
मशीन लर्निंग (एमएल) मॉडल को चलाने के लिए, ग्राफ़िक प्रोसेसिंग यूनिट (जीपीयू) का इस्तेमाल करना आपके मॉडल की परफ़ॉर्मेंस और उपयोगकर्ता अनुभव को बेहतर बना सकता है मशीन लर्निंग का इस्तेमाल करने की सुविधा वाले ऐप्लिकेशन की सूची में शामिल करता है. iOS डिवाइसों पर, इनकी मदद से इसका इस्तेमाल करके आपके मॉडल को जीपीयू से तेज़ी से एक्ज़ीक्यूट किया जाता है किसी दूसरे व्यक्ति को ईमेल भेजना. डेलिगेट, इनके लिए हार्डवेयर ड्राइवर के तौर पर काम करते हैं LiteRT की मदद से, जीपीयू प्रोसेसर पर अपने मॉडल के कोड को चलाया जा सकता है.
इस पेज में LiteRT मॉडल के लिए जीपीयू से तेज़ी लाने की सुविधा चालू करने का तरीका बताया गया है iOS ऐप्लिकेशन. LiteRT के लिए, जीपीयू डेलिगेट का इस्तेमाल करने के बारे में ज़्यादा जानकारी पाने के लिए, सबसे सही तरीकों और बेहतर तकनीकों के बारे में जानने के लिए, GPU प्रतिनिधि पेज पर जाकर सबमिट करते हैं.
अनुवादक एपीआई के साथ जीपीयू का इस्तेमाल करें
LiteRT अनुवादक API सामान्य मशीन लर्निंग ऐप्लिकेशन बनाने के लिए खास एपीआई. नीचे दिए गए निर्देश किसी iOS ऐप्लिकेशन में जीपीयू से जुड़ी सहायता जोड़ने में आपकी मदद करते हैं. यह गाइड मान लेता है कि आपके पास पहले से ही ऐसा iOS ऐप्लिकेशन है जो एमएल मॉडल को एक्ज़ीक्यूट कर सकता है LiteRT के साथ काम करता है.
जीपीयू से जुड़ी सहायता शामिल करने के लिए, Podfile में बदलाव करें
LiteRT 2.3.0 रिलीज़ और इसके बाद के वर्शन में, जीपीयू डेलिगेट शामिल नहीं है
पॉड से, बाइनरी साइज़ को कम करें. आप
TensorFlowLiteSwift पॉड के लिए सब-स्पेक्ट:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
या
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
अगर आप चाहें, तो TensorFlowLiteObjC या TensorFlowLiteC का भी इस्तेमाल किया जा सकता है
Objective-C, जो 2.4.0 और उसके बाद वाले वर्शन या C API के लिए उपलब्ध है.
शुरू करने के लिए, जीपीयू डेलिगेट का इस्तेमाल करें
LiteRT इंटरप्रेटर की मदद से, जीपीयू डेलिगेट का इस्तेमाल किया जा सकता है कई प्रोग्रामिंग के साथ एपीआई भाषाएं. Swift और Objective-C का सुझाव दिया जाता है, लेकिन C++ और सी॰ अगर आप LiteRT के पहले वाले वर्शन का इस्तेमाल कर रहे हैं, तो C का इस्तेमाल करना ज़रूरी है 2.4 से भी कम है. नीचे दिए गए कोड उदाहरणों में, हर एक ईमेल पते के लिए, डेलिगेट के ऐक्सेस का इस्तेमाल करने का तरीका बताया गया है शामिल हैं.
Swift
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objective-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (2.4.0 से पहले)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
जीपीयू एपीआई की भाषा के इस्तेमाल से जुड़े नोट
- LiteRT के 2.4.0 से पहले के वर्शन, सिर्फ़ इन कामों के लिए C API का इस्तेमाल कर सकते हैं Objective-C.
- C++ API सिर्फ़ तब उपलब्ध होता है, जब बेज़ल का इस्तेमाल किया जा रहा हो या TensorFlow बनाया गया हो बस लाइट वर्शन देखें. CocoaPods के साथ C++ API का इस्तेमाल नहीं किया जा सकता.
