Gemini Robotics-ER 1.6, Gemini'ın ajan tabanlı yeteneklerini robotik alanına taşıyan bir görme-dil modelidir (VLM). Fiziksel dünyada gelişmiş akıl yürütme için tasarlanmıştır. Robotların karmaşık görsel verileri yorumlamasına, uzamsal akıl yürütme yapmasına ve doğal dil komutlarından eylemler planlamasına olanak tanır.
Gemini Robotics-ER 1.5 kullanıyorsanız API çağrısında model adını model="gemini-robotics-er-1.5-preview" yerine model="gemini-robotics-er-1.6-preview" olarak değiştirerek 1.6 modelini kullanmaya başlayabilirsiniz.
Temel özellikler ve avantajlar:
- Gelişmiş özerklik: Robotlar, açık uçlu ortamlardaki değişikliklere akıl yürüterek, uyum sağlayarak ve yanıt vererek tepki verebilir.
- Doğal dilde etkileşim: Doğal dil kullanarak karmaşık görev atamaları yapmayı mümkün kılarak robotların kullanımını kolaylaştırır.
- Görev düzenleme: Doğal dil komutlarını alt görevlere ayırır ve uzun vadeli görevleri tamamlamak için mevcut robot denetleyicileri ve davranışlarıyla entegre olur.
- Çok yönlü özellikler: Nesneleri bulup tanımlar, nesne ilişkilerini anlar, tutma ve yörünge planları yapar ve dinamik sahneleri yorumlar.
Bu belgede, modelin ne yaptığı açıklanmakta ve modelin ajan tabanlı yeteneklerini vurgulayan çeşitli örnekler verilmektedir.
Hemen denemek isterseniz modeli Google AI Studio'da deneyebilirsiniz.
Güvenlik
Gemini Robotics-ER 1.6 güvenliğe öncelik verilerek geliştirilmiş olsa da robotun etrafında güvenli bir ortam sağlamak sizin sorumluluğunuzdadır. Üretken yapay zeka modelleri hata yapabilir ve fiziksel robotlar hasara neden olabilir. Güvenlik bizim için önceliklidir. Üretken yapay zeka modellerinin gerçek dünyadaki robotik uygulamalarda güvenli bir şekilde kullanılmasını sağlamak, araştırmalarımızın aktif ve kritik bir alanıdır. Daha fazla bilgi edinmek için Google DeepMind robotik güvenlik sayfasını ziyaret edin.
Başlangıç: Sahnedeki nesneleri bulma
Aşağıdaki örnekte, robotik alanında yaygın bir kullanım alanı gösterilmektedir. Bu örnekte, generateContent yöntemi kullanılarak modele bir resim ve metin isteminin nasıl iletileceği gösterilmektedir. Bu yöntem, tanımlanan nesnelerin listesini ilgili 2D noktalarıyla birlikte almak için kullanılır.
Model, bir resimde tanımladığı öğeler için puan döndürür. Bu puanlar, öğelerin normalleştirilmiş 2D koordinatlarını ve etiketlerini döndürür.
Bu çıktıyı bir robotik API ile kullanabilir veya bir robotun gerçekleştireceği eylemler oluşturmak için bir vision-language-action (VLA) modeli ya da diğer üçüncü taraf kullanıcı tanımlı işlevleri çağırabilirsiniz.
Python
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
REST
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
Çıktı, her biri point (normalleştirilmiş [y, x] koordinatları) ve nesneyi tanımlayan bir label içeren nesnelerden oluşan bir JSON dizisi olacaktır.
JSON
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
Aşağıdaki resimde, bu noktaların nasıl gösterilebileceğine dair bir örnek verilmiştir:

