali di Thinking.
Ragionamento spaziale standard
Gli esempi che seguono mostrano attività di percezione robotica e ragionamento spaziale utilizzando prompt in linguaggio naturale, che vanno dal puntamento e dal ritrovamento di oggetti in un'immagine alla pianificazione delle traiettorie. Per semplicità, gli snippet di codice in questi esempi sono stati ridotti per mostrare solo il prompt e la chiamata all'API generate_content.
Il codice eseguibile completo e altri esempi sono disponibili nel Robotics cookbook.
Indicare gli oggetti
Indicare e trovare oggetti in immagini o fotogrammi video è un caso d'uso comune per i modelli di visione e linguaggio (VLM) in robotica. L'esempio seguente chiede al modello di trovare oggetti specifici all'interno di un'immagine e di restituirne le coordinate.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
L'output sarebbe simile all'esempio di guida introduttiva, un JSON contenente le coordinate degli oggetti trovati e le relative etichette.
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

Utilizza il seguente prompt per richiedere al modello di interpretare categorie astratte come "frutta" anziché oggetti specifici e individuare tutte le istanze nell'immagine.
Python
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
Visita la pagina Comprensione delle immagini per altre tecniche di elaborazione delle immagini.
Monitoraggio degli oggetti in un video
Gemini Robotics-ER 1.6 può anche analizzare i fotogrammi video per tracciare gli oggetti nel tempo. Consulta la sezione Input video per un elenco dei formati video supportati.
Di seguito è riportato il prompt di base utilizzato per trovare oggetti specifici in ogni frame analizzato dal modello:
Python
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
L'output mostra una penna e un laptop tracciati nei vari fotogrammi del video.
![]()
Per il codice eseguibile completo, consulta il Robotics cookbook.
Rilevamento di oggetti e riquadri di delimitazione
Oltre ai singoli punti, il modello può restituire anche bounding box 2D, fornendo una regione rettangolare che racchiude un oggetto.
Questo esempio richiede riquadri di delimitazione 2D per gli oggetti identificabili su una tabella. Il modello ha l'istruzione di limitare l'output a 25 oggetti e di denominare in modo univoco più istanze.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Di seguito vengono visualizzate le caselle restituite dal modello.
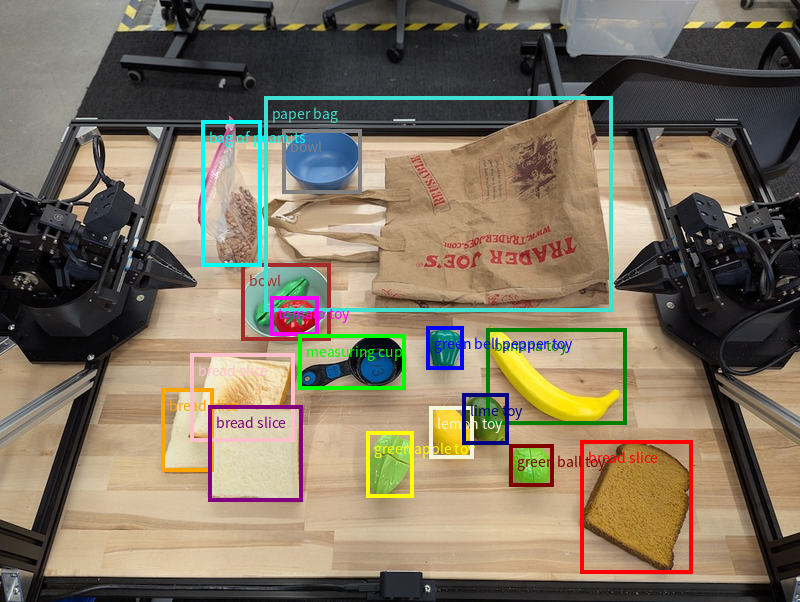
Per il codice eseguibile completo, consulta il ricettario di robotica. La pagina Comprensione delle immagini contiene anche altri esempi di attività visive come il rilevamento degli oggetti e gli esempi di riquadro di delimitazione.
Traiettorie
Gemini Robotics-ER 1.6 può generare sequenze di punti che definiscono una traiettoria, utili per guidare il movimento del robot.
Questo esempio richiede una traiettoria per spostare una penna rossa in un organizer, inclusi il punto di partenza e una serie di punti intermedi.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
La risposta è un insieme di coordinate che descrivono la traiettoria del percorso che la penna rossa deve seguire per completare l'attività di spostamento sopra l'organizzatore:
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

Capacità agentiche
Gli esempi seguenti mostrano il ragionamento robotico avanzato utilizzando le capacità agentiche del modello, in particolare l'esecuzione di codice. In questi scenari, il modello può decidere di scrivere ed eseguire codice Python per manipolare le immagini (ad esempio ingrandire, ritagliare o ruotare) per risolvere ambiguità o migliorare la precisione prima di rispondere.
Rilevamento di oggetti (zoom e ritaglio)
L'esempio seguente mostra come utilizzare l'esecuzione del codice per ingrandire e ritagliare un'immagine per una visualizzazione più chiara durante il rilevamento degli oggetti e la restituzione dei rettangoli di selezione.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
L'output del modello sarebbe simile al seguente:
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
Di seguito vengono visualizzate le caselle restituite dal modello.

