Die Gemini API bietet Sicherheitseinstellungen, die Sie während der Prototyping-Phase anpassen können, um zu ermitteln, ob Ihre Anwendung eine mehr oder weniger restriktive Sicherheitskonfiguration erfordert. Sie können diese Einstellungen in vier Filterkategorien anpassen, um bestimmte Arten von Inhalten zuzulassen oder zu beschränken.
In diesem Leitfaden wird beschrieben, wie die Gemini API Sicherheitseinstellungen und ‑filterung handhabt und wie Sie die Sicherheitseinstellungen für Ihre Anwendung ändern können.
Sicherheitsfilter
Die anpassbaren Sicherheitsfilter der Gemini API decken die folgenden Kategorien ab:
| Kategorie | Beschreibung |
|---|---|
| Belästigung | Negative oder schädliche Kommentare, die auf Identität und/oder geschützte Merkmale ausgerichtet sind |
| Hassrede | Unhöfliche, respektlose oder vulgäre Inhalte. |
| Sexuell explizite Inhalte | Enthält Verweise auf sexuelle Handlungen oder andere vulgäre Inhalte |
| Gefährlich | Fördert oder erleichtert schädliche Handlungen oder ermuntert dazu. |
Diese Kategorien sind in HarmCategory definiert. Sie können diese Filter verwenden, um die für Ihren Anwendungsfall passenden Einstellungen vorzunehmen. Wenn Sie beispielsweise einen Dialog für ein Videospiel erstellen, halten Sie es aufgrund der Art des Spiels möglicherweise für akzeptabel, mehr Inhalte zuzulassen, die als gefährlich eingestuft wurden.
Zusätzlich zu den anpassbaren Sicherheitsfiltern bietet die Gemini API integrierte Schutzmaßnahmen gegen grundlegend schädliche Inhalte wie solche, die die Sicherheit von Kindern gefährden. Diese Arten von Schäden werden immer blockiert und können nicht angepasst werden.
Stufe der Inhaltsfilterung
Die Gemini API kategorisiert die Wahrscheinlichkeit, dass Inhalte unsicher sind, als HIGH, MEDIUM, LOW oder NEGLIGIBLE.
Die Gemini API blockiert Inhalte basierend auf der Wahrscheinlichkeit, dass Inhalte unsicher sind, nicht auf dem Schweregrad der Probleme. Dies ist wichtig, da einige Inhalte mit geringer Wahrscheinlichkeit unsicher sind, obwohl der Schweregrad des Schadens hoch sein kann. Vergleichen Sie beispielsweise folgende Sätze:
- Der Roboter hat mich geboxt.
- Der Roboter hat mich in Stücke geschnitten.
Der erste Satz kann eine höhere Wahrscheinlichkeit für unsichere Ergebnisse verursachen, aber Sie können den zweiten Satz in Bezug auf Gewalt einen höheren Schweregrad zuweisen. Daher ist es wichtig, dass Sie Tests sorgfältig durchführen und überlegen, welches Maß an Sicherheitsblockaden zur Unterstützung Ihrer wichtigsten Anwendungsfälle erforderlich ist, während gleichzeitig der Schaden für Endnutzer minimiert wird.
Sicherheitsfilterung pro Anfrage
Sie können die Sicherheitseinstellungen für jede Anfrage an die API anpassen. Wenn Sie eine Anfrage senden, wird der Inhalt analysiert und erhält eine Sicherheitsbewertung. Die Sicherheitsbewertung umfasst sowohl die jeweilige Kategorie als auch die Wahrscheinlichkeit einer Klassifizierung als schädlich. Wenn der Inhalt beispielsweise blockiert wurde, weil die Wahrscheinlichkeit, dass er in der Kategorie der Belästigung unsicher ist, hoch ist, hat die zurückgegebene Sicherheitsbewertung die Kategorie HARASSMENT und die Wahrscheinlichkeit für schädliche Inhalte ist auf HIGH gesetzt.
