Gemini API는 프로토타입 제작 단계에서 조정할 수 있는 안전 설정을 제공하여 애플리케이션에 더 제한적인 안전 구성이 필요한지 아니면 덜 제한적인 안전 구성이 필요한지 결정할 수 있습니다. 이러한 설정은 4가지 필터 카테고리에서 조정하여 특정 유형의 콘텐츠를 제한하거나 허용할 수 있습니다.
이 가이드에서는 Gemini API가 안전 설정 및 필터링을 처리하는 방법과 애플리케이션의 안전 설정을 변경하는 방법을 설명합니다.
안전 필터
Gemini API의 조정 가능한 안전 필터는 다음 카테고리를 포함합니다.
| 카테고리 | 설명 |
|---|---|
| 괴롭힘 | 정체성 또는 보호 대상 속성을 겨냥하는 부정적이거나 유해한 댓글 |
| 증오심 표현 | 무례하거나 모욕적이거나 욕설이 있는 콘텐츠 |
| 음란물 | 성적 행위 또는 기타 외설적인 콘텐츠에 대한 언급 포함 |
| 위험 | 유해한 행위를 조장, 촉진 또는 장려 |
이러한 카테고리는 HarmCategory에 정의되어 있습니다. 이러한 필터를 사용하면 사용 사례에 적합한 결과를 조정할 수 있습니다. 예를 들어 동영상 게임 대화를 빌드하는 경우 게임의 특성상 위험 하다고 평가되는 콘텐츠를 더 많이 허용해도 괜찮다고 판단할 수 있습니다.
Gemini API에는 조정 가능한 안전 필터 외에도 아동 안전을 저해하는 콘텐츠와 같은 핵심 유해 요소에 대한 기본 보호 조치가 있습니다. 이러한 유형의 유해 요소는 항상 차단되며 조정할 수 없습니다.
콘텐츠 안전 필터링 수준
Gemini API는 콘텐츠가 안전하지 않을 가능성 수준을 HIGH, MEDIUM, LOW 또는 NEGLIGIBLE로 분류합니다.
Gemini API는 심각도가 아닌 콘텐츠가 안전하지 않을 가능성을 기준으로 콘텐츠를 차단합니다. 일부 콘텐츠는 심각도의 유해성이 높더라도 안전하지 않을 가능성이 낮을 수 있으므로 이를 고려하는 것이 중요합니다. 예를 들어 다음 문장을 비교해 보세요.
- 로봇이 나를 때렸습니다.
- 로봇이 나를 베었습니다.
첫 번째 문장은 안전하지 않을 가능성이 더 높을 수 있지만 폭력 측면에서는 두 번째 문장이 더 심각하다고 생각할 수 있습니다. 따라서 최종 사용자에게 해를 주지 않으면서 주요 사용 사례를 지원하는 데 필요한 적절한 수준의 차단이 무엇인지 신중하게 고려하고 테스트해야 합니다.
요청별 안전 필터링
API에 대한 각 요청의 안전 설정을 조정할 수 있습니다. 요청하면 콘텐츠가 분석되고 안전 등급이 지정됩니다. 안전 등급에는 피해 분류의 카테고리와 확률이 포함됩니다. 예를 들어 괴롭힘 카테고리의 확률이 높아서 콘텐츠가 차단된 경우 반환된 안전 등급에는 카테고리가 HARASSMENT와 같고 유해 확률이 HIGH로 설정됩니다.
모델의 고유한 안전성으로 인해 추가 필터는 기본적으로 사용 중지 되어 있습니다. 사용 설정하면 안전하지 않을 가능성에 따라 콘텐츠를 차단하도록 시스템을 구성할 수 있습니다. 기본 모델 동작은 대부분의 사용 사례를 포함하므로 애플리케이션에 지속적으로 필요한 경우에만 이러한 설정을 조정해야 합니다.
다음 표에서 각 카테고리에 대해 조정할 수 있는 차단 설정을 확인할 수 있습니다. 예를 들어 증오심 표현 카테고리에 대해 차단 설정을 소수 차단 으로 설정하면 증오심 표현 콘텐츠일 가능성이 높은 모든 항목이 차단됩니다. 하지만 가능성이 낮은 모든 항목이 허용됩니다.
| 기준 (Google AI Studio) | 기준 (API) | 설명 |
|---|---|---|
| 사용 안함 | OFF |
안전 필터 사용 중지 |
| 차단 안함 | BLOCK_NONE |
안전하지 않은 콘텐츠일 가능성과 관계없이 항상 표시 |
| 소수 차단 | BLOCK_ONLY_HIGH |
안전하지 않은 콘텐츠일 가능성이 높은 경우 차단 |
| 일부 차단 | BLOCK_MEDIUM_AND_ABOVE |
안전하지 않은 콘텐츠일 가능성이 중간 또는 높은 경우 차단 |
| 대부분 차단 | BLOCK_LOW_AND_ABOVE |
안전하지 않은 콘텐츠일 가능성이 낮음, 중간 또는 높은 경우 차단 |
| 해당 사항 없음 | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
기준점이 지정되지 않았습니다. 기본 기준점을 사용하여 차단합니다. |
기준점이 설정되지 않은 경우 Gemini 2.5 및 3 모델의 기본 차단 기준점은 사용 중지 입니다.
생성 서비스에 대한 각 요청에 이러한 설정을 지정할 수 있습니다.
