Gemini Robotics-ER 1.6 — это модель визуально-языкового взаимодействия (VLM), которая переносит возможности Gemini в области робототехники. Она разработана для сложных рассуждений в физическом мире, позволяя роботам интерпретировать сложные визуальные данные, выполнять пространственное мышление и планировать действия на основе команд на естественном языке.
Обратите внимание, что если вы использовали Gemini Robotics-ER 1.5, вы можете начать использовать модель 1.6, заменив имя модели с model="gemini-robotics-er-1.5-preview" на model="gemini-robotics-er-1.6-preview" в вызове API.
Основные характеристики и преимущества:
- Повышенная автономность: роботы способны рассуждать, адаптироваться и реагировать на изменения в условиях открытого пространства.
- Взаимодействие на естественном языке: упрощает использование роботов, позволяя назначать сложные задачи с помощью естественного языка.
- Организация задач: Разлагает команды на естественном языке на подзадачи и интегрируется с существующими контроллерами роботов и их поведением для выполнения задач в долгосрочной перспективе.
- Разносторонние возможности: находит и идентифицирует объекты, понимает взаимосвязи между объектами, планирует захваты и траектории, а также интерпретирует динамические сцены.
В этом документе описывается , что делает модель , и приводятся несколько примеров , демонстрирующих её агентные возможности.
Если вы хотите сразу же приступить к работе, вы можете опробовать модель в Google AI Studio.
Безопасность
Хотя робот Gemini Robotics-ER 1.6 был разработан с учетом требований безопасности, вы несете ответственность за поддержание безопасной среды вокруг робота. Модели генеративного ИИ могут совершать ошибки, а физические роботы могут причинить ущерб. Безопасность является приоритетом, и обеспечение безопасности моделей генеративного ИИ при использовании с реальной робототехникой является активным и критически важным направлением наших исследований. Чтобы узнать больше, посетите страницу Google DeepMind по безопасности робототехники .
Начало работы: поиск объектов в сцене
Следующий пример демонстрирует распространенный сценарий использования в робототехнике. Он показывает, как передать изображение и текстовую подсказку модели с помощью метода generateContent , чтобы получить список идентифицированных объектов с соответствующими им 2D-точками. Модель возвращает точки для объектов, идентифицированных на изображении, с указанием их нормализованных 2D-координат и меток.
Эти выходные данные можно использовать с API робототехники, вызывать модель визуального, языкового и операционного анализа (VLA) или любые другие пользовательские функции сторонних разработчиков для генерации действий, которые должен выполнять робот.
Python
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
ОТДЫХ
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
В результате будет получен JSON-массив, содержащий объекты, каждый из которых имеет point (нормализованные координаты [y, x] ) и label , идентифицирующую объект.
JSON
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
На следующем изображении представлен пример того, как можно отобразить эти точки:

Как это работает
Gemini Robotics-ER 1.6 позволяет вашим роботам ориентироваться в физическом мире и работать в нем, используя пространственное мышление. Для ввода изображений/видео/аудио и подсказок на естественном языке требуется:
- Понимание объектов и контекста сцены : идентифицирует объекты и объясняет их связь со сценой, включая их функциональные возможности.
- Понимание инструкций к заданию : Интерпретация заданий, сформулированных на естественном языке, например, «найди банан».
- Пространственно-временное мышление : понимание последовательности действий и того, как объекты взаимодействуют со сценой с течением времени.
- Предоставляет структурированный вывод : возвращает координаты (точки или ограничивающие прямоугольники), представляющие местоположение объектов.
Это позволяет роботам программно «видеть» и «понимать» окружающую среду.
Робот Gemini Robotics-ER 1.6 также является агентным, что означает, что он может разбивать сложные задачи (например, «положить яблоко в миску») на подзадачи для координации задач с долгосрочной перспективой:
- Последовательность выполнения подзадач : Разбивает команды на логическую последовательность шагов.
- Вызов функций/Выполнение кода : Выполняет шаги путем вызова существующих функций/инструментов робота или выполнения сгенерированного кода.
Подробнее о том, как работает вызов функций в Gemini, читайте на странице «Вызов функций» .
Использование бюджета мышления с робототехникой Gemini Robotics-ER 1.6
Gemini Robotics-ER 1.6 обладает гибким бюджетом мышления, позволяющим контролировать компромисс между задержкой и точностью. Для задач пространственного восприятия, таких как обнаружение объектов, модель может достигать высокой производительности с небольшим бюджетом мышления. Более сложные задачи рассуждения, такие как подсчет и оценка веса, выигрывают от большего бюджета мышления. Это позволяет сбалансировать потребность в ответах с низкой задержкой и высокой точностью результатов для более сложных задач.
Чтобы узнать больше о бюджетах, ориентированных на мышление, посетите страницу «Основные возможности мышления» .
Стандартное пространственное мышление
Приведенные ниже примеры демонстрируют задачи роботизированного восприятия и пространственного мышления с использованием подсказок на естественном языке, начиная от указания и поиска объектов на изображении и заканчивая планированием траекторий. Для простоты фрагменты кода в этих примерах сокращены и показывают только подсказку и вызов API generate_content .
Полный рабочий код, а также дополнительные примеры можно найти в книге рецептов по робототехнике .
Указание на объекты
Наведение курсора и поиск объектов на изображениях или видеокадрах — распространенный сценарий использования моделей визуального и языкового анализа (VLM) в робототехнике. В следующем примере модели предлагается найти определенные объекты на изображении и вернуть их координаты.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Результат будет аналогичен примеру для начала работы: JSON-файл, содержащий координаты найденных объектов и их метки.
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

