Gemini API में सुरक्षा सेटिंग उपलब्ध होती हैं. इन्हें प्रोटोटाइपिंग के दौरान अडजस्ट किया जा सकता है. इससे यह तय किया जा सकता है कि आपके ऐप्लिकेशन के लिए, सुरक्षा से जुड़ी ज़्यादा या कम पाबंदियों वाले कॉन्फ़िगरेशन की ज़रूरत है. इन सेटिंग को फ़िल्टर की चार कैटगरी में बदला जा सकता है. इससे कुछ खास तरह के कॉन्टेंट को दिखाने या छिपाने का विकल्प मिलता है.
इस गाइड में बताया गया है कि Gemini API, सुरक्षा सेटिंग और फ़िल्टर करने की सुविधा को कैसे मैनेज करता है. साथ ही, इसमें यह भी बताया गया है कि अपने ऐप्लिकेशन के लिए सुरक्षा सेटिंग कैसे बदली जा सकती हैं.
सेफ़्टी फ़िल्टर
Gemini API के सेफ़्टी फ़िल्टर को अडजस्ट किया जा सकता है. ये फ़िल्टर इन कैटगरी को कवर करते हैं:
| कैटगरी | ब्यौरा |
|---|---|
| उत्पीड़न | किसी व्यक्ति की पहचान और/या सुरक्षित रखे गए एट्रिब्यूट को लेकर की गई नकारात्मक या नुकसान पहुंचाने वाली टिप्पणियां. |
| नफ़रत फैलाने वाली भाषा | ऐसा कॉन्टेंट जो अशिष्ट, अपमानजनक या अपशब्दों से भरा हो. |
| अश्लील | ऐसी टिप्पणी जिसमें यौन गतिविधियों या अश्लील भाषा का इस्तेमाल किया गया हो. |
| खतरनाक | नुकसान पहुंचाने वाली गतिविधियों का प्रमोशन करता हो, उन्हें लागू करना आसान बनाता हो या उन्हें बढ़ावा देता हो. |
इन कैटगरी को HarmCategory में तय किया गया है. इन फ़िल्टर का इस्तेमाल करके, अपनी ज़रूरत के हिसाब से कॉन्टेंट को अडजस्ट किया जा सकता है. उदाहरण के लिए, अगर आपको वीडियो गेम के लिए डायलॉग बनाने हैं, तो गेम के हिसाब से आपको खतरनाक के तौर पर रेटिंग पाए कॉन्टेंट को शामिल करने की अनुमति देनी पड़ सकती है.
Gemini API में, सुरक्षा फ़िल्टर को अडजस्ट करने की सुविधा के साथ-साथ, बच्चों की सुरक्षा को खतरे में डालने वाले कॉन्टेंट जैसे गंभीर नुकसान से बचाने के लिए सुरक्षा के उपाय भी शामिल हैं. इस तरह के नुकसान को हमेशा ब्लॉक किया जाता है और इसमें बदलाव नहीं किया जा सकता.
कॉन्टेंट की सुरक्षा के लिए फ़िल्टर करने का लेवल
Gemini API, कॉन्टेंट के असुरक्षित होने की संभावना को इन कैटगरी में बांटता है:
HIGH, MEDIUM, LOW या NEGLIGIBLE.
Gemini API, कॉन्टेंट के असुरक्षित होने की संभावना के आधार पर उसे ब्लॉक करता है. यह कॉन्टेंट की गंभीरता के आधार पर फ़ैसला नहीं लेता. इस बात पर ध्यान देना ज़रूरी है, क्योंकि कुछ कॉन्टेंट के असुरक्षित होने की संभावना कम हो सकती है. हालांकि, इससे होने वाले नुकसान की गंभीरता अब भी ज़्यादा हो सकती है. उदाहरण के लिए, इन वाक्यों की तुलना करें:
- रोबोट ने मुझे मुक्का मारा.
- रोबोट ने मुझे काट दिया.
