Nano Banana 이미지 생성
- 또는 프롬프트에서 직접 빌드할 수 있습니다.
-








-
Nano Banana 2로 생성됨 프롬프트: '유광 잡지 표지 사진. 미니멀한 파란색 표지에는 굵은 글씨로 Nano Banana라고 적혀 있습니다. 텍스트는 세리프 글꼴로 되어 있으며 뷰를 채웁니다. 다른 텍스트는 없습니다. 텍스트 앞에는 세련되고 미니멀한 드레스를 입은 사람의 인물 사진이 있습니다. 그녀는 초점인 숫자 2를 장난스럽게 들고 있습니다.
바코드와 함께 문제 번호와 '2026년 2월' 날짜를 모서리에 넣습니다. 잡지는 디자이너 매장 내 오렌지색 회반죽 벽에 있는 선반에 있습니다.' -
Nano Banana Pro로 생성됨 프롬프트: '런던의 가장 상징적인 랜드마크와 건축 요소를 보여주는 45도 각도로 위에서 내려다보는 구도의 아이소메트릭 미니어처 3D 만화 장면을 명확하게 표현해 줘. 사실적인 PBR 소재와 부드럽고 섬세한 질감, 부드럽고 사실적인 조명과 그림자를 사용해 줘. 현재 날씨 조건을 도시 환경에 직접 통합하여 몰입감 있는 분위기를 조성합니다. 부드러운 단색 배경을 사용하여 깨끗하고 미니멀한 구도를 사용합니다. 상단 중앙에 'London'이라는 제목을 큰 굵은 글씨로 배치하고 그 아래에 눈에 띄는 날씨 아이콘, 날짜 (작은 텍스트), 온도 (중간 텍스트)를 배치합니다. 모든 텍스트는 일관된 간격으로 가운데에 배치되어야 하며 건물의 상단과 미묘하게 겹칠 수 있습니다.' -
Nano Banana 2로 생성됨 프롬프트: '이미지 검색을 사용하여 화려한 케찰새의 정확한 이미지를 찾아 줘. 자연스러운 위아래 그라데이션과 최소한의 구성으로 이 새의 아름다운 3:2 배경화면을 만들어 줘." -

Nano Banana Pro로 생성됨 프롬프트: '바나나 향수 고급 광고에 이 로고를 넣어 줘. 로고가 병에 완벽하게 통합되어 있습니다.' -
Nano Banana Pro로 생성됨 프롬프트: '아침 식사를 제공하는 번화한 카페의 일상적인 장면 사진. 앞쪽에는 파란색 머리의 애니메이션 남자가 있고, 한 사람은 연필 스케치, 다른 사람은 클레이 애니메이션 사람입니다.' -
Nano Banana Pro로 생성됨 프롬프트: '검색을 사용하여 Gemini 3 Flash 출시가 어떻게 받아들여졌는지 알아봐. 이 정보를 사용하여 제목이 있는 짧은 기사를 작성하세요. 디자인에 중점을 둔 광택 잡지에 표시된 기사의 사진을 반환해 줘. Gemini 3 Flash에 관한 기사를 보여주는 단일 페이지가 접혀 있는 사진입니다. 히어로 사진 1장 광고 제목은 세리프입니다.' -
Nano Banana Pro로 생성됨 프롬프트: '귀여운 강아지를 나타내는 아이콘. 배경은 흰색입니다. 아이콘을 다채롭고 촉각적인 3D 스타일로 만들어 줘. 텍스트가 없습니다.' -
Nano Banana 2로 생성됨 프롬프트: '완벽한 등각 투영법으로 사진을 만들어 줘. 미니어처가 아니라 완벽한 등각 투영법으로 촬영된 사진입니다. 아름다운 현대식 정원의 사진입니다. 2 모양의 큰 수영장과 'Nano Banana 2'라는 단어가 있습니다.'
Nano Banana는 Gemini의 기본 이미지 생성 기능의 이름입니다. Gemini는 텍스트, 이미지 또는 둘 다를 조합하여 대화형으로 이미지를 생성하고 처리할 수 있습니다. 이를 통해 전례 없이 세밀하게 제어하면서 시각적 요소를 만들고, 수정하고, 반복할 수 있습니다.
Nano Banana는 Gemini API에서 사용할 수 있는 4가지 고유한 모델을 의미합니다.
- Nano Banana 2 Lite (Gemini 3.1 Flash Lite Image)
(
gemini-3.1-flash-lite-image): 속도와 비용이 주요 운영 제약 조건인 환경에서 속도와 확장성을 위해 설계된 가장 빠르고 저렴한 Gemini 이미지 모델입니다. 여러 참조 입력 또는 멀티턴 순차 편집에 최적화되어 있지 않습니다. - Nano Banana 2 (Gemini 3.1 Flash Image)
(
gemini-3.1-flash-image): 모든 작업을 위한 가장 다재다능한 모델이자 일반적인 워크호스 모델입니다. 속도와 최첨단 4K 생성, 세계에 관한 지식, 안정적인 텍스트 렌더링의 균형을 맞춥니다. 여러 참고 이미지 처리 및 일관성에서 뛰어남 - Nano Banana Pro (Gemini 3 Pro Image)
(
gemini-3-pro-image): 가장 복잡한 시각적 작업을 위한 프리미엄 옵션으로, 최고 수준의 세계 지식, 고급 현지화, 정확한 브랜드 일관성, 정밀한 크리에이티브 컨트롤을 제공합니다. - Nano Banana (Gemini 2.5 Flash Image)
(
gemini-2.5-flash-image): Nano Banana 시리즈의 기존 선두 주자입니다. Nano Banana 2 Lite는 안정적인 성능을 제공하지만, 향상된 품질, 더 빠른 생성 속도, 더 낮은 API 가격을 경험하려면 Nano Banana 2 Lite로 전환하는 것이 좋습니다.
생성된 모든 이미지에는 SynthID 워터마크가 포함됩니다.
이미지 생성 (텍스트 이미지 변환)
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme";
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}'
마지막으로 생성된 이미지 블록을 반환하는 interaction.output_image 속성을 사용하여 생성된 이미지 데이터를 가져올 수 있습니다. 편의 속성에 관한 자세한 내용은 상호작용 개요를 참고하세요.
이미지 편집 (텍스트 및 이미지 간)
참고: 업로드하는 이미지에 대한 필요한 권리를 보유하고 있는지 확인하세요. 속이거나, 괴롭히거나, 피해를 입히는 동영상 또는 이미지를 비롯해 다른 사람의 권리를 침해하는 콘텐츠를 생성하면 안 됩니다. 이 생성형 AI 서비스의 사용에는 Google의 금지된 사용 정책이 적용됩니다.
이미지를 제공하고 텍스트 프롬프트를 사용하여 요소를 추가, 삭제 또는 수정하거나, 스타일을 변경하거나, 색상 그레이딩을 조정합니다.
다음 예에서는 base64로 인코딩된 이미지를 업로드하는 방법을 보여줍니다.
여러 이미지, 더 큰 페이로드, 지원되는 MIME 유형은 이미지 이해 페이지를 참고하세요.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open("/path/to/cat_image.png", "rb") as f:
image_bytes = f.read()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "path/to/cat_image.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ type: "text", text: "Create a picture of my cat eating a nano-banana in a" +
"fancy restaurant under the Gemini constellation" },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation\"},
{
\"type\": \"image\",
\"mime_type\": \"image/jpeg\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
]
}"
멀티턴 이미지 수정
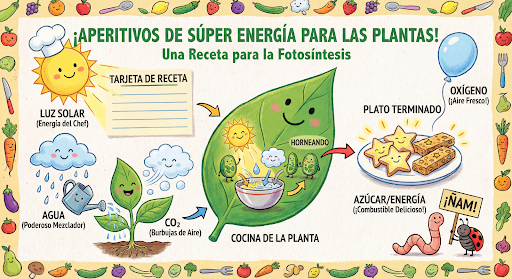
대화형으로 이미지를 계속 생성하고 수정하세요. 이미지를 반복하는 데는 멀티턴 대화가 권장됩니다. 다음 예에서는 광합성에 관한 인포그래픽을 생성하는 프롬프트를 보여줍니다.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools=[{"type": "google_search"}],
)
with open("photosynthesis.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const ai = new GoogleGenAI({});
async function main() {
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools: [{"type": "google_search"}],
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis.png", buffer);
console.log("Image saved as photosynthesis.png");
}
}
await main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plants favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids cookbook, suitable for a 4th grader."}
],
"tools": [{"type": "google_search"}]
}'