İşleyiş şekli
Gemini Robotics-ER 1.6, robotlarınızın uzamsal anlayışı kullanarak fiziksel dünyada bağlam oluşturmasına ve çalışmasına olanak tanır. Resim/video/ses girişi ve doğal dil istemlerini kullanarak:
- Nesneleri ve sahne bağlamını anlama: Nesneleri ve sahneyle ilişkilerini (kullanım olanakları dahil) tanımlar.
- Görev talimatlarını anlama: Doğal dilde verilen görevleri yorumlar (ör. "muz bul").
- Mekansal ve zamansal olarak akıl yürütme: Eylem dizilerini ve nesnelerin zaman içinde bir sahneyle nasıl etkileşimde bulunduğunu anlama.
- Yapılandırılmış çıkış sağlama: Nesne konumlarını temsil eden koordinatları (noktalar veya sınırlayıcı kutular) döndürür.
Bu sayede robotlar, çevrelerini programatik olarak "görebilir" ve "anlayabilir".
Gemini Robotics-ER 1.6, karmaşık görevleri ("elmaları kaseye koy" gibi) alt görevlere ayırarak uzun vadeli görevleri yönetebilen bir aracıdır:
- Alt görevleri sıralama: Komutları mantıksal bir adım sırasına ayırır.
- İşlev çağrıları/Kod yürütme: Mevcut robot işlevlerinizi/araçlarınızı çağırarak veya oluşturulan kodu yürüterek adımları uygular.
Gemini ile işlev çağrısının nasıl çalıştığı hakkında daha fazla bilgiyi İşlev Çağrısı sayfasında bulabilirsiniz.
Gemini Robotics-ER 1.6 ile düşünme bütçesini kullanma
Gemini Robotics-ER 1.6, gecikme ve doğruluk arasındaki dengeyi kontrol etmenizi sağlayan esnek bir düşünme bütçesine sahiptir. Nesne tespit etme gibi uzamsal anlama görevlerinde model, küçük bir düşünme süreci bütçesiyle yüksek performans elde edebilir. Sayma ve ağırlık tahmini gibi daha karmaşık akıl yürütme görevleri, daha büyük bir düşünme bütçesinden yararlanır. Bu sayede, daha zorlu görevlerde düşük gecikmeli yanıtlar ile yüksek doğruluklu sonuçlar arasında denge kurabilirsiniz.
Düşünme bütçeleri hakkında daha fazla bilgi edinmek için Düşünme temel özellikleri sayfasını inceleyin.
Standart mekansal akıl yürütme
Aşağıdaki örneklerde, doğal dil istemlerini kullanarak robotik algılama ve uzamsal akıl yürütme ile ilgili görevler gösterilmektedir. Bu görevler arasında bir görüntüdeki nesneleri işaretleme ve bulma ile yörünge planlama yer alır. Bu örneklerdeki kod snippet'leri, yalnızca istemi ve generate_content API'sine yapılan çağrıyı göstermek için basitleştirilmiştir.
Çalıştırılabilir kodun tamamı ve ek örnekleri Robotics cookbook'ta bulabilirsiniz.
Nesneleri işaret etme
Görüntü veya video karelerindeki nesneleri işaretleme ve bulma, robotik alanında görme ve dil modellerinin (VLMs) yaygın olarak kullanıldığı bir alandır. Aşağıdaki örnekte, modelden bir resimdeki belirli nesneleri bulup koordinatlarını döndürmesi isteniyor.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Çıktı, başlangıç örneğine benzer şekilde, bulunan nesnelerin koordinatlarını ve etiketlerini içeren bir JSON olacaktır.
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