Используйте следующую подсказку, чтобы попросить модель интерпретировать абстрактные категории, такие как «фрукты», вместо конкретных объектов и найти все их экземпляры на изображении.
Python
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
Для ознакомления с другими методами обработки изображений посетите страницу, посвященную анализу изображений .
Отслеживание объектов в видео
Робот Gemini Robotics-ER 1.6 также может анализировать видеокадры для отслеживания объектов во времени. Список поддерживаемых видеоформатов см. в разделе «Видеовходы».
Ниже приведена базовая подсказка, используемая для поиска конкретных объектов в каждом кадре, которые анализирует модель:
Python
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
В результате отображается отслеживание движения ручки и ноутбука по кадрам видео.
![]()
Полный рабочий код можно найти в руководстве по робототехнике .
Обнаружение объектов и ограничивающие рамки
Помимо отдельных точек, модель также может возвращать двумерные ограничивающие прямоугольники, представляющие собой прямоугольную область, охватывающую объект.
В этом примере запрашиваются двумерные ограничивающие рамки для идентифицируемых объектов на столе. Модели дается указание ограничить вывод 25 объектами и присвоить каждому экземпляру уникальное имя.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Ниже показаны коробки, возвращенные моделью.
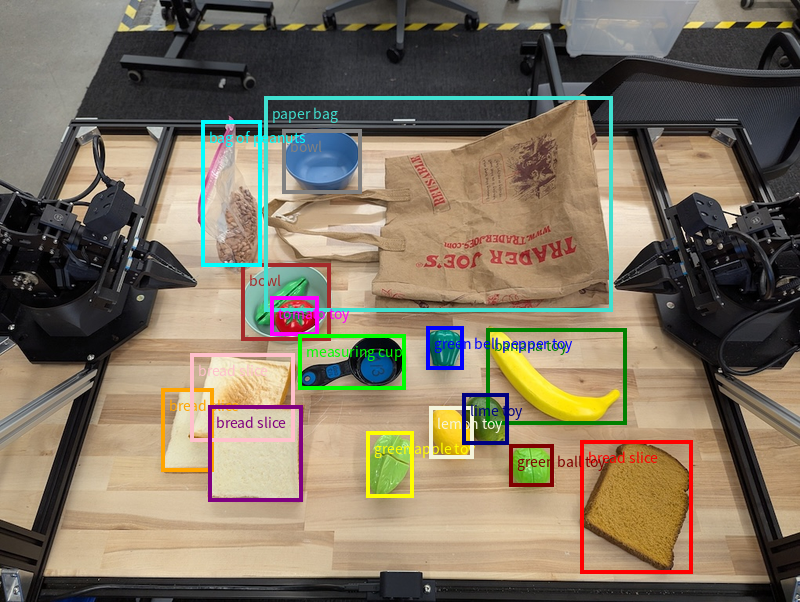
Полный рабочий код можно найти в руководстве по робототехнике . На странице, посвященной обработке изображений, также представлены дополнительные примеры визуальных задач, таких как обнаружение объектов и примеры ограничивающих рамок.
Траектории
Gemini Robotics-ER 1.6 может генерировать последовательности точек, определяющие траекторию, что полезно для управления движением робота.
В этом примере запрашивается траектория перемещения красной ручки к органайзеру, включая начальную точку и ряд промежуточных точек.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
В ответе получается набор координат, описывающих траекторию движения красной ручки, необходимую для перемещения её на верхнюю часть органайзера:
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

Агентские возможности
Следующие примеры демонстрируют сложные алгоритмы роботизированного мышления с использованием агентных возможностей модели, в частности, выполнения кода . В этих сценариях модель может решить написать и выполнить код на Python для манипулирования изображениями (например, увеличения масштаба, обрезки или поворота) с целью разрешения неоднозначностей или повышения точности перед ответом.
Обнаружение объектов (масштабирование и обрезка)
В следующем примере показано, как использовать выполнение кода для масштабирования и обрезки изображения с целью получения более четкого изображения при обнаружении объектов и возврате ограничивающих рамок.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Результаты работы модели будут выглядеть примерно так:
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
Ниже показаны коробки, возвращенные моделью.

