Gemini API มีการตั้งค่าความปลอดภัยที่คุณปรับได้ในระหว่าง ขั้นตอนการสร้างต้นแบบเพื่อพิจารณาว่าแอปพลิเคชันของคุณต้องมีการกำหนดค่าความปลอดภัยที่เข้มงวดมากขึ้นหรือน้อยลง คุณปรับการตั้งค่าเหล่านี้ได้ในหมวดหมู่ตัวกรอง 4 หมวดหมู่เพื่อจำกัดหรืออนุญาตเนื้อหาบางประเภท
คู่มือนี้ครอบคลุมวิธีที่ Gemini API จัดการการตั้งค่าความปลอดภัยและการกรอง รวมถึงวิธีเปลี่ยนการตั้งค่าความปลอดภัยสำหรับแอปพลิเคชัน
ตัวกรองความปลอดภัย
ฟิลเตอร์ความปลอดภัยที่ปรับได้ของ Gemini API ครอบคลุมหมวดหมู่ต่อไปนี้
| หมวดหมู่ | คำอธิบาย |
|---|---|
| การคุกคาม | ความคิดเห็นเชิงลบหรือเป็นอันตรายที่มุ่งเป้าไปที่อัตลักษณ์และ/หรือคุณลักษณะที่ได้รับการคุ้มครอง |
| วาจาสร้างความเกลียดชัง | เนื้อหาที่หยาบคาย ไม่ให้เกียรติ หรือหยาบคาย |
| เกี่ยวกับเรื่องเพศอย่างโจ่งแจ้ง | มีการอ้างอิงถึงการกระทำทางเพศหรือเนื้อหาอื่นๆ ที่ไม่เหมาะสม |
| อันตราย | ส่งเสริม สนับสนุน หรือก่อให้เกิดการกระทําที่เป็นอันตราย |
หมวดหมู่เหล่านี้กำหนดไว้ใน HarmCategory
คุณใช้ตัวกรองเหล่านี้เพื่อปรับสิ่งที่เหมาะสมกับกรณีการใช้งานของคุณได้ ตัวอย่างเช่น หากคุณกำลังสร้างบทสนทนาในวิดีโอเกม คุณอาจพิจารณาว่ายอมรับได้ที่จะ
อนุญาตเนื้อหาเพิ่มเติมที่จัดประเภทเป็นอันตรายเนื่องจากลักษณะของเกม
นอกจากตัวกรองความปลอดภัยที่ปรับได้แล้ว Gemini API ยังมีการป้องกันในตัว เพื่อป้องกันอันตรายหลักๆ เช่น เนื้อหาที่ทำให้ความปลอดภัยของเด็กตกอยู่ในอันตราย ระบบจะบล็อกการกระทำที่เป็นอันตรายประเภทนี้เสมอและปรับเปลี่ยนไม่ได้
ระดับการกรองความปลอดภัยของเนื้อหา
Gemini API จะจัดหมวดหมู่ระดับความน่าจะเป็นที่เนื้อหาไม่ปลอดภัยเป็น
HIGH, MEDIUM, LOW หรือ NEGLIGIBLE
Gemini API จะบล็อกเนื้อหาตามความน่าจะเป็นที่เนื้อหาจะไม่ปลอดภัย ไม่ใช่ความรุนแรง คุณควรพิจารณาเรื่องนี้เนื่องจากเนื้อหาบางอย่างอาจมีความเป็นไปได้ต่ำที่จะไม่ปลอดภัยแม้ว่าความรุนแรงของอันตรายจะยังสูงอยู่ก็ตาม ตัวอย่างเช่น การเปรียบเทียบประโยคต่อไปนี้
- หุ่นยนต์ต่อยฉัน
- หุ่นยนต์ฟันฉัน
ประโยคแรกอาจมีแนวโน้มที่จะไม่ปลอดภัยสูงกว่า แต่คุณอาจพิจารณาว่าประโยคที่ 2 มีความรุนแรงสูงกว่าในแง่ของความรุนแรง ด้วยเหตุนี้ คุณจึงควรทดสอบอย่างรอบคอบและพิจารณาว่าจำเป็นต้องบล็อกในระดับใดเพื่อรองรับกรณีการใช้งานที่สำคัญในขณะที่ลดอันตรายต่อผู้ใช้ปลายทาง