Modelden belirli nesneler yerine "meyve" gibi soyut kategorileri yorumlamasını ve resimdeki tüm örnekleri bulmasını istemek için aşağıdaki istemi kullanın.
Python
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
Diğer görüntü işleme teknikleri için görüntü yorumlama sayfasını ziyaret edin.
Videodaki nesneleri izleme
Gemini Robotics-ER 1.6, nesneleri zaman içinde takip etmek için video karelerini de analiz edebilir. Desteklenen video biçimlerinin listesi için Video girişleri bölümüne bakın.
Modelin analiz ettiği her karede belirli nesneleri bulmak için kullanılan temel istem aşağıda verilmiştir:
Python
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
Çıkışta, video karelerinde takip edilen bir kalem ve dizüstü bilgisayar gösteriliyor.
![]()
Çalıştırılabilir kodun tamamı için Robotics cookbook'a (Robotik yemek kitabı) bakın.
Nesne tespit etme ve sınırlayıcı kutular
Model, tek noktaların yanı sıra 2D sınırlayıcı kutular da döndürebilir. Bu kutular, bir nesneyi çevreleyen dikdörtgen bir bölge sağlar.
Bu örnekte, bir masadaki tanımlanabilir nesneler için 2 boyutlu sınırlayıcı kutular istenmektedir. Modele, çıkışı 25 nesneyle sınırlaması ve birden fazla örneği benzersiz şekilde adlandırması talimatı veriliyor.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Aşağıda, modelden döndürülen kutular gösterilmektedir.
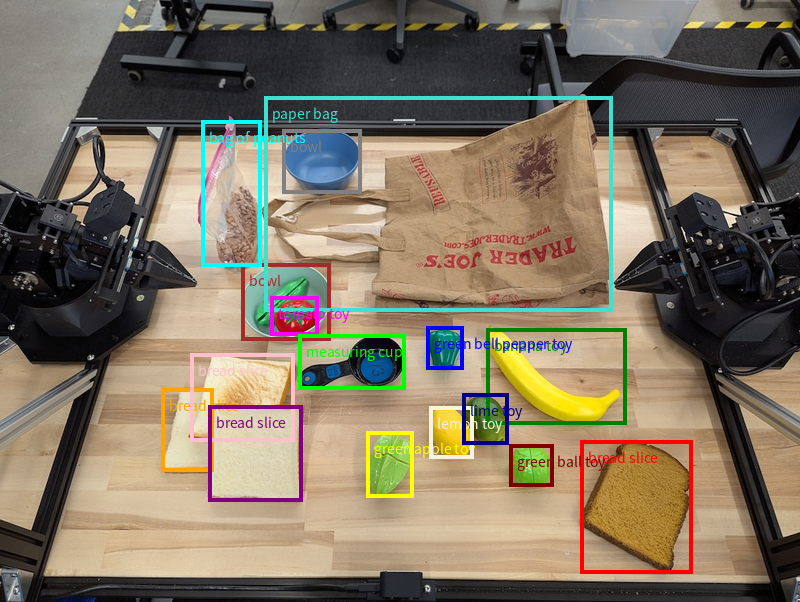
Çalıştırılabilir kodun tamamı için Robotics cookbook'u inceleyin. Görüntü anlama sayfasında, nesne tespit etme ve sınırlayıcı kutu örnekleri gibi görsel görevlerle ilgili ek örnekler de yer alır.
Yörüngeler
Gemini Robotics-ER 1.6, robot hareketini yönlendirmek için yararlı olan ve bir yörüngeyi tanımlayan nokta dizileri oluşturabilir.
Bu örnekte, başlangıç noktası ve bir dizi ara nokta da dahil olmak üzere kırmızı bir kalemi bir düzenleyiciye taşımak için bir yörünge isteniyor.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
Yanıt, kırmızı kalemin düzenleyicinin üzerine taşıma görevini tamamlamak için izlemesi gereken yolun yörüngesini açıklayan bir dizi koordinattır:
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

Ajan tabanlı yetenekler
Aşağıdaki örneklerde, modelin ajan tabanlı yeteneklerini (özellikle kod yürütme) kullanarak gelişmiş robotik akıl yürütme gösterilmektedir. Bu senaryolarda model, yanıt vermeden önce belirsizlikleri gidermek veya doğruluğu artırmak için görüntüleri değiştirmek (ör. yakınlaştırma, kırpma veya döndürme) üzere Python kodu yazıp yürütmeye karar verebilir.
Nesne tespit etme (yakınlaştırma ve kırpma)
Aşağıdaki örnekte, nesneleri algılarken ve sınırlayıcı kutuları döndürürken daha net bir görünüm için kodu yürütme özelliğini kullanarak bir resmi nasıl yakınlaştırıp kırpacağınız gösterilmektedir.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Model çıkışı aşağıdaki gibi olur:
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
Aşağıda, modelden döndürülen kutular gösterilmektedir.