그런 다음 previous_interaction_id를 사용하여 그래픽의 언어를 스페인어로 변경할 수 있습니다.
Python
interaction_2 = client.interactions.create(
model="gemini-3.1-flash-image",
input="Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id=interaction.id,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
},
)
generated_image = interaction_2.output_image
if generated_image:
with open("photosynthesis_spanish.png", "wb") as f:
f.write(base64.b64decode(generated_image.data))
자바스크립트
const interaction2 = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id: interaction.id,
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const generatedImage = interaction2.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis_spanish.png", buffer);
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Update this infographic to be in Spanish. Do not change any other elements of the image.",
"previous_interaction_id": "<PREVIOUS_INTERACTION_ID>",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
Gemini 3 이미지 모델의 새로운 기능
Gemini 3는 최첨단 이미지 생성 및 편집 모델을 제공합니다. Gemini 3.1 Flash Image는 속도와 대량 사용 사례에 최적화되어 있으며 Gemini 3 Pro Image는 전문적인 애셋 제작에 최적화되어 있습니다. 고급 추론을 통해 가장 어려운 워크플로를 처리하도록 설계되었으며, 복잡한 다중 턴 생성 및 수정 작업에 탁월합니다.
- 고해상도 출력: 1K, 2K, 4K 시각적 요소를 생성하는 기능이 내장되어 있습니다.
- Gemini 3.1 Flash Image에 더 작은 512px (0.5K) 해상도가 추가되었습니다.
- Gemini 3.1 Flash Lite Image는 1K 해상도만 지원합니다.
- 고급 텍스트 렌더링: 인포그래픽, 메뉴, 다이어그램, 마케팅 애셋에 대해 읽기 쉽고 스타일이 지정된 텍스트를 생성할 수 있습니다.
- Google 검색을 통한 그라운딩: 모델이 Google 검색을 도구로 사용하여 사실을 확인하고 실시간 데이터 (예: 현재 날씨 지도, 주식 차트, 최근 이벤트)를 기반으로 이미지를 생성할 수 있습니다.
- Gemini 3.1 Flash-Lite 이미지 모델에서 지원되지 않습니다.
- Gemini 3.1 Flash Image는 웹 검색과 함께 Google 이미지 검색 그라운딩을 통합합니다.
- 사고 모드: 모델이 '사고' 과정을 활용하여 복잡한 프롬프트를 추론합니다. 최종 고화질 출력을 생성하기 전에 구도를 다듬기 위해 임시 '생각 이미지' (백엔드에 표시되지만 요금이 청구되지 않음)를 생성합니다.
- 최대 14개의 참고 이미지: 이제 최대 14개의 참고 이미지를 혼합하여 최종 이미지를 생성할 수 있습니다.
- 새 가로세로 비율: Gemini 3.1 Flash Lite Image에
1:1,3:2,2:3,3:4,4:3,4:5,5:4,9:16,16:9,21:9가로세로 비율이 추가됩니다.
최대 14개의 참조 이미지 사용
Gemini 3 이미지 모델을 사용하면 최대 14개의 참조 이미지를 혼합할 수 있습니다. 이러한 14개의 이미지에는 다음이 포함될 수 있습니다.
| Gemini 3.1 Flash Lite 이미지 | Gemini 3.1 Flash Image | Gemini 3 Pro Image |
|---|---|---|
| 최종 이미지에 포함할 충실도가 높은 객체의 이미지(최대 14개) | 최종 이미지에 포함할 충실도가 높은 객체의 이미지(최대 10개) | 최종 이미지에 포함할 충실도가 높은 객체의 이미지(최대 6개) |
| 해당 사항 없음 | 캐릭터 일관성을 유지하기 위한 캐릭터 이미지 최대 4개 | 캐릭터 일관성을 유지하기 위한 캐릭터 이미지 최대 5개 |
| 해당 사항 없음 | 해당 사항 없음 | 스타일 참조로 사용할 이미지 최대 3개 |
Python
from google import genai
from google.genai import types
from PIL import Image
import base64
prompt = "An office group photo of these people, they are making funny faces."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": prompt,
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
],
response_format={
"type": "image",
"aspect_ratio": "5:4",
"image_size": "2K"
},
)
with open("office.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const input = [
{
type: "text",
text: "An office group photo of these people, they are making funny faces.",
},
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile1 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile2 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile3 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile4 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile5 },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
response_format: {
type: "image",
aspect_ratio: "5:4",
image_size: "2K",
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('office.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"An office group photo of these people, they are making funny faces.\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_1>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_2>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_3>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_4>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_5>\"}
],
\"response_format\": {
\"type\": \"image\",
\"aspect_ratio\": \"5:4\",
\"image_size\": \"2K\"
}
}"