पहले वाक्य को असुरक्षित माना जा सकता है. हालांकि, हिंसा के लिहाज़ से दूसरे वाक्य को ज़्यादा गंभीर माना जा सकता है. इसलिए, यह ज़रूरी है कि आप ध्यान से जांच करें और यह तय करें कि आपके मुख्य इस्तेमाल के उदाहरणों के लिए, किस लेवल पर कुकी ब्लॉक करना सही रहेगा. साथ ही, यह भी ध्यान रखें कि इससे उपयोगकर्ताओं को कम से कम नुकसान हो.
हर अनुरोध के लिए सुरक्षा फ़िल्टरिंग
एपीआई से किए जाने वाले हर अनुरोध के लिए, सुरक्षा सेटिंग में बदलाव किया जा सकता है. अनुरोध करने पर, कॉन्टेंट का विश्लेषण किया जाता है और उसे सुरक्षा रेटिंग दी जाती है. सुरक्षा रेटिंग में, कैटगरी और नुकसान की आशंका के आधार पर क्लासिफ़िकेशन शामिल होता है. उदाहरण के लिए, अगर उत्पीड़न की कैटगरी के कॉन्टेंट के ब्लॉक होने की संभावना ज़्यादा होने की वजह से कॉन्टेंट ब्लॉक किया गया था, तो सुरक्षा रेटिंग में कैटगरी HARASSMENT के बराबर होगी और नुकसान की संभावना HIGH पर सेट होगी.
मॉडल की सुरक्षा से जुड़ी सुविधाओं की वजह से, अतिरिक्त फ़िल्टर डिफ़ॉल्ट रूप से बंद होते हैं. अगर आपने इन्हें चालू करने का विकल्प चुना है, तो सिस्टम को कॉन्फ़िगर किया जा सकता है. इससे, कॉन्टेंट के असुरक्षित होने की संभावना के आधार पर उसे ब्लॉक किया जा सकेगा. डिफ़ॉल्ट मॉडल का व्यवहार, ज़्यादातर इस्तेमाल के उदाहरणों पर लागू होता है. इसलिए, आपको इन सेटिंग में सिर्फ़ तब बदलाव करना चाहिए, जब आपके ऐप्लिकेशन के लिए लगातार एक जैसा व्यवहार ज़रूरी हो.
यहां दी गई टेबल में, हर कैटगरी के लिए ब्लॉक करने की उन सेटिंग के बारे में बताया गया है जिनमें बदलाव किया जा सकता है. उदाहरण के लिए, अगर आपने नफ़रत फैलाने वाले भाषण वाले कॉन्टेंट के लिए, ब्लॉक करने की सेटिंग को कुछ कॉन्टेंट ब्लॉक करें पर सेट किया है, तो नफ़रत फैलाने वाले भाषण की कैटगरी में आने वाले सभी कॉन्टेंट को ब्लॉक कर दिया जाएगा. हालांकि, कम संभावना वाले किसी भी प्रॉडक्ट को अनुमति दी जाती है.
| थ्रेशोल्ड (Google AI Studio) | थ्रेशोल्ड (एपीआई) | ब्यौरा |
|---|---|---|
| बंद है | OFF |
सुरक्षा फ़िल्टर बंद करना |
| किसी को ब्लॉक न करें | BLOCK_NONE |
असुरक्षित कॉन्टेंट की संभावना चाहे जो भी हो, हमेशा दिखाएं |
| कुछ लोगों को ब्लॉक करना | BLOCK_ONLY_HIGH |
असुरक्षित कॉन्टेंट के ज़्यादा संभावना होने पर ब्लॉक करें |
| कुछ को ब्लॉक करें | BLOCK_MEDIUM_AND_ABOVE |
असुरक्षित कॉन्टेंट की संभावना मध्यम या ज़्यादा होने पर ब्लॉक करें |
| ज़्यादातर को ब्लॉक करें | BLOCK_LOW_AND_ABOVE |
असुरक्षित कॉन्टेंट की कम, मध्यम या ज़्यादा संभावना होने पर ब्लॉक करें |
| लागू नहीं | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
थ्रेशोल्ड तय नहीं किया गया है. डिफ़ॉल्ट थ्रेशोल्ड का इस्तेमाल करके ब्लॉक करें |
अगर थ्रेशोल्ड सेट नहीं किया गया है, तो Gemini 2.5 और 3 मॉडल के लिए, ब्लॉक करने का डिफ़ॉल्ट थ्रेशोल्ड बंद है पर सेट होता है.