Analog bir göstergeyi okuma ve mantık uygulama
Aşağıdaki örnekte, analog bir ölçüm cihazını okumak ve zaman hesaplamaları yapmak için modelin nasıl kullanılacağı gösterilmektedir. JSON çıkışını zorunlu kılmak için sistem talimatı kullanır.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
Aşağıda örnek bir resim girişi verilmiştir.

Model çıkışı aşağıdaki gibi olur:
Time Response: {
"hours": 12,
"minutes": 44
}
Bir kaptaki sıvıyı ölçme
Aşağıdaki örnekte, bir ölçüm cihazını okumak ve sıvı seviyesini yüzde olarak hesaplamak için kod yürütmenin nasıl kullanılacağı gösterilmektedir.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Aşağıda, girişin yakınlaştırılmış resmi gösterilmektedir.

Devre kartındaki işaretleri okuma
Aşağıdaki örnekte, bir devre kartı çipindeki metni okumak için kod yürütmenin nasıl kullanılacağı gösterilmektedir. Bu sayede model, görüntüyü gerektiği gibi yakınlaştırabilir, kırpabilir ve döndürebilir.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Aşağıda, girişin yakınlaştırılmış resmi gösterilmektedir.

Resim ek açıklaması
Aşağıdaki örnekte, kod yürütme özelliğinin bir resmi açıklama eklemek (ör. imha talimatları için ok çizme) ve değiştirilmiş resmi döndürmek için nasıl kullanılacağı gösterilmektedir.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Aşağıda örnek bir resim girişi verilmiştir.

Model çıkışı aşağıdaki gibi olur:
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
Düzenleme
Gemini Robotics-ER 1.6, görev planlama ve daha üst düzeyde mekansal akıl yürütme yapabilir, uzun vadeli görevleri yönetmek için bağlamsal anlayışa dayalı olarak eylemleri çıkarabilir veya en uygun konumları belirleyebilir.
Dizüstü bilgisayar için yer açma
Bu örnekte, Gemini Robotics-ER'ın bir alan hakkında nasıl akıl yürütebileceği gösterilmektedir. İstemde, başka bir öğe için yer açmak üzere hangi nesnenin taşınması gerektiği soruluyor.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Yanıtta, kullanıcının sorusunu yanıtlayan nesnenin 2 boyutlu koordinatı yer alır. Bu örnekte, dizüstü bilgisayara yer açmak için taşınması gereken nesne söz konusudur.
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

Öğle Yemeği Hazırlama
Model, çok adımlı görevlerle ilgili talimatlar da sağlayabilir ve her adım için ilgili nesneleri gösterebilir. Bu örnekte, modelin bir öğle yemeği çantasını hazırlamak için bir dizi adımı nasıl planladığı gösterilmektedir.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Bu istemin yanıtı, resim girişinden yola çıkarak bir öğle yemeği çantasını nasıl paketleyeceğinizle ilgili adım adım talimatlar içerir.
Giriş resmi

Model çıkışı
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
Özel bir robot API'sini çağırma
Bu örnekte, özel bir robot API'si ile görev düzenleme gösterilmektedir. Bu kitapta, seçme ve yerleştirme işlemi için tasarlanmış bir sahte API tanıtılmaktadır. Görev, mavi bir bloğu alıp turuncu bir kaseye yerleştirmektir:

Bu sayfadaki diğer örneklere benzer şekilde, çalıştırılabilir kodun tamamını Robotics cookbook'ta bulabilirsiniz.
İlk adımda, aşağıdaki istemi kullanarak her iki öğeyi de bulun:
Python
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
Model yanıtı, blok ve kâsenin normalleştirilmiş koordinatlarını içerir:
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
Bu örnekte aşağıdaki sahte robot API'si kullanılmaktadır:
Python
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
Bir sonraki adım, işlemi yürütmek için gerekli mantığa sahip bir API işlevleri dizisini çağırmaktır. Aşağıdaki istemde, modelin bu görevi düzenlerken kullanması gereken robot API'sinin açıklaması yer alıyor.
Python
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
Aşağıda, isteme ve sahte robot API'sine dayalı olarak modelin olası bir çıkışı gösterilmektedir. Çıkış, modelin düşünce sürecini ve bunun sonucunda planladığı görevleri içerir. Ayrıca, modelin birlikte sıraladığı robot işlevi çağrılarının çıkışını da gösterir.
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
En iyi uygulamalar
Robotik uygulamalarınızın performansını ve doğruluğunu optimize etmek için Gemini modeliyle etkili bir şekilde nasıl etkileşim kuracağınızı anlamanız çok önemlidir. Bu bölümde, en güvenilir sonuçları elde etmek için istem oluşturma, görsel verileri işleme ve görevleri yapılandırmaya yönelik en iyi uygulamalar ve temel stratejiler özetlenmektedir.
Açık ve basit bir dil kullanın.
Doğal dili kullanın: Gemini modeli, doğal ve sohbet tarzındaki dili anlamak için tasarlanmıştır. İstemlerinizi, semantik olarak net olacak ve bir kişinin doğal olarak talimat vereceği şekilde yapılandırın.
Günlük dildeki terimleri kullanın: Teknik veya uzmanlık gerektiren jargon yerine günlük dildeki terimleri tercih edin. Model, belirli bir terime beklendiği gibi yanıt vermiyorsa terimi daha yaygın bir eş anlamlı kelimeyle yeniden ifade etmeyi deneyin.
Görsel girişi optimize edin.
Ayrıntı için yakınlaştırın: Küçük olan veya daha geniş bir çekimde ayırt edilmesi zor olan nesnelerle uğraşırken ilgilenilen nesneyi izole etmek için sınırlayıcı kutu işlevini kullanın. Ardından, görüntüyü bu seçime göre kırpabilir ve daha ayrıntılı bir analiz için yeni, odaklanmış görüntüyü modele gönderebilirsiniz.
Işık ve renkle denemeler yapın: Modelin algısı, zorlu ışık koşullarından ve düşük renk kontrastından etkilenebilir.
Karmaşık sorunları daha küçük adımlara ayırın. Her küçük adımı ayrı ayrı ele alarak modeli daha hassas ve başarılı bir sonuca yönlendirebilirsiniz.
Uzlaşma yoluyla doğruluğu artırın. Yüksek düzeyde hassasiyet gerektiren görevler için modele aynı istemle birden fazla kez sorgu gönderebilirsiniz. Döndürülen sonuçların ortalamasını alarak genellikle daha doğru ve güvenilir olan bir "uzlaşmaya" varabilirsiniz.
Sınırlamalar
Gemini Robotics-ER 1.6 ile geliştirme yaparken aşağıdaki sınırlamaları göz önünde bulundurun:
- Önizleme durumu: Model şu anda önizleme aşamasındadır. API'ler ve özellikler değişebilir. Ayrıca, kapsamlı testler yapılmadan üretime yönelik kritik uygulamalar için uygun olmayabilir.
- Gecikme: Karmaşık sorgular, yüksek çözünürlüklü girişler veya kapsamlı
thinking_budget, işlem sürelerinin uzamasına neden olabilir. - Halüsinasyonlar: Tüm büyük dil modelleri gibi Gemini Robotics-ER 1.6 da bazen "halüsinasyon" yapabilir veya yanlış bilgi verebilir. Bu durum özellikle belirsiz istemlerde ya da dağıtım dışı girişlerde görülür.