Leggere un indicatore analogico e applicare la logica
Il seguente esempio mostra come utilizzare il modello per leggere un indicatore analogico ed eseguire calcoli temporali. Utilizza un'istruzione di sistema per forzare un output JSON.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
Di seguito è riportata un'immagine di input di esempio.

L'output del modello sarebbe simile al seguente:
Time Response: {
"hours": 12,
"minutes": 44
}
Misurare il liquido in un contenitore
L'esempio seguente mostra come utilizzare l'esecuzione del codice per leggere un misuratore e calcolare il livello del liquido in percentuale.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Di seguito è riportata l'immagine ingrandita dell'input.

Leggere i segni su una scheda di circuito
L'esempio seguente mostra come utilizzare l'esecuzione del codice per leggere il testo su un chip della scheda di circuiti, consentendo al modello di ingrandire, ritagliare e ruotare l'immagine in base alle esigenze.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Di seguito è riportata l'immagine ingrandita dell'input.

Annotazione immagine
L'esempio seguente mostra come utilizzare l'esecuzione del codice per annotare un'immagine (ad es. disegnare frecce per le istruzioni di smaltimento) e restituire l'immagine modificata.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Di seguito è riportata un'immagine di input di esempio.

L'output del modello sarebbe simile al seguente:
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
Orchestrazione
Gemini Robotics-ER 1.6 può eseguire la pianificazione delle attività e il ragionamento spaziale di livello superiore, deducendo azioni o identificando posizioni ottimali in base alla comprensione contestuale per orchestrare attività a lungo termine.
Fare spazio per un laptop
Questo esempio mostra come Gemini Robotics-ER può ragionare su uno spazio. Il prompt chiede al modello di identificare l'oggetto da spostare per creare spazio per un altro elemento.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
La risposta contiene una coordinata 2D dell'oggetto che risponde alla domanda dell'utente, in questo caso l'oggetto che deve spostarsi per fare spazio a un laptop.
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

Preparare un pranzo al sacco
Il modello può anche fornire istruzioni per attività in più passaggi e indicare gli oggetti pertinenti per ogni passaggio. Questo esempio mostra come il modello pianifica una serie di passaggi per preparare una borsa termica per il pranzo.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
La risposta a questo prompt è una serie di istruzioni passo passo su come preparare una borsa termica a partire dall'input dell'immagine.
Immagine di input

Output del modello
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
Chiamare un'API robot personalizzata
Questo esempio mostra l'orchestrazione delle attività con un'API robot personalizzata. Introduce un'API simulata progettata per un'operazione di prelievo e posizionamento. Il compito è raccogliere un blocco blu e metterlo in una ciotola arancione:

Come per gli altri esempi in questa pagina, il codice eseguibile completo è disponibile nel Robotics cookbook.
Il primo passaggio consiste nell'individuare entrambi gli elementi con il seguente prompt:
Python
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
La risposta del modello include le coordinate normalizzate del blocco e della ciotola:
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
Questo esempio utilizza la seguente API mock robot:
Python
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
Il passaggio successivo consiste nel chiamare una sequenza di funzioni API con la logica necessaria per eseguire l'azione. Il prompt seguente include una descrizione dell'API robot che il modello deve utilizzare per orchestrare questa attività.
Python
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
Di seguito è riportato un possibile output del modello basato sul prompt e sull'API robot simulata. L'output include il processo di pensiero del modello e le attività che ha pianificato di conseguenza. Mostra anche l'output delle chiamate di funzione del robot che il modello ha sequenziato insieme.
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
Best practice
Per ottimizzare le prestazioni e l'accuratezza delle tue applicazioni di robotica, è fondamentale capire come interagire in modo efficace con il modello Gemini. Questa sezione illustra le best practice e le strategie chiave per creare prompt, gestire i dati visivi e strutturare le attività per ottenere i risultati più affidabili.
Usa un linguaggio chiaro e semplice.
Utilizza il linguaggio naturale: il modello Gemini è progettato per comprendere il linguaggio naturale e colloquiale. Struttura i prompt in modo che siano chiari dal punto di vista semantico e rispecchino il modo in cui una persona darebbe naturalmente le istruzioni.
Utilizza una terminologia di uso comune: scegli un linguaggio comune e quotidiano anziché un gergo tecnico o specializzato. Se il modello non risponde come previsto a un termine specifico, prova a riformularlo con un sinonimo più comune.
Ottimizza l'input visivo.
Aumenta lo zoom per i dettagli: quando hai a che fare con oggetti piccoli o difficili da distinguere in un'inquadratura più ampia, utilizza una funzione di riquadro di delimitazione per isolare l'oggetto di interesse. Puoi quindi ritagliare l'immagine in base a questa selezione e inviare la nuova immagine messa a fuoco al modello per un'analisi più dettagliata.
Sperimenta con l'illuminazione e il colore: la percezione del modello può essere influenzata da condizioni di illuminazione difficili e da un contrasto di colore scarso.
Suddividi i problemi complessi in passaggi più piccoli. Affrontando ogni passaggio più piccolo singolarmente, puoi guidare il modello verso un risultato più preciso e riuscito.
Migliorare l'accuratezza tramite il consenso. Per le attività che richiedono un alto grado di precisione, puoi interrogare il modello più volte con lo stesso prompt. Facendo la media dei risultati restituiti, puoi arrivare a un "consenso" che spesso è più preciso e affidabile.
Limitazioni
Tieni presenti le seguenti limitazioni quando sviluppi con Gemini Robotics-ER 1.6:
- Stato anteprima:il modello è attualmente in anteprima. Le API e le funzionalità potrebbero cambiare e potrebbero non essere adatte ad applicazioni critiche per la produzione senza test approfonditi.
- Latenza:query complesse, input ad alta risoluzione o
thinking_budgetpossono comportare tempi di elaborazione più lunghi. - Allucinazioni: come tutti i modelli linguistici di grandi dimensioni, Gemini Robotics-ER 1.6 può occasionalmente "avere allucinazioni" o fornire informazioni errate, soprattutto per prompt ambigui o input fuori distribuzione.
- Dipendenza dalla qualità del prompt:la qualità dell'output del modello dipende in larga misura dalla chiarezza e dalla specificità del prompt di input. Prompt vaghi o mal strutturati possono portare a risultati non ottimali.
- Costo di calcolo:l'esecuzione del modello, soprattutto con input video o
thinking_budgetelevati, consuma risorse di calcolo e comporta costi. Per ulteriori dettagli, consulta la pagina Pensiero. - Tipi di input:consulta i seguenti argomenti per informazioni dettagliate sulle limitazioni per ogni modalità.
Informativa sulla privacy
Riconosci che i modelli a cui viene fatto riferimento in questo documento (i "Modelli di robotica") sfruttano i dati video e audio per funzionare e muovere l'hardware in conformità con le tue istruzioni. Pertanto, puoi utilizzare i Modelli di robotica in modo che i dati di persone identificabili, come voce, immagini e dati di somiglianza ("Dati personali"), vengano raccolti dai Modelli di robotica. Se scegli di utilizzare i Modelli di robotica in modo da raccogliere dati personali, accetti di non consentire a persone identificabili di interagire con i Modelli di robotica o di trovarsi nell'area circostante, a meno che e fino a quando queste persone identificabili non siano state informate in modo sufficiente e non abbiano acconsentito al fatto che i loro dati personali possano essere forniti e utilizzati da Google come descritto nei Termini di servizio aggiuntivi dell'API Gemini disponibili all'indirizzo https://ai.google.dev/gemini-api/terms (i "Termini"), anche in conformità con la sezione intitolata "Modalità di utilizzo dei dati da parte di Google". Ti assicurerai che tale avviso consenta la raccolta e l'utilizzo dei dati personali come descritto nei Termini e farai ogni sforzo commercialmente ragionevole per ridurre al minimo la raccolta e la distribuzione dei dati personali utilizzando tecniche come la sfocatura dei volti e utilizzando i modelli di robotica in aree che non contengono persone identificabili nella misura in cui ciò sia praticabile.
Prezzi
Per informazioni dettagliate sui prezzi e sulle regioni disponibili, consulta la pagina dei prezzi.
Versioni modello
Anteprima di Robotics-ER 1.6
| Proprietà | Descrizione |
|---|---|
| Codice modello | gemini-robotics-er-1.6-preview |
| Tipi di dati supportati |
Input Testo, immagini, video, audio Output Testo |
| Limiti dei token[*] |
Limite di token di input 131.072 Limite di token di output 65.536 |
| Funzionalità | Non supportato Supportato Supportato Supportato Supportato Supportato Supportato Non supportato Non supportato Supportato Supportato Supportato Supportato |
| Opzioni di consumo |
Supportato Supportato Supportato |
| Versioni |
|
| Ultimo aggiornamento | Dicembre 2025 |
| Knowledge cutoff | Gennaio 2025 |
Passaggi successivi
- Esplora altre funzionalità e continua a sperimentare con diversi prompt e input per scoprire altre applicazioni per Gemini Robotics-ER 1.6. Per altri esempi, consulta il colab Guida introduttiva alla robotica.
- Scopri di più su come sono stati creati i modelli di Gemini Robotics pensando alla sicurezza. Visita la pagina sulla sicurezza della robotica di Google DeepMind.
- Scopri gli ultimi aggiornamenti sui modelli di Gemini Robotics nella pagina di destinazione di Gemini Robotics.