जनरेटिव सेवा से किए जाने वाले हर अनुरोध के लिए, इन सेटिंग को सेट किया जा सकता है.
ज़्यादा जानकारी के लिए, HarmBlockThreshold एपीआई रेफ़रंस देखें.
सुरक्षा से जुड़े सुझाव/राय देना या शिकायत करना
generateContent
a GenerateContentResponse दिखाता है, जिसमें सुरक्षा से जुड़ा फ़ीडबैक शामिल होता है.
प्रॉम्प्ट के बारे में सुझाव, शिकायत या राय देने की सुविधा promptFeedback में शामिल है. अगर promptFeedback.blockReason सेट है, तो इसका मतलब है कि प्रॉम्प्ट के कॉन्टेंट को ब्लॉक कर दिया गया है.
जवाब के उम्मीदवार के बारे में मिले सुझाव/राय/शिकायत को Candidate.finishReason और Candidate.safetyRatings में शामिल किया जाता है. अगर जवाब के कॉन्टेंट को ब्लॉक कर दिया गया था और finishReason SAFETY था, तो ज़्यादा जानकारी के लिए safetyRatings की जांच करें. ब्लॉक किए गए कॉन्टेंट को वापस नहीं लाया जाता.
सुरक्षा सेटिंग में बदलाव करना
इस सेक्शन में, Google AI Studio और आपके कोड, दोनों में सुरक्षा सेटिंग को अडजस्ट करने का तरीका बताया गया है.
Google AI Studio
Google AI Studio में जाकर, सुरक्षा सेटिंग में बदलाव किया जा सकता है.
रन सेटिंग पैनल में, ऐडवांस सेटिंग में जाकर सुरक्षा सेटिंग पर क्लिक करें. इससे रन सुरक्षा सेटिंग मॉडल खुल जाएगा. मोडल में, हर सुरक्षा कैटगरी के लिए कॉन्टेंट फ़िल्टर करने के लेवल में बदलाव करने के लिए, स्लाइडर का इस्तेमाल किया जा सकता है:
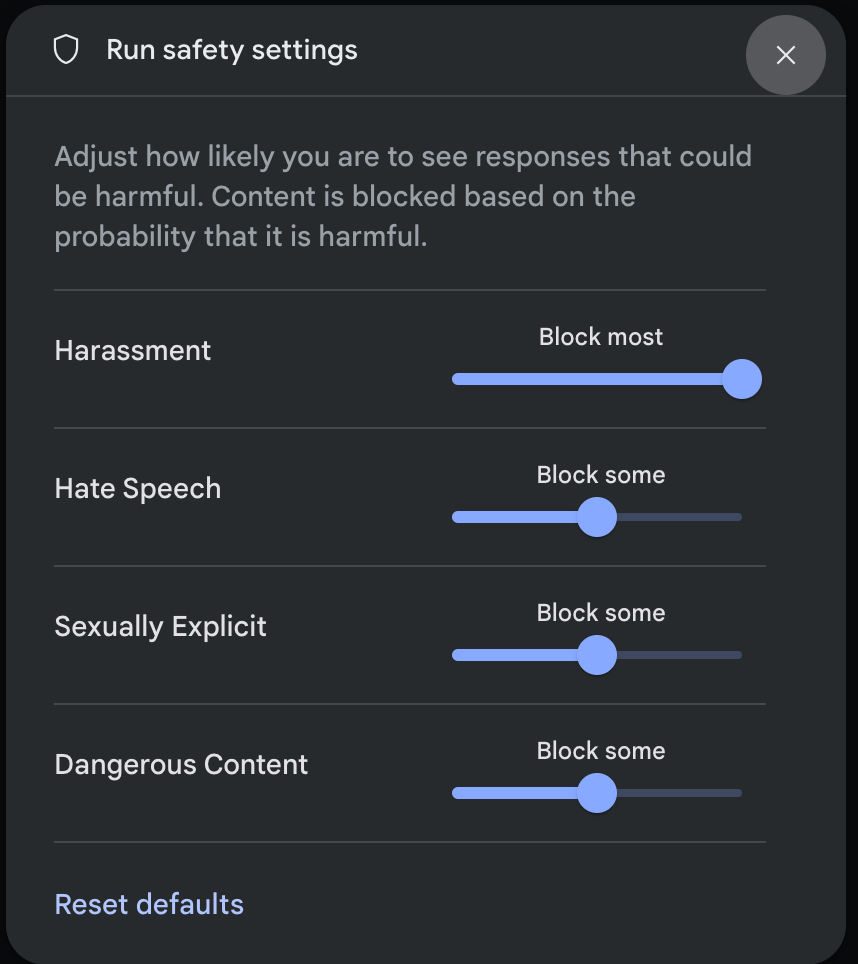
