您可以在原型設計階段調整 Gemini API 的安全設定,判斷應用程式是否需要更嚴謹或寬鬆的安全設定。您可以調整這四個篩選器類別的設定,藉此限制或允許特定類型的內容。
本指南說明 Gemini API 如何處理安全設定和篩選,以及如何變更應用程式的安全設定。
安全篩選機制
Gemini API 的可調整安全篩選機制涵蓋下列類別:
| 類別 | 說明 |
|---|---|
| 騷擾 | 針對特定身分和/或受保護特質發表負面或有害言論。 |
| 仇恨言論 | 粗俗、不尊重或不雅的內容。 |
| 煽情露骨內容 | 提及性行為或其他猥褻情事的內容。 |
| 危險內容 | 宣傳、鼓吹或助長有害舉動。 |
這些類別定義於 HarmCategory。您可以運用這些篩選機制,根據使用情境將模型調整為適當的狀態。舉例來說,如果您要製作電玩遊戲對白,可能為配合遊戲風格,而允許較多遭評為「危險」的內容。
除了可調整的安全篩選機制,Gemini API 也內建核心危害內容防護措施,例如危害兒童安全的內容。系統一律會封鎖這類有害內容,無法調整。
內容安全篩選等級
Gemini API 會將內容不安全的機率分為 HIGH、MEDIUM、LOW 或 NEGLIGIBLE。
Gemini API 會根據內容不安全的機率封鎖內容,而非嚴重程度。請務必考慮這點,因為即使某些內容造成嚴重傷害的機率不高,舉例來說,比較以下句子:
- 機器人打了我。
- 機器人把我砍傷了。
第一句可能較容易被判定為不安全,但就暴力程度而言,您可能會認為第二句較為嚴重。因此,請務必仔細測試及考量適當的封鎖層級,以支援主要用途,同時盡量減少對使用者的傷害。
每個要求的安全篩選
在向 API 發出的每項要求,都可以調整安全設定。提出要求後,系統會分析內容並給予安全評分。安全評分指的是 Gemini 判斷內容屬於特定危害類別的機率。舉例來說,如果內容因屬於騷擾類別的機率高而遭到封鎖,系統傳回的安全評分會將類別設為 HARASSMENT,危害機率則設為 HIGH。
由於模型本身具有安全性,因此預設會關閉額外的篩選器。 如果選擇啟用,您可以設定系統根據內容不安全的機率封鎖內容。預設模型行為適用於大多數用途,因此建議不要隨意調整,除非這對應用程式而言是必要之舉。
下表說明各類別可調整的封鎖設定。舉例來說,如果將「仇恨言論」類別的封鎖設定設為「封鎖極少數內容」,系統就會封鎖仇恨言論機率高的內容。但機率較低的字詞則可使用。
| 門檻 (Google AI Studio) | 閾值 (API) | 說明 |
|---|---|---|
| 關閉 | OFF |
關閉安全篩選器 |
| 不封鎖任何內容 | BLOCK_NONE |
無論不安全的機率為何,一律顯示內容 |
| 封鎖極少數內容 | BLOCK_ONLY_HIGH |
封鎖不安全機率高的內容 |