Google 검색을 사용하는 그라운딩
Google 검색 도구를 사용하여 날씨 예보, 주식 차트, 최근 이벤트와 같은 실시간 정보를 기반으로 이미지를 생성합니다.
이미지 생성과 함께 Google 검색을 사용한 그라운딩을 사용하는 경우 이미지 기반 검색 결과는 생성 모델에 전달되지 않으며 대답에서 제외됩니다 (Google 이미지 검색을 사용한 그라운딩 참고).
Python
from google import genai
from google.genai import types
import base64
prompt = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
tools=[{"type": "google_search"}],
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
},
)
with open("weather.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day",
tools: [{"type": "google_search"}],
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('weather.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"}
],
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
}
}'

대답에는 google_search_call 및 google_search_result 단계와 텍스트 단계의 인라인 url_citation 주석이 포함됩니다.
google_search_result: UI에서 검색어 추천을 렌더링하기 위한 HTML 스니펫인search_suggestions이 포함되어 있습니다.url_citation주석: 텍스트 단계의 인라인 인용으로, 대답의 일부를 웹 소스에 연결합니다.
Google 이미지 검색을 사용한 그라운딩 (3.1 Flash)
Google 이미지 검색을 사용한 그라운딩을 사용하면 모델이 Google 이미지 검색을 통해 검색된 웹 이미지를 이미지 생성의 시각적 컨텍스트로 사용할 수 있습니다. 이미지 검색은 기존의 Google 검색으로 그라운딩 도구 내에 있는 새로운 검색 유형으로, 표준 웹 검색과 함께 작동합니다.
이미지 검색을 사용 설정하려면 API 요청에서 google_search 도구를 구성하고 search_types 배열 내에서 image_search을 지정합니다. 이미지 검색은 독립적으로 또는 웹 검색과 함께 사용할 수 있습니다.
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A detailed painting of a Timareta butterfly resting on a flower",
tools=[{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
)
자바스크립트
import { GoogleGenAI } from "@google/genai";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A detailed painting of a Timareta butterfly resting on a flower",
tools: [{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
});
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A detailed painting of a Timareta butterfly resting on a flower",
"tools": [{"type": "google_search", "search_types": ["web_search", "image_search"]}]
}'
디스플레이 요구사항
Google 검색을 사용한 그라운딩 내에서 이미지 검색을 사용하는 경우 google_search_result 단계의 search_suggestions를 표시해야 합니다. 전체 사용 요구사항은 서비스 약관에 자세히 설명되어 있습니다.
응답
이미지 검색을 사용하는 그라운딩된 대답의 경우 API는 대답 단계의 일부로 인라인 인용 및 저작자 표시 메타데이터를 반환합니다.
url_citation주석:model_output내 텍스트 콘텐츠 블록의 인라인 인용으로, 생성된 콘텐츠를 소스에 연결합니다.google_search_result: UI에서 검색어 추천을 렌더링하기 위한 HTML 스니펫인search_suggestions이 포함되어 있습니다.
동영상 이미지 변환 생성 (3.1 Flash)
동영상-이미지 생성 기능을 사용하면 동영상의 컨텍스트를 멀티모달 참조로 사용하여 새로운 이미지를 생성할 수 있습니다. 이 기능은 고품질 동영상 썸네일, 영화 포스터, 요약 인포그래픽 또는 동영상 장면에서 영감을 받은 새로운 아트워크를 만드는 데 유용합니다.
생성 중에 모델은 맥락에 따라 동영상 프레임을 분석하여 시각적 테마와 주요 이벤트를 추출한 다음, 텍스트 프롬프트와 함께 사용하여 출력 이미지를 합성합니다.
API 요청에 공개 YouTube URL을 직접 전달하거나 Files API를 사용하여 로컬 동영상 파일을 업로드할 수 있습니다.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{"type": "text", "text": "Generate a poster image that captures the key themes of this video."}
],
response_format={"type": "image", "aspect_ratio": "16:9"}
)
# Save the generated image part
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("video_poster.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
print("Image saved as video_poster.png")
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "video",
uri: "https://www.youtube.com/watch?v=UTdfxFyOQTI",
mime_type: "video/mp4"
},
{ type: "text", text: "Generate a poster image that captures the key themes of this video." }
],
response_format: {
type: "image",
aspect_ratio: "16:9"
}
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("video_poster.png", buffer);
console.log("Image saved as video_poster.png");
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{
"type": "text",
"text": "Generate a poster image that captures the key themes of this video."
}
],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