การกรองความปลอดภัยต่อคำขอ
คุณปรับการตั้งค่าความปลอดภัยสำหรับคำขอแต่ละรายการที่ส่งไปยัง API ได้ เมื่อคุณส่งคำขอ ระบบจะวิเคราะห์เนื้อหาและกำหนดคะแนนความปลอดภัย
การจัดประเภทความปลอดภัยประกอบด้วยหมวดหมู่และความน่าจะเป็นของการจัดประเภท
ที่เป็นอันตราย เช่น หากเนื้อหาถูกบล็อกเนื่องจากหมวดหมู่การคุกคาม
มีโอกาสสูง การจัดประเภทความปลอดภัยที่ส่งคืนจะมี
หมวดหมู่เท่ากับ HARASSMENT และกำหนดความน่าจะเป็นที่จะเกิดอันตรายเป็น HIGH
เนื่องจากโมเดลมีความปลอดภัยโดยธรรมชาติ ตัวกรองเพิ่มเติมจึงปิดอยู่โดยค่าเริ่มต้น หากเลือกเปิดใช้ คุณจะกำหนดค่าระบบให้บล็อกเนื้อหาตามความน่าจะเป็นที่จะไม่ปลอดภัยได้ ลักษณะการทำงานของโมเดลเริ่มต้นครอบคลุมกรณีการใช้งานส่วนใหญ่ ดังนั้นคุณควรปรับการตั้งค่าเหล่านี้ก็ต่อเมื่อแอปพลิเคชันของคุณต้องใช้ความสอดคล้องกันเท่านั้น
ตารางต่อไปนี้อธิบายการตั้งค่าการบล็อกที่คุณปรับได้สำหรับแต่ละ หมวดหมู่ เช่น หากตั้งค่าการบล็อกเป็นบล็อกบางส่วนสำหรับหมวดหมู่วาจาสร้างความเกลียดชัง ระบบจะบล็อกทุกอย่างที่มีแนวโน้มสูงที่จะเป็นเนื้อหาคำพูดที่สร้างความเกลียดชัง แต่จะอนุญาตให้ใช้ค่าที่มีความน่าจะเป็นต่ำกว่านั้น
| เกณฑ์ (Google AI Studio) | เกณฑ์ (API) | คำอธิบาย |
|---|---|---|
| ปิด | OFF |
ปิดตัวกรองความปลอดภัย |
| ไม่บล็อกเลย | BLOCK_NONE |
แสดงเสมอโดยไม่คำนึงถึงความน่าจะเป็นของเนื้อหาที่ไม่ปลอดภัย |
| บล็อกบางส่วน | BLOCK_ONLY_HIGH |
บล็อกเมื่อมีโอกาสสูงที่จะเป็นเนื้อหาที่ไม่ปลอดภัย |
| บล็อกบางรายการ | BLOCK_MEDIUM_AND_ABOVE |
บล็อกเมื่อมีโอกาสปานกลางหรือสูงที่จะเป็นเนื้อหาที่ไม่ปลอดภัย |
| บล็อกส่วนใหญ่ | BLOCK_LOW_AND_ABOVE |
บล็อกเมื่อมีโอกาสต่ำ ปานกลาง หรือสูงที่จะเป็นเนื้อหาที่ไม่ปลอดภัย |
| ไม่มี | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
ไม่ได้ระบุเกณฑ์ บล็อกโดยใช้เกณฑ์เริ่มต้น |
หากไม่ได้ตั้งค่าเกณฑ์ ระบบจะใช้เกณฑ์การบล็อกเริ่มต้นเป็นปิดสำหรับโมเดล Gemini 2.5 และ 3
คุณตั้งค่าเหล่านี้ได้สำหรับแต่ละคำขอที่ส่งไปยังบริการแบบ Generative
ดูรายละเอียดได้ที่ข้อมูลอ้างอิงของ API HarmBlockThreshold
ความคิดเห็นด้านความปลอดภัย
generateContent
จะแสดงผล
GenerateContentResponse ซึ่ง