अनुरोध भेजने पर (उदाहरण के लिए, मॉडल से कोई सवाल पूछने पर), अगर अनुरोध के कॉन्टेंट को ब्लॉक किया गया है, तो कॉन्टेंट ब्लॉक किया गया मैसेज दिखता है. ज़्यादा जानकारी देखने के लिए, कॉन्टेंट ब्लॉक किया गया टेक्स्ट पर पॉइंटर घुमाएं. इससे आपको कैटगरी और नुकसान पहुंचाने वाले कॉन्टेंट के तौर पर क्लासिफ़ाई किए जाने की संभावना दिखेगी.
कोड के उदाहरण
यहां दिए गए कोड स्निपेट में, GenerateContent कॉल में सुरक्षा सेटिंग सेट करने का तरीका बताया गया है. इससे नफ़रत फैलाने वाली भाषा
(HARM_CATEGORY_HATE_SPEECH) कैटगरी के लिए थ्रेशोल्ड सेट होता है. इस कैटगरी को BLOCK_LOW_AND_ABOVE पर सेट करने से, नफ़रत फैलाने वाला ऐसा कॉन्टेंट ब्लॉक हो जाता है जिसमें नफ़रत फैलाने वाली भाषा का इस्तेमाल होने की संभावना कम या ज़्यादा होती है. थ्रेशोल्ड सेटिंग के बारे में जानने के लिए, हर अनुरोध के लिए, सुरक्षित खोज की सुविधा लेख पढ़ें.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
ऐप पर जाएं
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
अगले चरण
- पूरे एपीआई के बारे में ज़्यादा जानने के लिए, एपीआई के बारे में जानकारी देखें.
- एलएलएम का इस्तेमाल करके ऐप्लिकेशन डेवलप करते समय, सुरक्षा से जुड़ी बातों को ध्यान में रखने के बारे में जानने के लिए, सुरक्षा से जुड़े दिशा-निर्देश पढ़ें.
- Jigsaw टीम से, किसी समस्या के होने की संभावना और उसकी गंभीरता का आकलन करने के बारे में ज़्यादा जानें
- सुरक्षा से जुड़े समाधानों में मदद करने वाले प्रॉडक्ट के बारे में ज़्यादा जानें. जैसे, Perspective API. * इन सुरक्षा सेटिंग का इस्तेमाल करके, टॉक्सिसिटी क्लासिफ़ायर बनाया जा सकता है. शुरू करने के लिए, क्लासिफ़िकेशन का उदाहरण देखें.