최대 4K 해상도로 이미지 생성
Gemini 3 이미지 모델은 기본적으로 1K 이미지를 생성하지만 2K, 4K, 512px (0.5K) (Gemini 3.1 Flash Image만 해당) 이미지도 출력할 수 있습니다. 고해상도 애셋을 생성하려면 response_format에서 image_size을 지정합니다.
대문자 'K'를 사용해야 합니다(예: 512px (05.K), 1K, 2K, 4K). 소문자 매개변수 (예: 1k)는 거부됩니다.
Python
from google import genai
from google.genai import types
import base64
prompt = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
},
)
print(interaction.output_text)
with open("butterfly.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "1:1",
image_size: "1K",
},
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('butterfly.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
}
}'
다음은 이 프롬프트로 생성된 이미지의 예입니다.

사고 과정
Gemini 3 이미지 모델은 복잡한 프롬프트에 추론 프로세스 ('사고')를 사용하는 사고 모델입니다. 이 기능은 기본적으로 사용 설정되며 API에서 사용 중지할 수 없습니다. 사고 과정에 대해 자세히 알아보려면 Gemini 사고 가이드를 참고하세요.
모델은 구도와 논리를 테스트하기 위해 최대 2개의 임시 이미지를 생성합니다. Thinking 내의 마지막 이미지도 최종 렌더링된 이미지입니다.
최종 이미지가 생성된 이유를 확인할 수 있습니다.
Python
for step in interaction.steps:
if step.type == "thought":
for content_block in step.summary:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
image = Image.open(io.BytesIO(base64.b64decode(content_block.data)))
image.show()
자바스크립트
for (const step of interaction.steps) {
if (step.type === "thought") {
for (const contentBlock of step.summary) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, 'base64');
fs.writeFileSync('thought_image.png', buffer);
}
}
}
}
인터리브 처리된 텍스트 및 이미지
표준 이미지 생성 모델은 이미지만 출력하지만 일부 고급 Gemini 3 모델 (예: gemini-3-pro-image)은 텍스트 블록과 삽화가 동일한 대답 내에 모두 포함된 스토리나 안내 가이드와 같은 인터리브 콘텐츠를 생성할 수 있습니다.
출력이 복잡하고 인터리브되어 있으므로 .output_image 또는 .output_text과 같은 편의 속성은 전체 시퀀스를 캡처하지 않습니다. 인터리브 콘텐츠에 액세스하고 저장하려면 steps를 수동으로 반복해야 합니다.
Python
interaction = client.interactions.create(
model="gemini-3-pro-image",
input="Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
)
image_counter = 1
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
filename = f"butterfly_lifecycle_{image_counter}.png"
with open(filename, "wb") as f:
f.write(base64.b64decode(content_block.data))
print(f"\n[Saved illustration: {filename}]\n")
image_counter += 1
자바스크립트
const interaction = await ai.interactions.create({
model: "gemini-3-pro-image",
input: "Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
});
let imageCounter = 1;
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
const filename = `butterfly_lifecycle_${imageCounter}.png`;
fs.writeFileSync(filename, buffer);
console.log(`\n[Saved illustration: ${filename}]\n`);
imageCounter++;
}
}
}
}
사고 수준 제어
Gemini 3.1 Flash Image를 사용하면 모델이 품질과 지연 시간의 균형을 맞추기 위해 사용하는 사고량을 제어할 수 있습니다. 기본 thinking_level은 minimal이고 지원되는 수준은 minimal 및 high입니다.
Python
from google import genai
from PIL import Image
import base64
import io
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A futuristic city built inside a giant glass bottle floating in space",
generation_config={"thinking_level": "high"},
)
print(interaction.output_text)
image = Image.open(io.BytesIO(base64.b64decode(interaction.output_image.data)))
image.show()
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A futuristic city built inside a giant glass bottle floating in space",
generation_config: { thinking_level: "high" },
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('image.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A futuristic city built inside a giant glass bottle floating in space",
"generation_config": {
"thinking_level": "high"
}
}'
사고 과정은 과정을 보든 안 보든 항상 기본적으로 발생하므로 사고 모델의 경우 사고 토큰이 기본적으로 청구됩니다.
기타 이미지 생성 모드
대부분의 사용 사례에는 Nano Banana 이미지 생성 모델이 권장되지만, 다음과 같은 전용 이미지 생성 모델을 살펴볼 수도 있습니다.
일괄적으로 이미지 생성
이 페이지에 설명된 모든 이미지 생성 기능은 Batch API를 사용하여 일괄 작업으로 실행할 수도 있습니다. 많은 이미지를 생성해야 하는 경우에 적합합니다. 최대 24시간의 처리 시간이 소요되는 대신 더 높은 비율 제한이 적용됩니다.
프롬프트 가이드 및 전략
이 섹션에서는 일반적인 이미지 생성 및 수정 워크플로의 프롬프트 예시와 템플릿을 제공합니다. 각 예에는 재사용 가능한 템플릿과 Interactions API의 샘플 프롬프트가 포함되어 있습니다.
이미지 생성 프롬프트
다음 예시에서는 텍스트 프롬프트를 사용하여 다양한 유형의 이미지를 생성하는 방법을 보여줍니다.
1. 사실적인 장면
장면을 자세히 설명해 줘. 구체적일수록 결과를 더 많이 제어할 수 있습니다.
템플릿
A photorealistic [type of shot] of a [subject description] in a [setting
description]. [Description of the light]. Shot from a [camera angle]
with a [lens type].
프롬프트
A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format=[
{
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
}
],
)
print(interaction.output_text)
with open("coral_reef.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format: [
{
type: "image",
mime_type: "image/jpeg",
aspect_ratio: "16:9",
}
],
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('coral_reef.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
"response_format": {
"type": "image",
"mime_type": "image/png",
"aspect_ratio": "16:9"
}
}'