รวมถึงความคิดเห็นด้านความปลอดภัย
ความคิดเห็นเกี่ยวกับพรอมต์จะรวมอยู่ใน
promptFeedback หากตั้งค่า
promptFeedback.blockReasonไว้ แสดงว่าเนื้อหาของพรอมต์ถูกบล็อก
ความคิดเห็นเกี่ยวกับคำตอบที่แนะนำจะรวมอยู่ใน
Candidate.finishReason และ
Candidate.safetyRatings หากเนื้อหาการตอบกลับ
ถูกบล็อกและfinishReasonเป็น SAFETY คุณสามารถตรวจสอบ
safetyRatings เพื่อดูรายละเอียดเพิ่มเติมได้ ระบบจะไม่คืนเนื้อหาที่ถูกบล็อก
ปรับการตั้งค่าความปลอดภัย
ส่วนนี้จะครอบคลุมวิธีปรับการตั้งค่าความปลอดภัยทั้งใน Google AI Studio และในโค้ด
Google AI Studio
คุณปรับการตั้งค่าความปลอดภัยได้ใน Google AI Studio
คลิกการตั้งค่าความปลอดภัยในส่วนการตั้งค่าขั้นสูงในแผงการตั้งค่าการเรียกใช้เพื่อเปิดโมดอลการตั้งค่าความปลอดภัย ในการเรียกใช้ ในโมดอล คุณสามารถใช้แถบเลื่อนเพื่อปรับ ระดับการกรองเนื้อหาตามหมวดหมู่ความปลอดภัยได้ ดังนี้
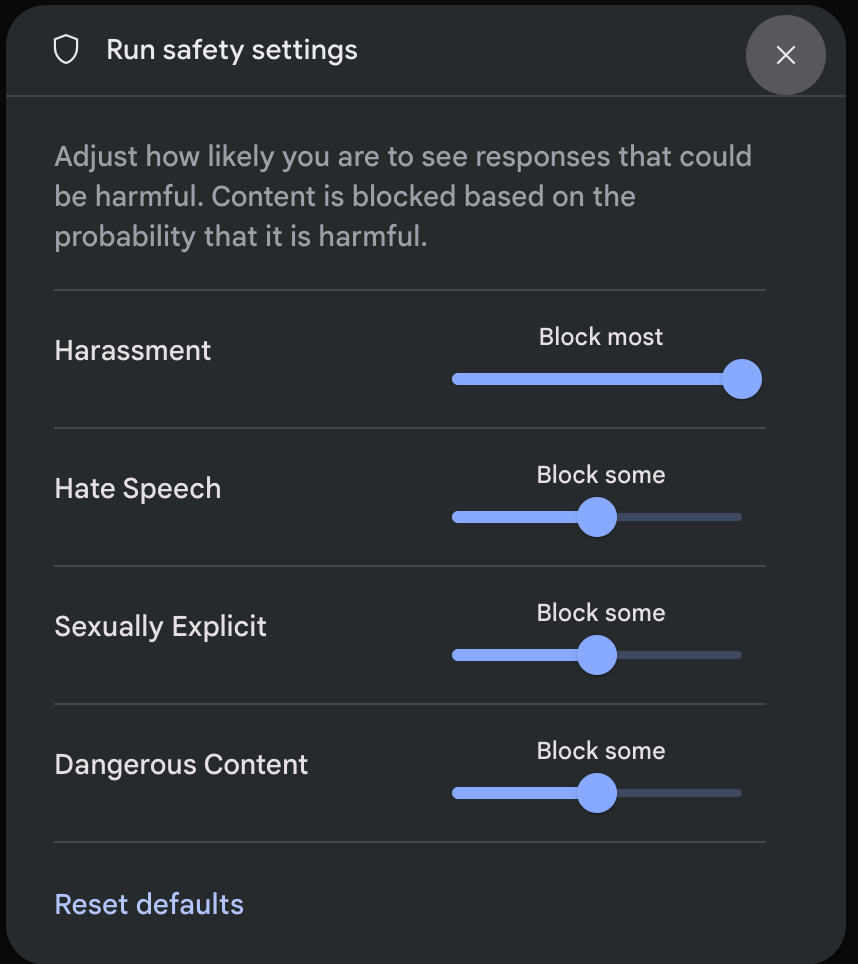
เมื่อคุณส่งคำขอ (เช่น ถามคำถามโมเดล) ข้อความ เนื้อหาถูกบล็อกจะปรากฏขึ้นหากเนื้อหาของคำขอถูกบล็อก หากต้องการดูรายละเอียดเพิ่มเติม ให้วางเคอร์เซอร์เหนือข้อความเนื้อหาถูกบล็อกเพื่อดูหมวดหมู่และความน่าจะเป็นของการจัดประเภทอันตราย
ตัวอย่างโค้ด
ข้อมูลโค้ดต่อไปนี้แสดงวิธีตั้งค่าความปลอดภัยในGenerateContent call ซึ่งจะเป็นการตั้งค่าเกณฑ์สำหรับหมวดหมู่วาจาสร้างความเกลียดชัง
(HARM_CATEGORY_HATE_SPEECH) การตั้งค่าหมวดหมู่นี้เป็น
BLOCK_LOW_AND_ABOVE จะบล็อกเนื้อหาที่มีโอกาสต่ำหรือสูงกว่า
ที่จะเป็นวาจาสร้างความเกลียดชัง หากต้องการทำความเข้าใจการตั้งค่าเกณฑ์ โปรดดูการกรองความปลอดภัย
ต่อคำขอ
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
ขั้นตอนถัดไป
- ดูข้อมูลเพิ่มเติมเกี่ยวกับ API ทั้งหมดได้ที่เอกสารอ้างอิง API
- อ่านคำแนะนำด้านความปลอดภัยเพื่อดูภาพรวมของข้อควรพิจารณาด้านความปลอดภัยเมื่อพัฒนาด้วย LLM
- ดูข้อมูลเพิ่มเติมเกี่ยวกับการประเมินความน่าจะเป็นเทียบกับความรุนแรงจากทีม Jigsaw
- ดูข้อมูลเพิ่มเติมเกี่ยวกับผลิตภัณฑ์ที่ช่วยสร้างโซลูชันด้านความปลอดภัย เช่น Perspective API * คุณสามารถใช้การตั้งค่าความปลอดภัยเหล่านี้เพื่อสร้างตัวแยกประเภทความเป็นพิษ ได้ ดูตัวอย่างการแยกประเภทเพื่อ เริ่มต้นใช้งาน