- C++ के साथ जीपीयू डेलिगेट के साथ LiteRT का इस्तेमाल करते समय, जीपीयू पाएं
TFLGpuDelegateCreate()फ़ंक्शन से डेलिगेट करें और फिर उसे पास करें कॉल करने के बजाय,Interpreter::ModifyGraphWithDelegate()का इस्तेमाल करेंInterpreter::AllocateTensors().
रिलीज़ मोड की मदद से बिल्ड और टेस्ट करें
अपने हिसाब से मेटल एपीआई ऐक्सेलरेटर सेटिंग वाले रिलीज़ बिल्ड का इस्तेमाल करें इससे परफ़ॉर्मेंस बेहतर होती है और फ़ाइनल टेस्टिंग हो जाती है. इस सेक्शन में बताया गया है कि मेटल ऐक्सेलरेशन के लिए, रिलीज़ बिल्ड और कॉन्फ़िगर करने की सेटिंग चालू करनी होगी.
रिलीज़ बिल्ड में बदलने के लिए:
- बिल्ड सेटिंग में बदलाव करने के लिए, प्रॉडक्ट > स्कीम > स्कीम में बदलाव करें... फिर Run चुनें.
- जानकारी टैब पर, बिल्ड कॉन्फ़िगरेशन को रिलीज़ में बदलें और
डीबग की जा सकने वाली कॉपी से सही का निशान हटाएं.
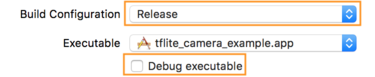
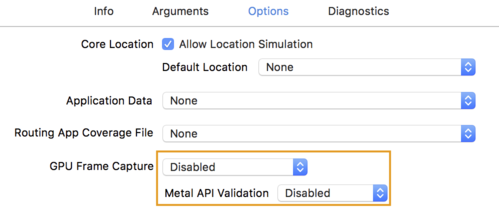
- विकल्प टैब पर क्लिक करें और जीपीयू फ़्रेम कैप्चर को बंद है में बदलें
और Metal API की पुष्टि से बंद कर दिया गया है.
- पक्का करें कि आपने 64-बिट आर्किटेक्चर पर 'सिर्फ़ रिलीज़ करने के लिए बिल्ड' चुना है. ज़ोन में है
प्रोजेक्ट नेविगेटर > tflite_camera_example > प्रोजेक्ट > your_project_name >
बिल्ड की सेटिंग सिर्फ़ ऐक्टिव आर्किटेक्चर बनाएं > इसके लिए, रिलीज़ को रिलीज़ करें
हां पर टैप करें.

जीपीयू के लिए बेहतर सहायता
इस सेक्शन में, iOS के लिए जीपीयू डेलिगेट के बेहतर इस्तेमाल के बारे में बताया गया है. इसमें, ये शामिल हैं डेलिगेट के विकल्प, इनपुट और आउटपुट बफ़र, और क्वांटाइज़्ड मॉडल का इस्तेमाल.
iOS के लिए विकल्प सौंपें
जीपीयू डेलिगेट का कंस्ट्रक्टर, Swift में struct विकल्पों को स्वीकार करता है
एपीआई,
Objective-C
एपीआई,
और C
API.
nullptr (C API) या कुछ भी (Objective-C और Swift API) पास नहीं कर रहे हैं
शुरू करने वाला डिफ़ॉल्ट विकल्प सेट करता है (जो बुनियादी उपयोग में दिखाए जाते हैं)
उदाहरण ऊपर दिया गया है).
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objective-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
C++ API का इस्तेमाल करके इनपुट/आउटपुट बफ़र
जीपीयू पर कंप्यूटेशन के लिए ज़रूरी है कि जीपीयू में डेटा उपलब्ध हो. यह ज़रूरत का मतलब अक्सर होता है. इसका मतलब है कि आपको मेमोरी कॉपी करनी होगी. आपको अपने आपका डेटा, सीपीयू/जीपीयू की मेमोरी की सीमा को पार कर जाता है. ऐसा इसलिए है, क्योंकि समय की बचत होती है. आम तौर पर, ऐसी क्रॉसिंग होना ज़रूरी है. हालांकि, कुछ मामलों में खास मामलों को छोड़ता है, तो इनमें से किसी एक को छोड़ा जा सकता है.