2. 세련된 삽화 및 스티커
예술적 스타일, 주제, 매체를 설명합니다. 일관된 결과를 얻으려면 시각적 세부정보 (굵은 선, 색상 등)를 구체적으로 지정하세요.
템플릿
A [style] of a [subject, with details about accessories or actions]
doing [activity]. The design features [visual qualities, e.g., bold outlines,
cel-shading, etc.] and [color/background preference].
프롬프트
A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("red_panda_sticker.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("red_panda_sticker.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It is munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white."
}'

3. 이미지의 정확한 텍스트
Gemini는 텍스트 렌더링에 탁월합니다. 텍스트, 글꼴 스타일(설명), 전체 디자인을 명확하게 설명하세요. Gemini 3 Pro Image를 사용하여 전문적인 애셋을 제작하세요.
템플릿
Create a [image type] for [brand/concept] with the text "[text to render]"
in a [font style]. The design should be [style description], with a
[color scheme].
프롬프트
Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format={"type": "image", "aspect_ratio": "1:1"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("logo_example.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format: { type: "image", aspect_ratio: "1:1" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("logo_example.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a modern, minimalist logo for a coffee shop called The Daily Grind. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
"response_format": {
"type": "image",
"aspect_ratio": "1:1"
}
}'
4. 제품 모형 및 상업용 사진
전자상거래, 광고 또는 브랜딩을 위한 깔끔하고 전문적인 제품 사진을 만드는 데 적합합니다.
템플릿
A high-resolution, studio-lit product photograph of a [product description]
on a [background surface/description]. The lighting is a [lighting setup,
e.g., three-point softbox setup] to [lighting purpose]. The camera angle is
a [angle type] to showcase [specific feature]. Ultra-realistic, with sharp
focus on [key detail]. [Aspect ratio].
프롬프트
A high-resolution, studio-lit product photograph of a minimalist ceramic
coffee mug in matte black, presented on a polished concrete surface. The
lighting is a three-point softbox setup designed to create soft, diffused
highlights and eliminate harsh shadows. The camera angle is a slightly
elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with
sharp focus on the steam rising from the coffee. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("product_mockup.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("product_mockup.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image."
}'

5. 미니멀리스트 및 네거티브 스페이스 디자인
텍스트가 오버레이되는 웹사이트, 프레젠테이션 또는 마케팅 자료의 배경을 만드는 데 적합합니다.
템플릿
A minimalist composition featuring a single [subject] positioned in the
[bottom-right/top-left/etc.] of the frame. The background is a vast, empty
[color] canvas, creating significant negative space. Soft, subtle lighting.
[Aspect ratio].
프롬프트
A minimalist composition featuring a single, delicate red maple leaf
positioned in the bottom-right of the frame. The background is a vast, empty
off-white canvas, creating significant negative space for text. Soft,
diffused lighting from the top left. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("minimalist_design.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("minimalist_design.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image."
}'

6. 연속적인 아트 (만화 패널 / 스토리보드)
캐릭터 일관성 및 장면 설명을 기반으로 시각적 스토리텔링을 위한 패널을 만듭니다. 텍스트의 정확성과 스토리텔링 능력을 위해 이러한 프롬프트는 Gemini 3 Pro 및 Gemini 3.1 Flash Image와 함께 사용하는 것이 가장 좋습니다.
템플릿
Make a 3 panel comic in a [style]. Put the character in a [type of scene].
프롬프트
Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/jpeg"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("comic_panel.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/man_in_white_glasses.jpg";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene." },
{
type: "image",
mime_type: "image/jpeg",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("comic_panel.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."},
{"type": "image", "data": "<BASE64_IMAGE_DATA>", "mime_type": "image/jpeg"}
]
}'
입력 |
출력 |

|

|
7. Google 검색을 사용하는 그라운딩
Google 검색을 사용하여 최근 또는 실시간 정보를 기반으로 이미지를 생성합니다. 이는 뉴스, 날씨, 기타 시간에 민감한 주제에 유용합니다.
프롬프트
Make a simple but stylish graphic of last night's Arsenal game in the Champion's League
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools=[{"type": "google_search"}],
response_format={"type": "image", "aspect_ratio": "16:9"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("football-score.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools: [{ type: "google_search" }],
response_format: { type: "image", aspect_ratio: "16:9", image_size: "2K" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("football-score.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Make a simple but stylish graphic of last nights Arsenal game in the Champions League",
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