Aufgrund der inhärenten Sicherheit des Modells sind zusätzliche Filter standardmäßig deaktiviert. Wenn Sie sie aktivieren, können Sie das System so konfigurieren, dass Inhalte basierend auf der Wahrscheinlichkeit, dass sie unsicher sind, blockiert werden. Das Standardverhalten des Modells deckt die meisten Anwendungsfälle ab. Sie sollten diese Einstellungen also nur anpassen, wenn dies durchgehend für Ihre Anwendung erforderlich ist.
In der folgenden Tabelle werden die Blockierungseinstellungen beschrieben, die Sie für jede Kategorie anpassen können. Wenn Sie beispielsweise die Blockierungseinstellung für die Kategorie Hassrede auf Wenige blockieren setzen, werden alle Inhalte blockiert, die mit hoher Wahrscheinlichkeit Hassrede enthalten. Alles mit einer niedrigeren Wahrscheinlichkeit ist zulässig.
| Grenzwert (Google AI Studio) | Grenzwert (API) | Beschreibung |
|---|---|---|
| Aus | OFF |
Sicherheitsfilter deaktivieren |
| Keine blockieren | BLOCK_NONE |
Unabhängig von der Wahrscheinlichkeit unsicherer Inhalte immer anzeigen |
| Wenige blockieren | BLOCK_ONLY_HIGH |
Blockieren, wenn die Wahrscheinlichkeit für unsichere Inhalte hoch ist |
| Einige blockieren | BLOCK_MEDIUM_AND_ABOVE |
Blockieren, wenn die Wahrscheinlichkeit für unsichere Inhalte mittel oder hoch ist |
| Meiste blockieren | BLOCK_LOW_AND_ABOVE |
Blockieren, wenn die Wahrscheinlichkeit für unsichere Inhalte niedrig, mittel oder hoch ist |
| – | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
Der Grenzwert ist nicht angegeben, nach dem Standardschwellenwert blockieren |
Wenn der Grenzwert nicht festgelegt ist, ist der Standardgrenzwert für die Blockierung für Gemini 2.5- und 3-Modelle deaktiviert.
Sie können diese Einstellungen für jede Anfrage an den generativen Dienst festlegen.
Weitere Informationen finden Sie in der HarmBlockThreshold API
Referenz.
Sicherheitsfeedback
generateContent
gibt ein
GenerateContentResponse zurück, das
Sicherheitsfeedback enthält.
Prompt-Feedback ist in
promptFeedback enthalten. Wenn promptFeedback.blockReason festgelegt ist, wurde der Inhalt des Prompts blockiert.
Feedback zu Antwortkandidaten ist in
Candidate.finishReason und
Candidate.safetyRatings enthalten. Wenn Antwortinhalte blockiert wurden und finishReason den Wert SAFETY hat, können Sie in safetyRatings weitere Details finden. Die blockierten Inhalte werden nicht zurückgegeben.
Sicherheitseinstellungen anpassen
In diesem Abschnitt wird beschrieben, wie Sie die Sicherheitseinstellungen sowohl in Google AI Studio als auch in Ihrem Code anpassen.
Google AI Studio
Sie können die Sicherheitseinstellungen in Google AI Studio anpassen.