- İstem kalitesine bağlılık: Modelin çıkışının kalitesi, giriş isteminin netliğine ve spesifikliğine büyük ölçüde bağlıdır. Belirsiz veya kötü yapılandırılmış istemler, optimum olmayan sonuçlara yol açabilir.
- Hesaplama maliyeti: Özellikle video girişleriyle veya yüksek
thinking_budgetile modelin çalıştırılması, hesaplama kaynaklarını tüketir ve maliyetlere neden olur. Daha fazla bilgi için Düşünme sayfasına bakın. - Giriş türleri: Her moddaki sınırlamalarla ilgili ayrıntılar için aşağıdaki konulara bakın.
Gizlilik Uyarısı
Bu belgede referans verilen modellerin ("Robotik Modeller") çalışmak ve donanımınızı talimatlarınıza uygun şekilde hareket ettirmek için video ve ses verilerinden yararlandığını kabul edersiniz. Bu nedenle, Robotik Modelleri, tanımlanabilir kişilerden elde edilen veriler (ör. ses, görüntü ve benzerlik verileri ("Kişisel Veriler")) Robotik Modeller tarafından toplanacak şekilde çalıştırabilirsiniz. Robotik Modelleri Kişisel Veri toplayacak şekilde çalıştırmayı seçerseniz, bu tür tanımlanabilir kişilerin, Kişisel Verilerinin https://ai.google.dev/gemini-api/terms adresinde bulunan Gemini API Ek Hizmet Şartları'nda ("Şartlar") belirtildiği şekilde Google'a sağlanabileceği ve Google tarafından kullanılabileceği konusunda yeterince bilgilendirilip onay vermediği sürece Robotik Modellerle etkileşime girmesine veya Robotik Modellerin bulunduğu alanda bulunmasına izin vermeyeceğinizi kabul edersiniz. Bu durum, "Google Verilerinizi Nasıl Kullanır?" başlıklı bölüm uyarınca da geçerlidir. Bu tür bir bildirimin, Şartlar'da belirtildiği şekilde Kişisel Verilerin toplanmasına ve kullanılmasına izin vermesini sağlayacak ve yüz bulanıklaştırma gibi teknikler kullanarak ve Robotik Modelleri, tanımlanabilir kişilerin bulunmadığı alanlarda çalıştırarak Kişisel Verilerin toplanmasını ve dağıtılmasını mümkün olduğunca en aza indirmek için ticari olarak makul çabayı göstereceksiniz.
Fiyatlandırma
Fiyatlandırma ve kullanılabilir bölgeler hakkında ayrıntılı bilgi için fiyatlandırma sayfasına bakın.
Model sürümleri
Robotics-ER 1.6 Önizlemesi
| Mülk | Açıklama |
|---|---|
| Model kodu | gemini-robotics-er-1.6-preview |
| Desteklenen veri türleri |
Girişler Metin, resim, video, ses Çıkış Metin |
| Jeton sınırları[*] |
Giriş jetonu sınırı 131.072 Çıkış jetonu sınırı 65.536 |
| Özellikler | Desteklenmiyor Destekleniyor Destekleniyor Destekleniyor Destekleniyor Destekleniyor Google Haritalar ile Temellendirme Destekleniyor Desteklenmiyor Desteklenmiyor Destekleniyor Destekleniyor Düşünme (Thinking) Destekleniyor Destekleniyor |
| Tüketim seçenekleri |
Destekleniyor Destekleniyor Destekleniyor |
| Sürümler |
|
| Son güncelleme | Aralık 2025 |
| Son güncel bilgi tarihi | Ocak 2025 |
Sonraki adımlar
- Diğer özellikleri keşfedin ve Gemini Robotics-ER 1.6'nın daha fazla uygulamasını keşfetmek için farklı istemler ve girişlerle denemeler yapmaya devam edin. Daha fazla örnek için Robotics getting started colab (Robotik ile Başlangıç Colab) başlıklı makaleyi inceleyin.
- Gemini Robotics modellerinin güvenlik göz önünde bulundurularak nasıl geliştirildiği hakkında bilgi edinmek için Google DeepMind robotik güvenlik sayfasını ziyaret edin.
- Gemini Robotics modellerindeki en son güncellemeler hakkında bilgi edinmek için Gemini Robotics açılış sayfasına göz atın.