अगर नेटवर्क का इनपुट, जीपीयू मेमोरी में पहले से लोड की गई इमेज है (इसके लिए उदाहरण के लिए, जीपीयू टेक्सचर, जिसमें कैमरा फ़ीड है) यह जीपीयू मेमोरी में बना रह सकता है वे सीपीयू की मेमोरी का इस्तेमाल भी नहीं कर सकते. इसी तरह, अगर नेटवर्क का आउटपुट रेंडर की जा सकने वाली इमेज का फ़ॉर्म, जैसे कि इमेज की स्टाइल ट्रांसफ़र करें कार्रवाई, आप परिणाम को सीधे स्क्रीन पर दिखा सकते हैं.
सबसे अच्छी परफ़ॉर्मेंस पाने के लिए, LiteRT की मदद से उपयोगकर्ता ये काम कर पाते हैं TensorFlow के हार्डवेयर बफ़र में मौजूद कॉन्टेंट को सीधे पढ़ें और उसमें लिखें और उसे बायपास करें ऐसी मेमोरी कॉपी जिन्हें सेव नहीं किया जा सकता.
मान लें कि इमेज इनपुट जीपीयू मेमोरी में है, तो आपको पहले इसे
मेटल के लिए MTLBuffer ऑब्जेक्ट. आप TfLiteTensor को
उपयोगकर्ता ने MTLBuffer को TFLGpuDelegateBindMetalBufferToTensor() के साथ तैयार किया है
फ़ंक्शन का इस्तेमाल करना होगा. ध्यान दें कि इस फ़ंक्शन को बाद में कॉल किया जाना चाहिए
Interpreter::ModifyGraphWithDelegate(). इसके अलावा, अनुमान से यह पता चलता है कि
डिफ़ॉल्ट रूप से, जीपीयू मेमोरी से सीपीयू मेमोरी में कॉपी किया जाता है. इस सेटिंग को बंद किया जा सकता है
के दौरान Interpreter::SetAllowBufferHandleOutput(true) को कॉल करके
शुरू करना.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
डिफ़ॉल्ट ऐक्शन बंद होने के बाद, जीपीयू से अनुमान के आउटपुट को कॉपी करें
मेमोरी से CPU मेमोरी का उपयोग करने के लिए
हर आउटपुट टेंसर के लिए Interpreter::EnsureTensorDataIsReadable(). यह
यह तरीका क्वांटाइज़्ड मॉडल के लिए भी काम करता है. हालांकि, आपको अब भी
float32 डेटा वाला फ़्लोट32 साइज़ का बफ़र, क्योंकि बफ़र
आंतरिक डी-क्वांटाइज़ किया गया बफ़र.
क्वांटाइज़्ड मॉडल
iOS जीपीयू डेलिगेट लाइब्रेरी डिफ़ॉल्ट रूप से, क्वांट किए गए मॉडल के साथ काम करती हैं. आपको ये काम नहीं करने चाहिए जीपीयू डेलिगेट के साथ क्वांटाइज़्ड मॉडल का इस्तेमाल करने के लिए, कोड में कोई बदलाव करना होगा. कॉन्टेंट बनाने नीचे दिए गए सेक्शन में, टेस्ट के लिए क्वांटाइज़्ड सपोर्ट को बंद करने का तरीका बताया गया है या एक्सपेरिमेंट के तौर पर उपलब्ध कराया गया था.
क्वांटाइज़्ड मॉडल के साथ काम करने की सुविधा बंद करें
इस कोड में, क्वांटाइज़ किए गए मॉडल के लिए सहायता को बंद करने का तरीका बताया गया है.
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
जीपीयू ऐक्सेलरेशन के साथ क्वांटाइज़्ड मॉडल चलाने के बारे में ज़्यादा जानकारी के लिए, देखें GPU डेलिगेट की खास जानकारी.