Считывание показаний аналогового датчика и применение логики.
В следующем примере показано, как использовать модель для считывания показаний аналогового датчика и выполнения расчетов времени. Для вывода данных в формате JSON используется системная инструкция.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
Ниже приведён пример входного изображения.

Результаты работы модели будут выглядеть примерно так:
Time Response: {
"hours": 12,
"minutes": 44
}
Измерьте количество жидкости в емкости.
В следующем примере показано, как использовать выполнение кода для считывания показаний счетчика и расчета уровня жидкости в процентах.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Ниже представлено увеличенное изображение входных данных.

Прочтение маркировки на печатной плате
В следующем примере показано, как использовать выполнение кода для чтения текста с микросхемы печатной платы, что позволяет модели масштабировать, обрезать и поворачивать изображение по мере необходимости.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Ниже представлено увеличенное изображение входных данных.

Аннотация изображения
В следующем примере показано, как использовать выполнение кода для аннотирования изображения (например, рисования стрелок для инструкций по утилизации) и возврата измененного изображения.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Ниже приведён пример входного изображения.

Результаты работы модели будут выглядеть примерно так:
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
Оркестровка
Робот Gemini Robotics-ER 1.6 способен планировать задачи и осуществлять пространственное мышление более высокого уровня, определяя действия или выявляя оптимальные места на основе контекстного понимания для координации задач в долгосрочной перспективе.
Освобождение места для ноутбука
Этот пример демонстрирует, как робот Gemini Robotics-ER может рассуждать о пространстве. В задании модели требуется определить, какой объект необходимо переместить, чтобы освободить место для другого предмета.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
В ответе содержатся двумерные координаты объекта, отвечающего на вопрос пользователя, в данном случае — объекта, который следует переместить, чтобы освободить место для ноутбука.
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

Собрать обед с собой
Модель также может предоставлять инструкции для многоэтапных задач и указывать на соответствующие объекты для каждого шага. В этом примере показано, как модель планирует последовательность шагов по упаковке сумки для обеда.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
В ответ на этот запрос вы получите пошаговую инструкцию по упаковке ланч-бокса на основе полученного изображения.
Входное изображение

Результаты модели
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
Вызов пользовательского API робота
Этот пример демонстрирует организацию задач с помощью пользовательского API робота. В нем представлен фиктивный API, разработанный для операции захвата и перемещения. Задача состоит в том, чтобы поднять синий блок и поместить его в оранжевую миску:

Как и в других примерах на этой странице, полный рабочий код доступен в книге рецептов по робототехнике .
Первым шагом является поиск обоих предметов с помощью следующей подсказки:
Python
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
В отклик модели входят нормализованные координаты блока и чаши:
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
В этом примере используется следующий фиктивный API робота:
Python
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
Следующий шаг — вызов последовательности функций API с необходимой логикой для выполнения действия. В следующем запросе содержится описание API робота, который модель должна использовать при организации этой задачи.
Python
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
Ниже показан возможный результат работы модели на основе запроса и фиктивного API робота. Результат включает в себя ход мыслей модели и задачи, которые она спланировала в результате. Также показан результат вызовов функций робота, которые модель выполнила последовательно.
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
Передовые методы
Для оптимизации производительности и точности ваших роботизированных приложений крайне важно понимать, как эффективно взаимодействовать с моделью Gemini. В этом разделе описаны лучшие практики и ключевые стратегии для создания подсказок, обработки визуальных данных и структурирования задач для достижения наиболее надежных результатов.
Используйте ясный и простой язык.
Используйте естественный язык : модель Gemini разработана для понимания естественного разговорного языка. Формулируйте свои вопросы таким образом, чтобы они были семантически понятны и отражали то, как человек обычно дает инструкции.
Используйте повседневную терминологию : отдавайте предпочтение общеупотребительному языку, а не техническому или специализированному жаргону. Если модель не реагирует должным образом на определенный термин, попробуйте перефразировать его, используя более распространенный синоним.
Оптимизируйте визуальное представление данных.
Увеличьте изображение для детализации : при работе с мелкими или трудноразличимыми на широком плане объектами используйте функцию ограничивающей рамки, чтобы выделить интересующий объект. Затем вы можете обрезать изображение до этой области и отправить новое, сфокусированное изображение модели для более детального анализа.
Экспериментируйте с освещением и цветом : на восприятие модели могут влиять сложные условия освещения и низкий цветовой контраст.
Разбейте сложные проблемы на более мелкие шаги. Решая каждый из этих шагов по отдельности, вы сможете направить модель к более точному и успешному результату.
Повышение точности достигается за счет консенсуса. Для задач, требующих высокой точности, можно несколько раз обращаться к модели с одним и тем же запросом. Усреднив полученные результаты, можно прийти к «консенсусу», который зачастую оказывается более точным и надежным.
Ограничения
При разработке с использованием Gemini Robotics-ER 1.6 следует учитывать следующие ограничения:
- Статус предварительного просмотра: В настоящее время модель находится в режиме предварительного просмотра . API и возможности могут измениться, и она может быть непригодна для критически важных в производственной среде приложений без тщательного тестирования.
- Задержка: Сложные запросы, входные данные с высоким разрешением или обширный
thinking_budgetмогут привести к увеличению времени обработки. - Галлюцинации: Как и все большие языковые модели, Gemini Robotics-ER 1.6 может иногда «галлюцинировать» или предоставлять неверную информацию, особенно при неоднозначных запросах или входных данных, выходящих за рамки распределения.
- Зависимость от качества подсказки: качество выходных данных модели в значительной степени зависит от ясности и конкретности входной подсказки. Расплывчатые или плохо структурированные подсказки могут привести к неоптимальным результатам.
- Вычислительные затраты: Запуск модели, особенно с видеовходами или высоким
thinking_budget, потребляет вычислительные ресурсы и влечет за собой затраты. Подробнее см. на странице «Вычисления» . - Типы ввода: Подробную информацию об ограничениях для каждого режима см. в следующих разделах.
Уведомление о конфиденциальности
Вы подтверждаете, что модели, упомянутые в этом документе («Роботизированные модели»), используют видео- и аудиоданные для управления и перемещения вашего оборудования в соответствии с вашими инструкциями. Таким образом, вы можете использовать Роботизированные модели таким образом, чтобы Роботизированные модели собирали данные об идентифицируемых лицах, такие как голос, изображения и данные об их внешности («Персональные данные»). Если вы решите использовать Роботизированные модели таким образом, чтобы собирались Персональные данные, вы соглашаетесь не разрешать каким-либо идентифицируемым лицам взаимодействовать с Роботизированными моделями или находиться в зоне их действия, если и до тех пор, пока такие идентифицируемые лица не будут надлежащим образом уведомлены и не дадут согласие на то, что их Персональные данные могут быть предоставлены и использованы Google в соответствии с Дополнительными условиями обслуживания Gemini API, размещенными по адресу https://ai.google.dev/gemini-api/terms («Условия»), в том числе в соответствии с разделом «Как Google использует ваши данные». Вы обязуетесь обеспечить, чтобы такое уведомление разрешало сбор и использование персональных данных в соответствии с Условиями, и будете прилагать коммерчески обоснованные усилия для минимизации сбора и распространения персональных данных, используя такие методы, как размытие лица и управление роботизированными моделями в зонах, не содержащих идентифицируемых лиц, в той мере, в какой это практически возможно.
Цены
Подробную информацию о ценах и доступных регионах см. на странице с ценами .
Версии моделей
Предварительная версия Robotics-ER 1.6
| Свойство | Описание |
|---|---|
| Код модели | gemini-robotics-er-1.6-preview |
| Поддерживаемые типы данных | Входные данные Текст, изображения, видео, аудио Выход Текст |
| Ограничения на количество токенов [*] | Ограничение на количество введенных токенов 131,072 лимит выходных токенов 65,536 |
| Возможности | Не поддерживается Поддерживается Поддерживается Поддерживается Поддерживается Поддерживается Определить местоположение с помощью Google Maps Поддерживается Не поддерживается Не поддерживается Поддерживается Структурированные выходные данные Поддерживается Поддерживается Поддерживается |
| Варианты потребления | Поддерживается Поддерживается Поддерживается |
| версии |
|
| Последнее обновление | Декабрь 2025 г. |
| Порог знаний | Январь 2025 г. |
Следующие шаги
- Изучите другие возможности и продолжайте экспериментировать с различными запросами и входными данными, чтобы открыть для себя новые области применения Gemini Robotics-ER 1.6. Дополнительные примеры можно найти в Colab «Начало работы с робототехникой» .
- Чтобы узнать о том, как при создании моделей Gemini Robotics учитывались требования безопасности, посетите страницу Google DeepMind, посвященную безопасности робототехники .
- Ознакомьтесь с последними обновлениями моделей Gemini Robotics на целевой странице Gemini Robotics .