자세한 내용은 HarmBlockThreshold API
참조를 확인하세요.
안전 피드백
generateContent
는
GenerateContentResponse 안전 피드백을 포함하는
을 반환합니다.
프롬프트 피드백은
promptFeedback에 포함되어 있습니다. promptFeedback.blockReason이 설정된 경우 프롬프트의 콘텐츠가 차단된 것입니다.
응답 후보 피드백은
Candidate.finishReason 및
Candidate.safetyRatings에 포함되어 있습니다. 응답 콘텐츠가 차단되고 finishReason이 SAFETY인 경우 safetyRatings에서 자세한 내용을 확인할 수 있습니다. 차단된 콘텐츠는 반환되지 않습니다.
안전 설정 조정
이 섹션에서는 Google AI Studio와 코드에서 안전 설정을 조정하는 방법을 설명합니다.
Google AI Studio
Google AI Studio에서 안전 설정을 조정할 수 있습니다.
실행 설정 패널의 고급 설정 에서 안전 설정 을 클릭하여 실행 안전 설정 모달을 엽니다. 모달에서 슬라이더를 사용하여 안전 카테고리별 콘텐츠 필터링 수준을 조정할 수 있습니다.
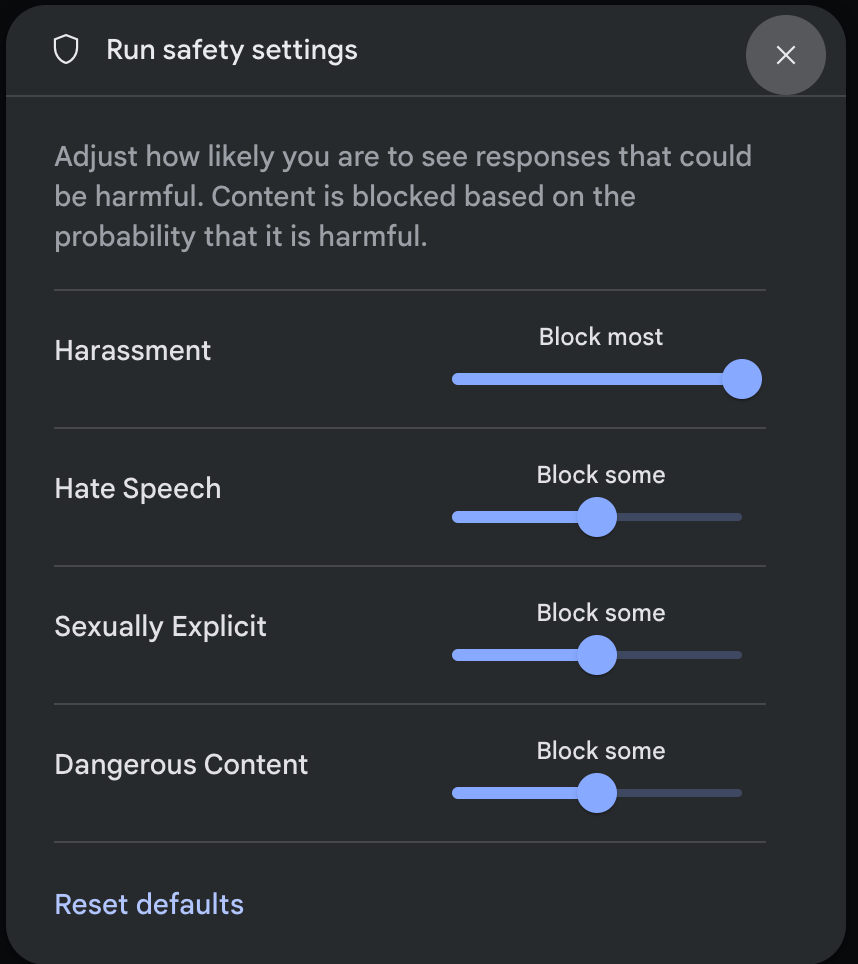
요청을 보낼 때 (예: 모델에 질문) 요청의 콘텐츠가 차단되면 콘텐츠 차단됨 메시지가 표시됩니다. 자세한 내용을 보려면 포인터를 콘텐츠 차단됨 텍스트 위로 가져가서 카테고리와 유해 분류의 확률을 확인하세요.
코드 예시
다음 코드 스니펫에서는 GenerateContent 호출에서 안전 설정을 설정하는 방법을 보여줍니다. 이렇게 하면 증오심 표현(HARM_CATEGORY_HATE_SPEECH) 카테고리의 기준점이 설정됩니다. 이 카테고리를 BLOCK_LOW_AND_ABOVE로 설정하면 증오심 표현일 가능성이 낮거나 높은 콘텐츠가 차단됩니다. 기준점 설정을 이해하려면 요청별 안전 필터링을 참고하세요.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
자바
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
다음 단계
- 전체 API에 관해 자세히 알아보려면 API 참조를 확인하세요.
- LLM으로 개발할 때 안전 고려사항을 전반적으로 살펴보려면 안전 가이드를 검토하세요.
- Jigsaw팀에서 가능성과 심각도 평가에 관해 자세히 알아보세요.
- Perspective API와 같은 안전 솔루션에 기여하는 제품에 관해 자세히 알아보세요. Perspective API. * 이러한 안전 설정을 사용하여 유해성 분류기를 만들 수 있습니다. 시작하려면 분류 예시를 참고하세요.