이미지 수정 프롬프트
이 예시에서는 수정, 구성, 스타일 전송을 위해 텍스트 프롬프트와 함께 이미지를 제공하는 방법을 보여줍니다.
1. 요소 추가 및 삭제
이미지를 제공하고 변경사항을 설명하세요. 모델은 원본 이미지의 스타일, 조명, 원근법과 일치합니다.
템플릿
Using the provided image of [subject], please [add/remove/modify] [element]
to/from the scene. Ensure the change is [description of how the change should
integrate].
프롬프트
"Using the provided image of my cat, please add a small, knitted wizard hat
on its head. Make it look like it's sitting comfortably and matches the soft
lighting of the photo."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/cat_photo.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("cat_with_hat.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/cat_photo.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off." },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("cat_with_hat.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off.\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"}
]
}"
입력 |
출력 |

|

|
2. 인페인팅 (시맨틱 마스킹)
대화형으로 '마스크'를 정의하여 이미지의 특정 부분을 수정하고 나머지는 그대로 둡니다.
템플릿
Using the provided image, change only the [specific element] to [new
element/description]. Keep everything else in the image exactly the same,
preserving the original style, lighting, and composition.
프롬프트
"Using the provided image of a living room, change only the blue sofa to be
a vintage, brown leather chesterfield sofa. Keep the rest of the room,
including the pillows on the sofa and the lighting, unchanged."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/living_room.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("living_room_edited.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/living_room.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("living_room_edited.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged.\"}
]
}"
입력 |
출력 |

|

|
3. 스타일 전이
이미지를 제공하고 모델에 다른 예술적 스타일로 콘텐츠를 다시 만들도록 요청합니다.
템플릿
Transform the provided photograph of [subject] into the artistic style of [artist/art style]. Preserve the original composition but render it with [description of stylistic elements].
프롬프트
"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/city.png', 'rb') as f:
image_bytes = f.read()
text_input = """Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("city_style_transfer.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imageData = fs.readFileSync("/path/to/your/city.png");
const base64Image = imageData.toString("base64");
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows." },
],
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("city_style_transfer.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows.\"}
]
}"
입력 |
출력 |

|

|
4. 고급 합성: 여러 이미지 결합
여러 이미지를 컨텍스트로 제공하여 새로운 합성 장면을 만듭니다. 제품 모형이나 창의적인 콜라주에 적합합니다.
템플릿
Create a new image by combining the elements from the provided images. Take
the [element from image 1] and place it with/on the [element from image 2].
The final image should be a [description of the final scene].
프롬프트
"Create a professional e-commerce fashion photo. Take the blue floral dress
from the first image and let the woman from the second image wear it.
Generate a realistic, full-body shot of the woman wearing the dress, with
the lighting and shadows adjusted to match the outdoor environment."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/dress.png', 'rb') as f:
dress_bytes = f.read()
with open('/path/to/your/model.png', 'rb') as f:
model_bytes = f.read()
text_input = """Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(dress_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(model_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("fashion_ecommerce_shot.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/dress.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/model.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image1
},
{
type: "image",
mime_type: "image/png",
data: base64Image2
},
{ type: "text", text: "Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("fashion_ecommerce_shot.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment.\"}
}]
}"
입력 1 |
입력 2 |
출력 |

|

|

|
5. 충실도 높은 세부정보 보존
편집 중에 얼굴이나 로고와 같은 중요한 세부정보가 보존되도록 하려면 편집 요청과 함께 세부정보를 자세히 설명하세요.
템플릿
Using the provided images, place [element from image 2] onto [element from
image 1]. Ensure that the features of [element from image 1] remain
completely unchanged. The added element should [description of how the
element should integrate].
프롬프트
"Take the first image of the woman with brown hair, blue eyes, and a neutral
expression. Add the logo from the second image onto her black t-shirt.
Ensure the woman's face and features remain completely unchanged. The logo
should look like it's naturally printed on the fabric, following the folds
of the shirt."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/woman.png', 'rb') as f:
woman_bytes = f.read()
with open('/path/to/your/logo.png', 'rb') as f:
logo_bytes = f.read()
text_input = """Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(woman_bytes).decode('utf-8')},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(logo_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("woman_with_logo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/woman.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/logo.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image1},
{"type": "image", "mime_type":"image/png", "data": base64Image2},
{"type": "text", "text": "Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("woman_with_logo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt.\"}
]
}"
입력 1 |
입력 2 |
출력 |

|
|
|
6. 생동감 불어넣기
러프 스케치나 그림을 업로드하고 모델에 완성된 이미지로 다듬어 달라고 요청하세요.
템플릿
Turn this rough [medium] sketch of a [subject] into a [style description]
photo. Keep the [specific features] from the sketch but add [new details/materials].
프롬프트
"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/car_sketch.png', 'rb') as f:
sketch_bytes = f.read()
text_input = """Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(sketch_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("car_photo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/car_sketch.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image},
{"type": "text", "text": "Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("car_photo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting.\"}
]
}"
입력 |
출력 |

|

|
7. 캐릭터 일관성: 360도 뷰
다양한 각도를 반복적으로 요청하여 캐릭터의 360도 뷰를 생성할 수 있습니다. 최상의 결과를 얻으려면 일관성을 유지하기 위해 이전에 생성된 이미지를 후속 프롬프트에 포함하세요. 복잡한 포즈의 경우 선택한 포즈의 참조 이미지를 포함합니다.
템플릿
A studio portrait of [person] against [background], [looking forward/in profile looking right/etc.]
프롬프트
A studio portrait of this man against white, in profile looking right
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = """A studio portrait of this man against white, in profile looking right"""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input={
{"type": "text", "text": text_input},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(image_bytes).decode('utf-8')}
},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("man_right_profile.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
입력 |
출력 1 |
출력 2 |
|
|