| 封鎖一些 | BLOCK_MEDIUM_AND_ABOVE |
封鎖有害機率中等或較高的內容 |
| 封鎖多數內容 | BLOCK_LOW_AND_ABOVE |
封鎖有害機率低、中等或高的內容 |
| 不適用 | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
未指定門檻,使用預設門檻封鎖 |
如未設定門檻,Gemini 2.5 和 3 模型預設會停用封鎖門檻。
您可以針對向生成服務發出的每項要求設定這些設定。
詳情請參閱 HarmBlockThreshold API 參考資料。
安全意見回饋
generateContent 會傳回 GenerateContentResponse,其中包含安全意見回饋。
提示意見回饋會計入 promptFeedback。如果設定 promptFeedback.blockReason,表示提示內容遭到封鎖。
回應候選人意見回饋會納入 Candidate.finishReason 和 Candidate.safetyRatings。如果回應內容遭到封鎖,且 finishReason 為 SAFETY,您可以檢查 safetyRatings 來瞭解詳情。但不會傳回遭封鎖的內容。
調整安全性設定
本節說明如何在 Google AI Studio 和程式碼中調整安全設定。
Google AI Studio
您可以在 Google AI Studio 中調整安全設定。
在「執行設定」面板中,按一下「進階設定」下方的「安全設定」,開啟「執行安全設定」模式。在強制回應中,您可以使用滑桿,依安全類別調整內容篩選等級:
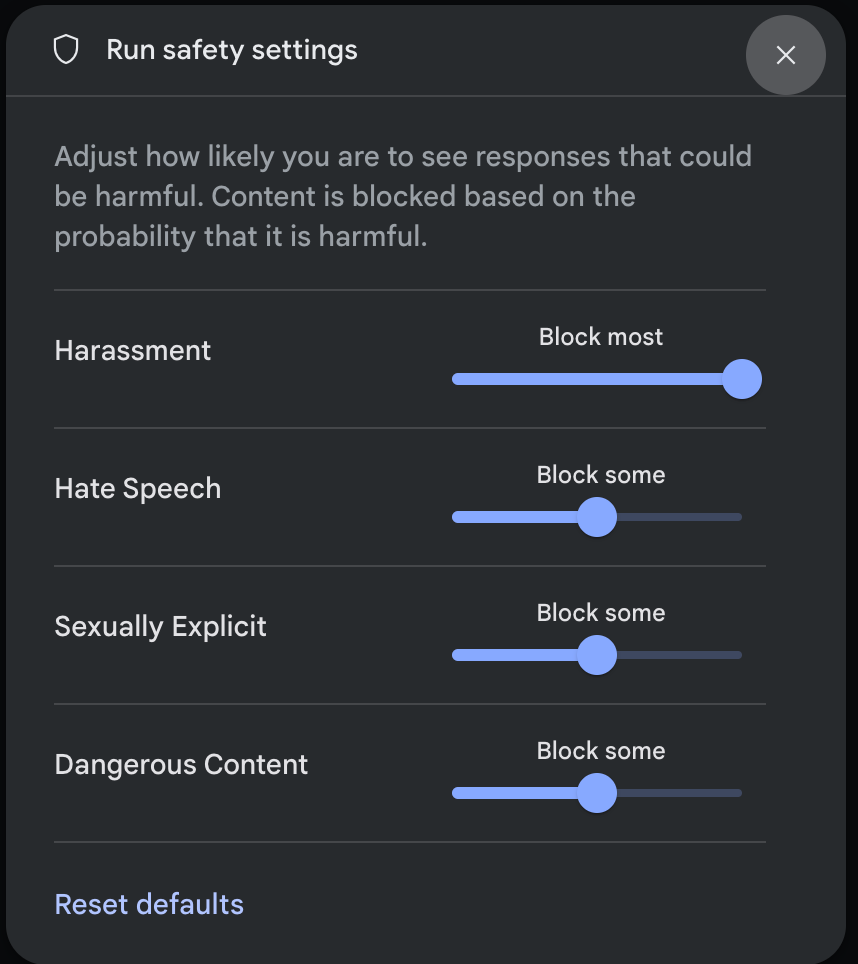
當您傳送要求 (例如向模型提問) 時,如果要求內容遭到封鎖,系統會顯示「內容遭到封鎖」 訊息。如要查看更多詳細資料,請將指標懸停在「內容已封鎖」文字上,即可查看類別和危害分類的機率。
程式碼範例
下列程式碼片段顯示如何在 GenerateContent 呼叫中設定安全設定。這會設定仇恨言論 (HARM_CATEGORY_HATE_SPEECH) 類別的門檻。將這類內容設為「封鎖」BLOCK_LOW_AND_ABOVE,系統就會封鎖任何仇恨言論機率偏高的內容。如要瞭解門檻設定,請參閱「依要求進行安全篩選」。
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
後續步驟
- 如要進一步瞭解完整 API,請參閱 API 參考資料。
- 如要瞭解使用 LLM 開發時應注意的安全事項,請參閱安全指南。
- 如要進一步瞭解如何評估機率與嚴重程度,請參閱 Jigsaw 團隊的說明
- 進一步瞭解有助於安全解決方案的產品,例如 Perspective API。* 您可以使用這些安全設定建立毒性分類器。如要開始使用,請參閱分類範例。