Klicken Sie im Bereich Laufeinstellungen unter Erweiterte Einstellungen auf Sicherheitseinstellungen , um das modale Fenster Sicherheitseinstellungen ausführen zu öffnen. In diesem Fenster können Sie mit den Schiebereglern die Stufe der Inhaltsfilterung für jede Sicherheitskategorie anpassen:
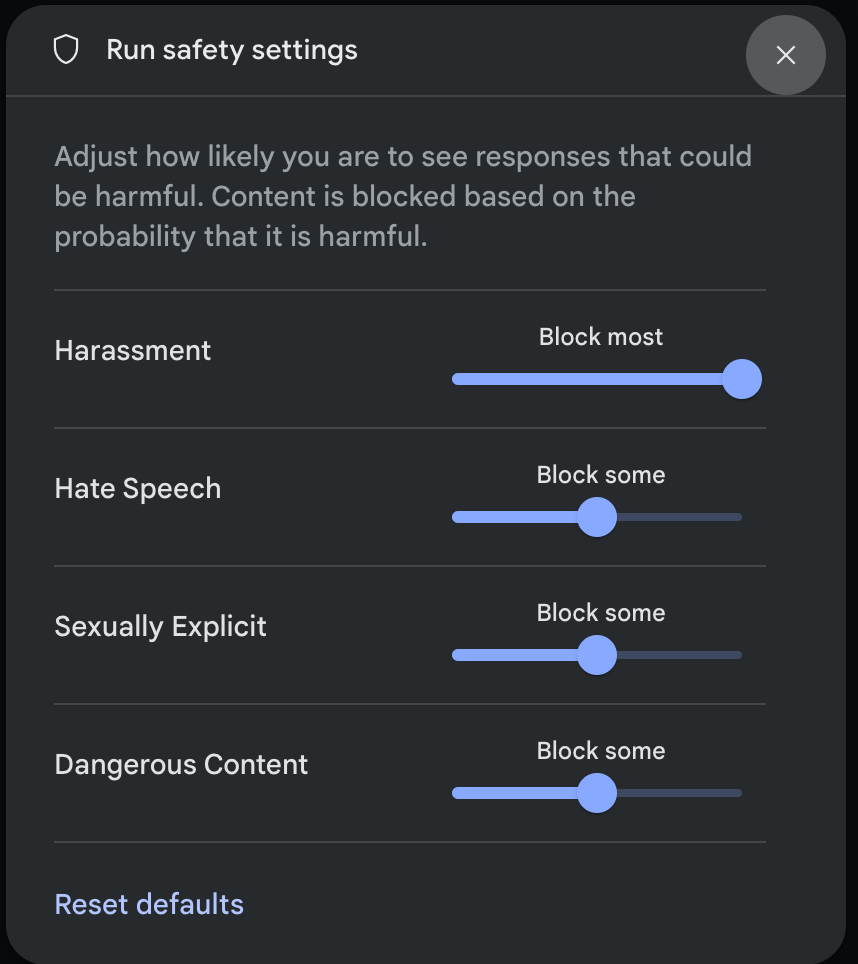
Wenn Sie eine Anfrage senden (z. B. indem Sie dem Modell eine Frage stellen), wird die Inhalt blockiert angezeigt, wenn der Inhalt der Anfrage blockiert wird. Wenn Sie weitere Details sehen möchten, bewegen Sie den Mauszeiger auf den Text Inhalt blockiert. Dort werden die Kategorie und die Wahrscheinlichkeit der Klassifizierung als schädlich angezeigt.
Codebeispiele
Das folgende Code-Snippet zeigt, wie Sie die Sicherheitseinstellungen in Ihrem GenerateContent-Aufruf festlegen. Dadurch wird der Grenzwert für die Kategorie Hassrede (HARM_CATEGORY_HATE_SPEECH) festgelegt. Wenn Sie diese Kategorie auf BLOCK_LOW_AND_ABOVE setzen, werden alle Inhalte blockiert, die mit niedriger oder höherer Wahrscheinlichkeit Hassrede enthalten. Informationen zu den Grenzwert-Einstellungen finden Sie unter Sicherheitsfilterung
pro Anfrage.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Ok
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
Nächste Schritte
- Weitere Informationen zur vollständigen API finden Sie in der API-Referenz.
- In den Sicherheitsrichtlinien finden Sie allgemeine Informationen zu Sicherheits aspekten bei der Entwicklung mit LLMs.
- Weitere Informationen zur Bewertung von Wahrscheinlichkeit und Schweregrad finden Sie im Blog des Jigsaw Teams.
- Weitere Informationen zu den Produkten, die zu Sicherheitslösungen beitragen, z. B. die Perspective API. * Mit diesen Sicherheitseinstellungen können Sie einen Klassifikator für schädliche Inhalte erstellen. Ein Beispiel für die Klassifizierung finden Sie hier, um loszulegen.