|

|
권장사항
결과를 좋음에서 우수함으로 끌어올리려면 이러한 전문적인 전략을 워크플로에 통합하세요.
- 매우 구체적으로 작성: 세부정보를 많이 제공할수록 더 나은 결과를 얻을 수 있습니다. '판타지 갑옷' 대신 '은박 무늬가 새겨진 화려한 엘프 판금 갑옷, 높은 칼라와 매 날개 모양의 어깨 보호대를 갖추고 있다'라고 설명해 보세요.
- 컨텍스트와 의도 제공: 이미지의 목적을 설명합니다. 컨텍스트에 대한 모델의 이해가 최종 출력에 영향을 미칩니다. 예를 들어 '고급 미니멀리즘 스킨케어 브랜드를 위한 로고를 만들어 줘'가 '로고를 만들어 줘'보다 더 효과적입니다.
- 반복 및 개선: 첫 번째 시도에서 완벽한 이미지를 기대하지 마세요. 모델의 대화형 특성을 사용하여 약간의 변경사항을 적용합니다. '좋은데 조명을 좀 더 따뜻하게 해 줘' 또는 '다른 건 그대로 두고 캐릭터의 표정을 더 심각하게 바꿔 줘'와 같은 프롬프트로 후속 조치를 취합니다.
- 단계별 안내 사용: 요소가 많은 복잡한 장면의 경우 프롬프트를 단계로 나눕니다. '먼저 새벽의 고요하고 안개 낀 숲의 배경을 만들어 줘. 그런 다음 전경에 이끼로 덮인 고대 돌 제단을 추가하고 마지막으로 제단 위에 빛나는 검 하나를 놓아'
- '시맨틱 네거티브 프롬프트' 사용: '차가 없다'고 말하는 대신, 의도한 장면을 긍정적으로 묘사하세요.'교통의 흔적조차 없는 텅 빈, 황량한 거리'
- 카메라 제어: 사진 및 영화 촬영 언어를 사용하여 구도를 제어합니다.
wide-angle shot,macro shot,low-angle perspective와 같은 용어
제한사항
- 최상의 성능을 위해 다음 언어를 사용하세요. EN, ar-EG, de-DE, es-MX, fr-FR, hi-IN, id-ID, it-IT, ja-JP, ko-KR, pt-BR, ru-RU, ua-UA, vi-VN, zh-CN
- 이미지 생성은 오디오 입력을 지원하지 않습니다. 동영상 입력은 Gemini 3.1 Flash Image에서만 지원됩니다.
- 모델이 사용자가 명시적으로 요청한 정확한 수의 이미지 출력을 따르지 않을 수 있습니다.
gemini-2.5-flash-image는 최대 3개의 이미지를 입력으로 사용할 때 가장 잘 작동하며,gemini-3-pro-image는 충실도가 높은 이미지 5개와 최대 14개의 이미지를 지원합니다.gemini-3.1-flash-image는 단일 워크플로에서 최대 4자의 문자 유사성과 최대 10개의 객체 충실도를 지원합니다.- 이미지에 대한 텍스트를 생성할 때 먼저 텍스트를 생성한 다음 텍스트와 함께 이미지를 요청하면 Gemini가 가장 잘 작동합니다.
gemini-3.1-flash-image현재 Google 검색을 사용한 그라운딩은 웹 검색에서 실제 사람의 이미지를 사용하는 것을 지원하지 않습니다.- 생성된 모든 이미지에는 SynthID 워터마크가 포함됩니다.
선택적 구성
response_format 매개변수를 사용하여 출력 형식, 가로세로 비율, 이미지 크기를 선택적으로 구성할 수 있습니다.
출력 형식
모델은 기본적으로 텍스트와 이미지 응답을 모두 반환합니다. response_format 파라미터에 이미지 형식을 지정하여 생성된 이미지만 반환하도록 대답을 구성할 수 있습니다 (대화형 텍스트는 생략).
텍스트와 생성된 이미지 등 여러 모달리티를 요청하려면 response_format에 형식 항목 배열을 전달하세요.
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Write a short poem about a starry night and generate an image of it.",
response_format=[
{"type": "text"},
{"type": "image"},
],
)
자바스크립트
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Write a short poem about a starry night and generate an image of it.",
response_format: [
{ type: "text" },
{ type: "image" },
],
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Write a short poem about a starry night and generate an image of it.",
"response_format": [
{ "type": "text" },
{ "type": "image" }
]
}'
가로세로 비율 및 이미지 크기
기본적으로 모델은 출력 이미지 크기를 입력 이미지 크기에 맞추거나 1:1 정사각형을 생성합니다. type이 "image"로 설정된 경우 response_format 아래의 aspect_ratio 및 image_size 필드를 사용하여 출력 이미지의 가로세로 비율과 크기를 제어할 수 있습니다.
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K",
},
)
자바스크립트
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
response_format: {
type: "image",
aspect_ratio: "16:9",
image_size: "2K",
},
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
"response_format": {
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
사용 가능한 다양한 비율과 생성된 이미지의 크기는 다음 표에 나와 있습니다.
3.1 Flash 이미지
| 가로세로 비율 | 512px 해상도 | 토큰 500개 | 1K 해상도 | 토큰 1,000개 | 2K 해상도 | 토큰 2,000개 | 4K 해상도 | 4,000토큰 |
|---|---|---|---|---|---|---|---|---|
| 1:1 | 512x512 | 747 | 1024x1024 | 1120 | 2048x2048 | 1120 | 4096x4096 | 2000 |
| 1:4 | 256x1024 | 747 | 512x2048 | 1120 | 1024x4096 | 1120 | 2048x8192 | 2000 |
| 1:8 | 192x1536 | 747 | 384x3072 | 1120 | 768x6144 | 1120 | 1536x12288 | 2000 |
| 2:3 | 424x632 | 747 | 848x1264 | 1120 | 1696x2528 | 1120 | 3392x5056 | 2000 |
| 3:2 | 632x424 | 747 | 1264x848 | 1120 | 2528x1696 | 1120 | 5056x3392 | 2000 |
| 3:4 | 448x600 | 747 | 896x1200 | 1120 | 1792x2400 | 1120 | 3584x4800 | 2000 |
| 4:1 | 1024x256 | 747 | 2048x512 | 1120 | 4096x1024 | 1120 | 8192x2048 | 2000 |
| 4:3 | 600x448 | 747 | 1200x896 | 1120 | 2400x1792 | 1120 | 4800x3584 | 2000 |
| 4:5 | 464x576 | 747 | 928x1152 | 1120 | 1856x2304 | 1120 | 3712x4608 | 2000 |
| 5:4 | 576x464 | 747 | 1152x928 | 1120 | 2304x1856 | 1120 | 4608x3712 | 2000 |
| 8:1 | 1536x192 | 747 | 3072x384 | 1120 | 6144x768 | 1120 | 12288x1536 | 2000 |
| 9:16 | 384x688 | 747 | 768x1376 | 1120 | 1536x2752 | 1120 | 3072x5504 | 2000 |
| 16:9 | 688x384 | 747 | 1376x768 | 1120 | 2752x1536 | 1120 | 5504x3072 | 2000 |
| 21:9 | 792x168 | 747 | 1584x672 | 1120 | 3168x1344 | 1120 | 6336x2688 | 2000 |
3.1 Pro 이미지
| 가로세로 비율 | 1K 해상도 | 토큰 1,000개 | 2K 해상도 | 토큰 2,000개 | 4K 해상도 | 4,000토큰 |
|---|---|---|---|---|---|---|
| 1:1 | 1024x1024 | 1120 | 2048x2048 | 1120 | 4096x4096 | 2000 |
| 2:3 | 848x1264 | 1120 | 1696x2528 | 1120 | 3392x5056 | 2000 |
| 3:2 | 1264x848 | 1120 | 2528x1696 | 1120 | 5056x3392 | 2000 |
| 3:4 | 896x1200 | 1120 | 1792x2400 | 1120 | 3584x4800 | 2000 |
| 4:3 | 1200x896 | 1120 | 2400x1792 | 1120 | 4800x3584 | 2000 |
| 4:5 | 928x1152 | 1120 | 1856x2304 | 1120 | 3712x4608 | 2000 |
| 5:4 | 1152x928 | 1120 | 2304x1856 | 1120 | 4608x3712 | 2000 |
| 9:16 | 768x1376 | 1120 | 1536x2752 | 1120 | 3072x5504 | 2000 |
| 16:9 | 1376x768 | 1120 | 2752x1536 | 1120 | 5504x3072 | 2000 |
| 21:9 | 1584x672 | 1120 | 3168x1344 | 1120 | 6336x2688 | 2000 |
Gemini 2.5 Flash Image
| 가로세로 비율 | 해상도 | 토큰 |
|---|---|---|
| 1:1 | 1024x1024 | 1290 |
| 2:3 | 832x1248 | 1290 |
| 3:2 | 1248x832 | 1290 |
| 3:4 | 864x1184 | 1290 |
| 4:3 | 1184x864 | 1290 |
| 4:5 | 896x1152 | 1290 |
| 5:4 | 1152x896 | 1290 |
| 9:16 | 768x1344 | 1290 |
| 16:9 | 1344x768 | 1290 |
| 21:9 | 1536x672 | 1290 |
모델 선택
특정 사용 사례에 가장 적합한 모델을 선택합니다.
Gemini 3.1 Flash Image (Nano Banana 2)는 비용과 지연 시간의 균형을 맞추는 최고의 전반적인 성능과 인텔리전스를 갖춘 이미지 생성 모델입니다. 자세한 내용은 모델 가격 및 기능 페이지를 참고하세요.
Gemini 3.1 Flash Lite Image (Nano Banana 2 Lite)는 이미지 생성 제품군에서 가장 효율적인 모델로, 지연 시간이 매우 짧고 비용 효율적인 이미지 생성 및 편집 기능을 제공합니다. 자세한 내용은 모델 가격 및 기능 페이지를 참고하세요.
Gemini 3 Pro Image (Nano Banana Pro)는 전문적인 애셋 제작과 복잡한 안내를 위해 설계되었습니다. 이 모델은 Google 검색을 사용한 실제 그라운딩, 생성 전에 구성을 개선하는 기본 '생각' 프로세스를 특징으로 하며 최대 4K 해상도의 이미지를 생성할 수 있습니다. 자세한 내용은 모델 가격 및 기능 페이지를 참고하세요.
Gemini 2.5 Flash Image (Nano Banana)는 속도와 효율성을 위해 설계되었습니다. 이 모델은 대량의 낮은 지연 시간 태스크에 최적화되어 있으며 1024px 해상도로 이미지를 생성합니다. 자세한 내용은 모델 가격 및 기능 페이지를 참고하세요.
Imagen을 사용해야 하는 경우
Gemini의 기본 제공 이미지 생성 기능 사용 외에도 Gemini API를 통해 Google의 특화된 이미지 생성 모델인 Imagen에도 액세스할 수 있습니다. 폐쇄일 전에 마이그레이션하세요.